STVG-R1: Incentivizing Instance-Level Reasoning and Grounding in Videos via Reinforcement Learning
作者: Xiaowen Zhang, Zhi Gao, Licheng Jiao, Lingling Li, Qing Li
分类: cs.CV
发布日期: 2026-02-12
💡 一句话要点
提出STVG-R1,通过强化学习激励视频实例级推理和定位,解决视觉-语言模型中的幻觉问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 时空视频定位 视觉-语言模型 强化学习 视觉提示 实例级识别
📋 核心要点
- 现有视觉-语言模型在时空视频定位等任务中,由于文本描述和视觉坐标错位,容易产生幻觉,影响定位精度。
- 论文提出视觉提示范式,将每帧坐标预测转化为实例级识别问题,并使用时间一致的ID作为视觉提示,避免跨模态对齐。
- 引入STVG-R1强化学习框架,通过任务驱动的奖励优化时间准确性、空间一致性和结构格式,在多个基准测试上取得SOTA。
📝 摘要(中文)
在视觉-语言模型(VLMs)中,文本描述和视觉坐标之间的错位经常导致幻觉。在时空视频定位(STVG)等密集预测任务中,这个问题尤其严重。以往的方法通常侧重于增强视觉-文本对齐或附加辅助解码器。然而,这些策略不可避免地引入额外的可训练模块,导致显著的标注成本和计算开销。本文提出了一种新颖的视觉提示范式,避免了跨模态对齐坐标的难题。具体来说,通过为每个对象分配一个唯一且时间上一致的ID,将每帧坐标预测重新定义为一个紧凑的实例级识别问题。这些ID作为视觉提示嵌入到视频中,为VLMs提供显式且可解释的输入。此外,我们引入了STVG-R1,这是第一个用于STVG的强化学习框架,它采用任务驱动的奖励来联合优化时间准确性、空间一致性和结构格式正则化。在六个基准测试上的大量实验证明了我们方法的有效性。STVG-R1在HCSTVG-v2基准测试上的m_IoU超过了基线Qwen2.5-VL-7B 20.9%,建立了新的SOTA。令人惊讶的是,STVG-R1还表现出对多对象指代视频对象分割任务的强大零样本泛化能力,在MeViS上实现了SOTA 47.3%的J&F。
🔬 方法详解
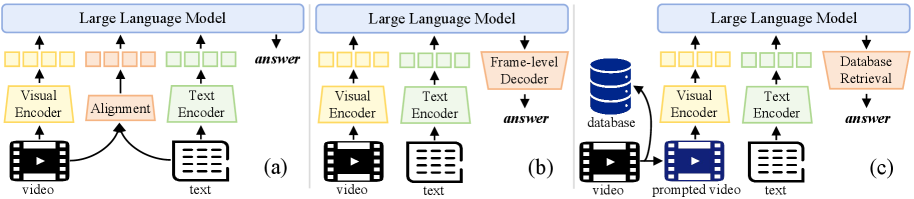
问题定义:论文旨在解决时空视频定位(STVG)任务中,视觉-语言模型因文本描述与视觉坐标错位而产生的幻觉问题。现有方法通常依赖于增强视觉-文本对齐或添加辅助解码器,但这些方法引入了额外的可训练模块,增加了标注成本和计算开销。
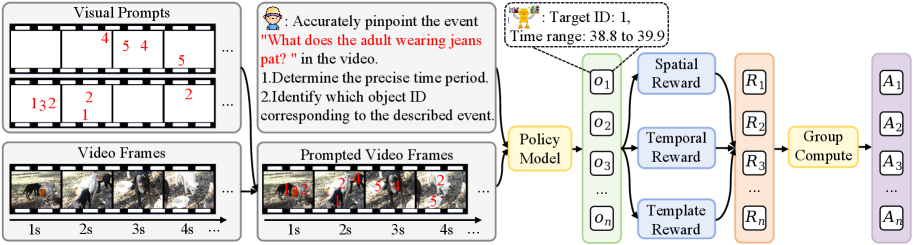
核心思路:论文的核心思路是将每帧的坐标预测问题转化为一个实例级别的识别问题。通过为视频中的每个对象分配一个唯一且时间上一致的ID,并将这些ID作为视觉提示嵌入到视频中,从而为视觉-语言模型提供更明确和可解释的输入,避免了直接对齐坐标的困难。
技术框架:STVG-R1的整体框架包含视觉提示生成模块和强化学习优化模块。首先,为视频中的每个对象生成唯一的ID,并将这些ID嵌入到视频帧中作为视觉提示。然后,使用视觉-语言模型处理带有视觉提示的视频,并使用强化学习框架优化模型的性能。强化学习框架使用任务驱动的奖励函数,该奖励函数考虑了时间准确性、空间一致性和结构格式正则化。
关键创新:论文的关键创新在于引入了视觉提示范式和强化学习优化框架。视觉提示范式通过将坐标预测转化为实例识别,简化了跨模态对齐的难度。强化学习框架通过任务驱动的奖励函数,能够更有效地优化模型的性能,使其更好地适应STVG任务。
关键设计:视觉提示的设计是关键。每个对象被分配一个唯一且时间上一致的ID,这个ID被嵌入到视频帧中,作为视觉-语言模型的输入。强化学习的奖励函数设计也至关重要,它需要平衡时间准确性、空间一致性和结构格式正则化。具体的奖励函数形式和参数设置在论文中有详细描述,但此处未知。
🖼️ 关键图片

📊 实验亮点
STVG-R1在HCSTVG-v2基准测试上,m_IoU指标超越了基线Qwen2.5-VL-7B 20.9%,取得了新的SOTA。此外,STVG-R1在MeViS多对象指代视频对象分割任务上,实现了47.3%的J&F,展现了强大的零样本泛化能力。
🎯 应用场景
该研究成果可应用于视频内容理解、智能监控、自动驾驶等领域。通过提高视觉-语言模型在视频定位任务中的准确性和鲁棒性,可以实现更精确的目标跟踪、行为识别和场景理解,从而提升相关应用的智能化水平。
📄 摘要(原文)
In vision-language models (VLMs), misalignment between textual descriptions and visual coordinates often induces hallucinations. This issue becomes particularly severe in dense prediction tasks such as spatial-temporal video grounding (STVG). Prior approaches typically focus on enhancing visual-textual alignment or attaching auxiliary decoders. However, these strategies inevitably introduce additional trainable modules, leading to significant annotation costs and computational overhead. In this work, we propose a novel visual prompting paradigm that avoids the difficult problem of aligning coordinates across modalities. Specifically, we reformulate per-frame coordinate prediction as a compact instance-level identification problem by assigning each object a unique, temporally consistent ID. These IDs are embedded into the video as visual prompts, providing explicit and interpretable inputs to the VLMs. Furthermore, we introduce STVG-R1, the first reinforcement learning framework for STVG, which employs a task-driven reward to jointly optimize temporal accuracy, spatial consistency, and structural format regularization. Extensive experiments on six benchmarks demonstrate the effectiveness of our approach. STVG-R1 surpasses the baseline Qwen2.5-VL-7B by a remarkable margin of 20.9% on m_IoU on the HCSTVG-v2 benchmark, establishing a new state of the art (SOTA). Surprisingly, STVG-R1 also exhibits strong zero-shot generalization to multi-object referring video object segmentation tasks, achieving a SOTA 47.3% J&F on MeViS.