Clutt3R-Seg: Sparse-view 3D Instance Segmentation for Language-grounded Grasping in Cluttered Scenes
作者: Jeongho Noh, Tai Hyoung Rhee, Eunho Lee, Jeongyun Kim, Sunwoo Lee, Ayoung Kim
分类: cs.CV, cs.RO
发布日期: 2026-02-12
备注: Accepted to ICRA 2026. 9 pages, 8 figures
🔗 代码/项目: GITHUB
💡 一句话要点
Clutt3R-Seg:面向杂乱场景语言引导抓取的稀疏视角3D实例分割
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D实例分割 语言引导抓取 机器人操作 杂乱场景 层级实例树
📋 核心要点
- 现有3D实例分割方法在杂乱环境中面临遮挡、视角有限和噪声mask等挑战,导致性能下降。
- Clutt3R-Seg利用语义线索构建层级实例树,通过跨视角分组和条件替换抑制分割错误,提升实例分割的鲁棒性。
- 实验表明,Clutt3R-Seg在杂乱和稀疏视角场景中显著优于现有方法,在重度杂乱场景下AP@25提升超过2.2倍。
📝 摘要(中文)
本文提出Clutt3R-Seg,一个用于杂乱场景中语言引导机器人抓取的鲁棒3D实例分割的零样本pipeline。核心思想是引入语义线索的层级实例树。与试图优化噪声mask的现有方法不同,本文方法将它们作为信息线索:通过跨视角分组和条件替换,该树抑制了过分割和欠分割,从而产生视角一致的mask和鲁棒的3D实例。每个实例都富含开放词汇语义嵌入,从而能够从自然语言指令中准确选择目标。为了处理多阶段任务中的场景变化,本文进一步引入了一致性感知更新,该更新仅从交互后的单个图像中保留实例对应关系,从而无需重新扫描即可实现高效适应。Clutt3R-Seg在合成和真实世界数据集上进行了评估,并在真实机器人上进行了验证。在所有设置中,它始终优于杂乱和稀疏视角场景中的最先进基线。即使在最具挑战性的重度杂乱序列上,Clutt3R-Seg也能达到61.66的AP@25,比基线高出2.2倍以上,并且仅使用四个输入视角就超过了使用八个视角的MaskClustering 2倍以上。
🔬 方法详解
问题定义:论文旨在解决杂乱场景下,由于遮挡、视角限制和噪声mask导致的3D实例分割精度问题,尤其是在语言引导的机器人抓取任务中。现有方法通常依赖于优化噪声mask,但效果有限。
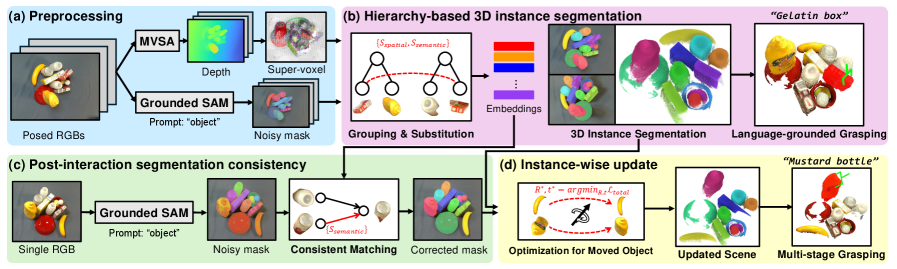
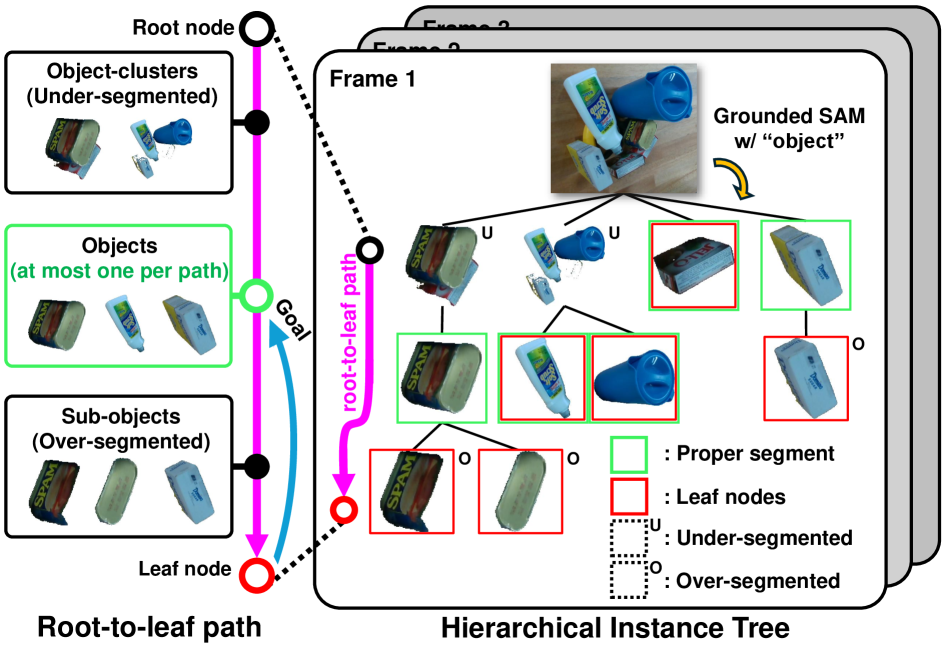
核心思路:核心思路是构建一个语义线索的层级实例树,将噪声mask视为有用的信息线索,通过跨视角分组和条件替换来抑制过分割和欠分割,从而获得视角一致且鲁棒的3D实例分割结果。
技术框架:Clutt3R-Seg的整体框架包含以下几个主要阶段:1) 多视角图像获取;2) 基于语义线索的层级实例树构建,包括跨视角分组和条件替换;3) 实例的语义嵌入,用于语言引导的目标选择;4) 一致性感知更新,用于处理交互后的场景变化。
关键创新:最重要的技术创新点在于利用层级实例树来处理噪声mask,而不是简单地优化它们。通过跨视角分组和条件替换,有效地抑制了分割错误,提高了实例分割的鲁棒性和视角一致性。此外,一致性感知更新允许模型在交互后仅使用单个图像进行快速适应。
关键设计:层级实例树的具体构建方式(例如,分组和替换的策略)、语义嵌入的选择(例如,使用预训练的语言模型)、以及一致性感知更新的实现细节(例如,如何建立实例对应关系)是关键的设计要素。论文中可能还涉及一些超参数的设置,例如分组的阈值、替换的条件等。
🖼️ 关键图片

📊 实验亮点
Clutt3R-Seg在合成和真实数据集上均表现出色。在最具挑战性的重度杂乱序列上,Clutt3R-Seg的AP@25达到了61.66,比现有基线高出2.2倍以上。更重要的是,仅使用四个输入视角,Clutt3R-Seg的性能就超过了使用八个视角的MaskClustering 2倍以上,这表明其在稀疏视角下的优越性。
🎯 应用场景
Clutt3R-Seg在机器人操作领域具有广泛的应用前景,尤其是在需要语言引导的复杂任务中。例如,它可以应用于家庭服务机器人,帮助它们根据自然语言指令抓取特定物体;也可以应用于工业自动化,提高机器人在杂乱环境中执行任务的效率和准确性。该研究的未来影响在于推动机器人更好地理解和操作真实世界。
📄 摘要(原文)
Reliable 3D instance segmentation is fundamental to language-grounded robotic manipulation. Its critical application lies in cluttered environments, where occlusions, limited viewpoints, and noisy masks degrade perception. To address these challenges, we present Clutt3R-Seg, a zero-shot pipeline for robust 3D instance segmentation for language-grounded grasping in cluttered scenes. Our key idea is to introduce a hierarchical instance tree of semantic cues. Unlike prior approaches that attempt to refine noisy masks, our method leverages them as informative cues: through cross-view grouping and conditional substitution, the tree suppresses over- and under-segmentation, yielding view-consistent masks and robust 3D instances. Each instance is enriched with open-vocabulary semantic embeddings, enabling accurate target selection from natural language instructions. To handle scene changes during multi-stage tasks, we further introduce a consistency-aware update that preserves instance correspondences from only a single post-interaction image, allowing efficient adaptation without rescanning. Clutt3R-Seg is evaluated on both synthetic and real-world datasets, and validated on a real robot. Across all settings, it consistently outperforms state-of-the-art baselines in cluttered and sparse-view scenarios. Even on the most challenging heavy-clutter sequences, Clutt3R-Seg achieves an AP@25 of 61.66, over 2.2x higher than baselines, and with only four input views it surpasses MaskClustering with eight views by more than 2x. The code is available at: https://github.com/jeonghonoh/clutt3r-seg.