Egocentric Gaze Estimation via Neck-Mounted Camera
作者: Haoyu Huang, Yoichi Sato
分类: cs.CV
发布日期: 2026-02-12
💡 一句话要点
提出颈部相机注视点估计任务,并构建数据集与评估Transformer模型。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 注视点估计 颈部相机 Transformer 多视角学习 辅助任务
📋 核心要点
- 现有以自我为中心的注视点估计主要集中于头戴式相机,忽略了其他视角的潜力,限制了应用场景。
- 论文提出颈部相机注视点估计任务,并构建数据集,利用Transformer模型进行评估,探索新的视角。
- 实验表明,引入注视点越界分类任务能提升性能,但多视角协同学习未见明显效果,为后续研究提供参考。
📝 摘要(中文)
本文提出了颈部相机视角下的注视点估计这一新任务,旨在从颈部安装的相机视角估计用户的注视方向。现有的以自我为中心的注视点估计工作主要集中在头戴式相机上,而其他视角的研究相对较少。为了填补这一空白,我们收集了首个用于此任务的数据集,其中包含8名参与者在日常活动中收集的约4小时视频。我们在新数据集上评估了一个基于Transformer的注视点估计模型GLC,并提出了两个扩展:一个辅助的注视点越界分类任务和一个多视角协同学习方法,该方法使用几何感知的辅助损失联合训练头部视角和颈部视角模型。实验结果表明,结合注视点越界分类可以提高标准微调的性能,而协同学习方法没有产生增益。我们进一步分析了这些结果,并讨论了颈部相机注视点估计的意义。
🔬 方法详解
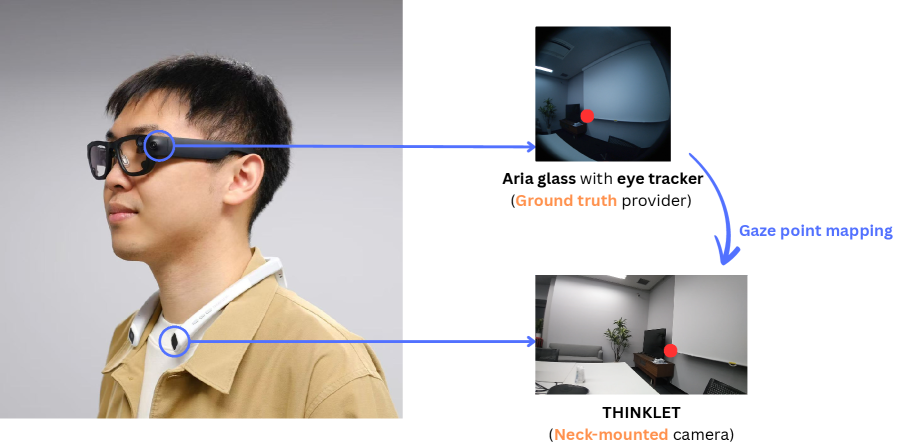
问题定义:论文旨在解决颈部安装相机视角下的注视点估计问题。现有方法主要集中在头戴式相机,忽略了颈部相机视角的潜力。颈部相机视角与头部相机视角存在差异,直接应用现有方法可能效果不佳,缺乏针对性数据集。
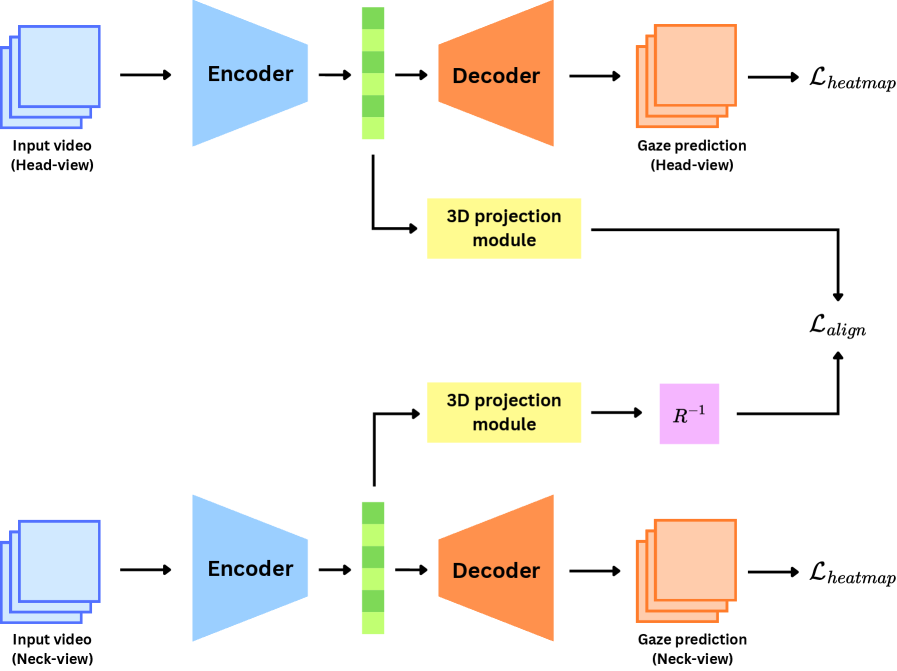
核心思路:核心思路是利用Transformer模型GLC,并结合辅助任务和多视角协同学习来提升颈部相机注视点估计的性能。通过辅助任务判断注视点是否超出视野范围,提供额外信息;通过多视角协同学习,利用头部相机视角的信息来辅助颈部相机视角的学习。
技术框架:整体框架包括数据采集、模型训练和评估三个阶段。首先,构建包含颈部相机视频和对应注视点标签的数据集。然后,使用Transformer模型GLC作为基础模型,并添加辅助的注视点越界分类任务。最后,设计多视角协同学习策略,联合训练头部相机和颈部相机模型,并使用几何感知的辅助损失进行约束。
关键创新:主要创新点在于提出了颈部相机注视点估计这一新任务,并构建了相应的数据集。此外,还提出了辅助的注视点越界分类任务,以及多视角协同学习方法,试图利用不同视角的信息来提升性能。尽管多视角协同学习效果不佳,但其思路具有一定的参考价值。
关键设计:辅助的注视点越界分类任务采用二分类交叉熵损失函数。多视角协同学习中,几何感知的辅助损失基于不同视角之间的几何关系进行设计,具体形式未知(论文未明确说明)。Transformer模型GLC的具体参数设置未知(论文未明确说明)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在颈部相机注视点估计任务中,引入注视点越界分类任务可以提高标准微调的性能。然而,多视角协同学习方法并没有带来明显的性能提升,这表明直接利用头部相机视角的信息可能并不适用于颈部相机视角,需要更精巧的设计。具体的性能提升幅度未知(论文未提供具体数值)。
🎯 应用场景
颈部相机注视点估计在人机交互、可穿戴设备、辅助技术等领域具有潜在应用价值。例如,可以用于智能助手中,通过用户的注视方向来理解用户的意图,从而提供更精准的服务。此外,还可以应用于运动分析、安全监控等领域,通过分析用户的注视行为来评估其状态。
📄 摘要(原文)
This paper introduces neck-mounted view gaze estimation, a new task that estimates user gaze from the neck-mounted camera perspective. Prior work on egocentric gaze estimation, which predicts device wearer's gaze location within the camera's field of view, mainly focuses on head-mounted cameras while alternative viewpoints remain underexplored. To bridge this gap, we collect the first dataset for this task, consisting of approximately 4 hours of video collected from 8 participants during everyday activities. We evaluate a transformer-based gaze estimation model, GLC, on the new dataset and propose two extensions: an auxiliary gaze out-of-bound classification task and a multi-view co-learning approach that jointly trains head-view and neck-view models using a geometry-aware auxiliary loss. Experimental results show that incorporating gaze out-of-bound classification improves performance over standard fine-tuning, while the co-learning approach does not yield gains. We further analyze these results and discuss implications for neck-mounted gaze estimation.