ScalSelect: Scalable Training-Free Multimodal Data Selection for Efficient Visual Instruction Tuning
作者: Changti Wu, Jiahuai Mao, Yuzhuo Miao, Shijie Lian, Bin Yu, Xiaopeng Lin, Cong Huang, Lei Zhang, Kai Chen
分类: cs.CV, cs.AI
发布日期: 2026-02-12
备注: The code is available at \href{https://github.com/ChangtiWu/ScalSelect}{ScalSelect}
🔗 代码/项目: GITHUB
💡 一句话要点
提出ScalSelect以解决大规模多模态数据选择效率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉指令调优 多模态数据选择 高效训练 视觉语言模型 数据冗余 样本表示 重要性评分
📋 核心要点
- 现有多模态数据选择方法通常需要昂贵的训练或梯度计算,导致效率低下和计算成本高。
- ScalSelect通过提取视觉特征并识别样本表示的主子空间,实现了线性时间复杂度的无训练数据选择。
- 实验结果显示,ScalSelect在使用仅16%数据的情况下,达到了全数据集训练性能的97.5%以上,部分情况下甚至超越了全数据训练。
📝 摘要(中文)
大规模视觉指令调优(VIT)已成为提升视觉语言模型(VLM)在多模态任务中表现的关键范式。然而,训练大规模数据集计算成本高且效率低,数据冗余促使多模态数据选择的需求。现有数据选择方法通常需要昂贵的训练或梯度计算,而无训练的替代方案依赖于代理模型或数据集,限制了可扩展性和表示的保真度。本文提出ScalSelect,一种可扩展的无训练多模态数据选择方法,其样本数量的复杂度为线性,消除了对外部模型或辅助数据集的需求。ScalSelect通过提取目标VLM中指令令牌最关注的视觉特征来构建样本表示,捕捉与指令相关的信息,并识别出最佳近似全数据集表示主子空间的样本,从而实现可扩展的重要性评分。实验表明,ScalSelect在多个VLM、数据集和选择预算下,使用仅16%的数据实现了超过97.5%的全数据集训练性能,甚至在某些设置中超越了全数据训练。
🔬 方法详解
问题定义:本文旨在解决大规模视觉指令调优中的数据冗余问题,现有方法在数据选择上存在高计算成本和效率低下的痛点。
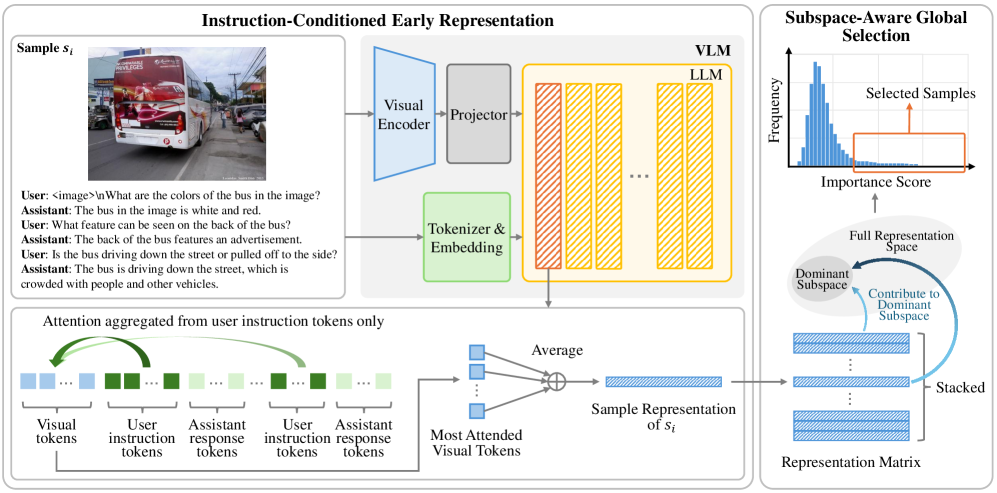
核心思路:ScalSelect的核心思路是通过提取与指令相关的视觉特征,构建样本表示,并通过近似主子空间来实现高效的数据选择,避免了传统方法的复杂性。
技术框架:ScalSelect的整体架构包括样本表示构建和重要性评分两个主要模块。首先提取视觉特征,然后识别与全数据集主子空间的近似样本。
关键创新:ScalSelect的关键创新在于其线性时间复杂度的无训练数据选择方法,消除了对外部模型或辅助数据集的依赖,与现有方法相比具有更高的可扩展性和表示保真度。
关键设计:在样本表示构建中,ScalSelect关注指令令牌最关注的视觉特征,确保捕捉到与指令相关的信息,重要性评分则通过样本表示的主子空间近似实现,避免了成对比较的复杂计算。
🖼️ 关键图片
📊 实验亮点
ScalSelect在多个视觉语言模型和数据集上进行了广泛实验,结果显示其在仅使用16%数据的情况下,达到了全数据集训练性能的97.5%以上,部分情况下甚至超越了全数据训练,展示了其优越的性能和效率。
🎯 应用场景
ScalSelect在多模态学习、视觉指令调优等领域具有广泛的应用潜力。其高效的数据选择方法能够显著降低训练成本,提高模型训练的效率,适用于大规模数据集的处理,未来可能推动更多智能应用的发展。
📄 摘要(原文)
Large-scale Visual Instruction Tuning (VIT) has become a key paradigm for advancing the performance of vision-language models (VLMs) across various multimodal tasks. However, training on the large-scale datasets is computationally expensive and inefficient due to redundancy in the data, which motivates the need for multimodal data selection to improve training efficiency. Existing data selection methods for VIT either require costly training or gradient computation. Training-free alternatives often depend on proxy models or datasets, instruction-agnostic representations, and pairwise similarity with quadratic complexity, limiting scalability and representation fidelity. In this work, we propose ScalSelect, a scalable training-free multimodal data selection method with linear-time complexity with respect to the number of samples, eliminating the need for external models or auxiliary datasets. ScalSelect first constructs sample representations by extracting visual features most attended by instruction tokens in the target VLM, capturing instruction-relevant information. It then identifies samples whose representations best approximate the dominant subspace of the full dataset representations, enabling scalable importance scoring without pairwise comparisons. Extensive experiments across multiple VLMs, datasets, and selection budgets demonstrate that ScalSelect achieves over 97.5% of the performance of training on the full dataset using only 16% of the data, and even outperforms full-data training in some settings. The code is available at \href{https://github.com/ChangtiWu/ScalSelect}{ScalSelect}.