RI-Mamba: Rotation-Invariant Mamba for Robust Text-to-Shape Retrieval
作者: Khanh Nguyen, Dasith de Silva Edirimuni, Ghulam Mubashar Hassan, Ajmal Mian
分类: cs.CV
发布日期: 2026-02-12
🔗 代码/项目: GITHUB
💡 一句话要点
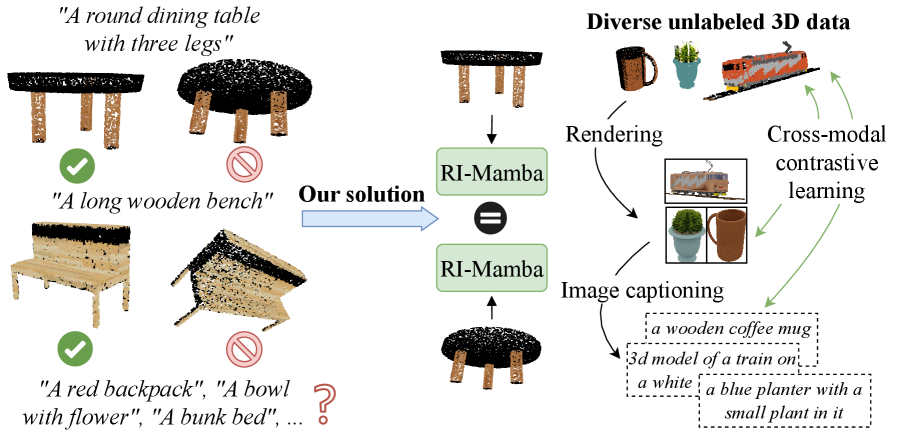
提出RI-Mamba,解决任意方向下大规模三维形状检索难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 三维形状检索 旋转不变性 状态空间模型 点云处理 跨模态学习
📋 核心要点
- 现有文本到形状检索方法依赖规范姿态和少量类别,限制了其在实际场景中的应用。
- RI-Mamba通过定义全局和局部参考系解耦姿态和几何,并利用Hilbert排序构建旋转不变的token序列。
- RI-Mamba在OmniObject3D基准测试中,超过200个对象类别上实现了最先进的检索性能。
📝 摘要(中文)
本文提出RI-Mamba,一种用于点云的首个旋转不变状态空间模型,旨在解决现有文本到形状检索方法对规范姿态的依赖以及对少量对象类别的支持的局限性。RI-Mamba定义了全局和局部参考系,以解耦姿态和几何形状,并使用Hilbert排序构建具有有意义几何结构的token序列,同时保持旋转不变性。此外,还引入了一种新颖的策略来计算方向嵌入,并通过特征线性调制重新整合它们,从而有效地恢复空间上下文并增强模型表达能力。该策略与状态空间模型固有兼容,并以线性时间运行。为了扩大检索规模,采用了具有自动三元组生成的跨模态对比学习,从而可以在没有手动注释的情况下对各种数据集进行训练。大量实验表明,RI-Mamba具有卓越的表征能力和鲁棒性,在OmniObject3D基准测试中,在任意方向下超过200个对象类别上实现了最先进的性能。
🔬 方法详解
问题定义:现有文本到形状检索方法通常需要3D模型具有规范的姿态,并且只能处理有限的对象类别。这限制了它们在实际应用中的有效性,因为真实世界中的3D对象可能具有任意方向和属于各种不同的类别。因此,需要一种能够处理任意方向和大规模对象类别的鲁棒的文本到形状检索方法。
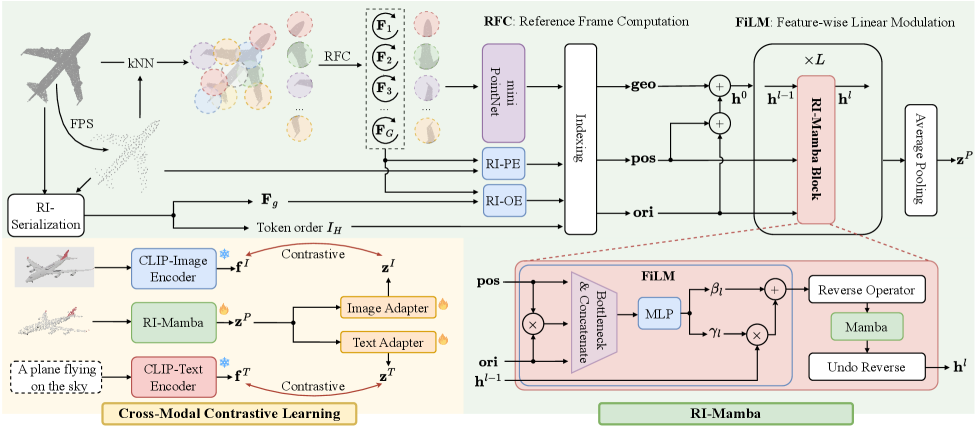
核心思路:RI-Mamba的核心思路是构建一个旋转不变的状态空间模型,该模型能够解耦3D对象的姿态和几何形状。通过定义全局和局部参考系,模型可以学习到与对象方向无关的几何特征。同时,利用Hilbert排序构建具有几何意义的token序列,进一步增强了模型的旋转不变性。
技术框架:RI-Mamba的整体框架包括以下几个主要模块:1) 点云预处理:将输入的点云数据转换为模型可以处理的格式。2) 参考系定义:定义全局和局部参考系,用于解耦姿态和几何形状。3) Hilbert排序:使用Hilbert曲线对点云进行排序,构建具有几何意义的token序列。4) 状态空间模型:使用Mamba作为核心模型,学习点云的几何特征。5) 方向嵌入:计算方向嵌入,用于恢复空间上下文信息。6) 特征线性调制:通过特征线性调制将方向嵌入整合到状态空间模型中。7) 跨模态对比学习:使用跨模态对比学习训练模型,使其能够将文本描述与3D形状关联起来。
关键创新:RI-Mamba的关键创新在于以下几个方面:1) 提出了一种旋转不变的状态空间模型,能够处理任意方向的3D对象。2) 引入了全局和局部参考系,用于解耦姿态和几何形状。3) 利用Hilbert排序构建具有几何意义的token序列。4) 提出了一种新颖的方向嵌入方法,用于恢复空间上下文信息。
关键设计:RI-Mamba的关键设计包括:1) 使用Mamba作为核心的状态空间模型,利用其高效的序列建模能力。2) 使用Hilbert曲线进行排序,确保相邻token在空间上具有相关性。3) 通过特征线性调制将方向嵌入整合到状态空间模型中,有效地恢复空间上下文信息。4) 采用跨模态对比学习,使用自动三元组生成,从而可以在没有手动注释的情况下对各种数据集进行训练。
🖼️ 关键图片
📊 实验亮点
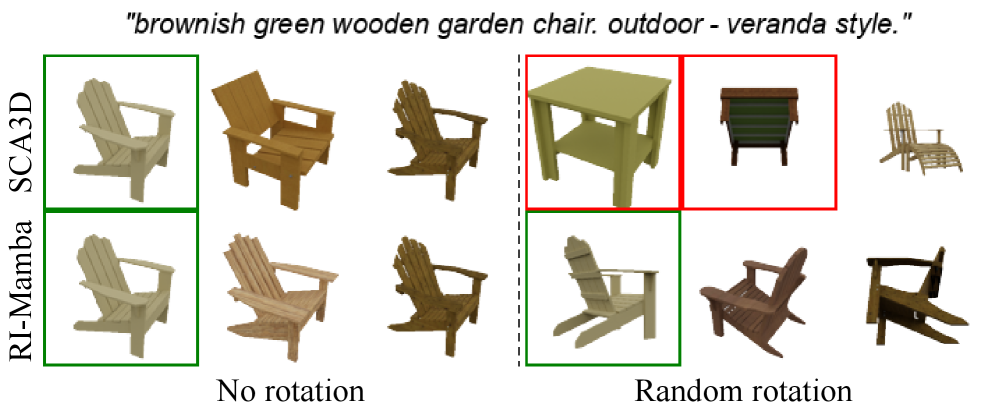
RI-Mamba在OmniObject3D基准测试中取得了显著的性能提升,在超过200个对象类别上实现了最先进的文本到形状检索性能。实验结果表明,RI-Mamba具有强大的表征能力和鲁棒性,能够有效地处理任意方向的3D对象。与现有方法相比,RI-Mamba在检索准确率方面有显著提升。
🎯 应用场景
RI-Mamba在虚拟现实、游戏开发、计算机辅助设计等领域具有广泛的应用前景。它可以用于在大型3D模型库中进行快速、准确的检索,帮助用户找到所需的3D资产。此外,RI-Mamba还可以用于3D模型的自动生成和编辑,以及机器人导航和场景理解等任务。该研究有望推动三维内容创作和应用的发展。
📄 摘要(原文)
3D assets have rapidly expanded in quantity and diversity due to the growing popularity of virtual reality and gaming. As a result, text-to-shape retrieval has become essential in facilitating intuitive search within large repositories. However, existing methods require canonical poses and support few object categories, limiting their real-world applicability where objects can belong to diverse classes and appear in random orientations. To address this challenge, we propose RI-Mamba, the first rotation-invariant state-space model for point clouds. RI-Mamba defines global and local reference frames to disentangle pose from geometry and uses Hilbert sorting to construct token sequences with meaningful geometric structure while maintaining rotation invariance. We further introduce a novel strategy to compute orientational embeddings and reintegrate them via feature-wise linear modulation, effectively recovering spatial context and enhancing model expressiveness. Our strategy is inherently compatible with state-space models and operates in linear time. To scale up retrieval, we adopt cross-modal contrastive learning with automated triplet generation, allowing training on diverse datasets without manual annotation. Extensive experiments demonstrate RI-Mamba's superior representational capacity and robustness, achieving state-of-the-art performance on the OmniObject3D benchmark across more than 200 object categories under arbitrary orientations. Our code will be made available at https://github.com/ndkhanh360/RI-Mamba.git.