LUVE : Latent-Cascaded Ultra-High-Resolution Video Generation with Dual Frequency Experts
作者: Chen Zhao, Jiawei Chen, Hongyu Li, Zhuoliang Kang, Shilin Lu, Xiaoming Wei, Kai Zhang, Jian Yang, Ying Tai
分类: cs.CV
发布日期: 2026-02-12
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
LUVE:基于双频专家和潜在级联的超高分辨率视频生成框架
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 超高分辨率 潜在空间 扩散模型 双频专家 运动建模 内容细化
📋 核心要点
- 超高分辨率视频生成面临运动建模、语义规划和细节合成的挑战,现有方法难以兼顾。
- LUVE框架通过潜在级联的方式,在潜在空间中进行分辨率提升,降低计算和内存开销。
- LUVE利用双频专家分别处理低频语义和高频细节,实验证明其生成质量和保真度更优。
📝 摘要(中文)
本文提出了一种名为LUVE的潜在级联超高分辨率(UHR)视频生成框架,该框架基于双频专家。由于运动建模、语义规划和细节合成的复杂性,UHR视频生成仍然是一个巨大的挑战。为了解决这些限制,LUVE采用了一个三阶段架构,包括用于运动一致潜在合成的低分辨率运动生成、直接在潜在空间中执行分辨率上采样的视频潜在上采样以减轻内存和计算开销,以及集成低频和高频专家的高分辨率内容细化,以共同增强语义连贯性和精细细节生成。大量实验表明,LUVE在UHR视频生成中实现了卓越的照片真实感和内容保真度,全面的消融研究进一步验证了每个组件的有效性。
🔬 方法详解
问题定义:超高分辨率视频生成旨在生成具有高分辨率和逼真细节的视频。现有方法通常面临三个主要痛点:一是运动建模困难,难以保证视频帧之间的运动一致性;二是语义规划复杂,难以生成具有连贯语义内容的视频;三是细节合成困难,难以生成逼真的高频细节。这些问题导致生成视频的质量和真实感不足。
核心思路:LUVE的核心思路是将视频生成过程分解为三个阶段,并在潜在空间中进行分辨率提升,从而降低计算复杂度。同时,利用双频专家分别处理低频语义信息和高频细节信息,从而提高生成视频的质量和真实感。这种分而治之的策略能够有效缓解超高分辨率视频生成中的各种挑战。
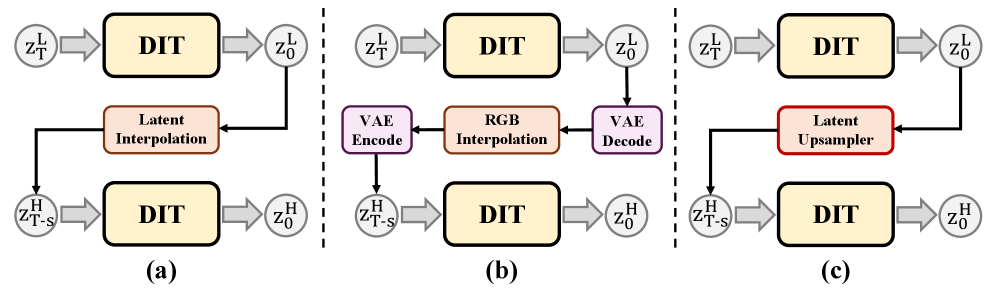
技术框架:LUVE框架包含三个主要阶段:1) 低分辨率运动生成:生成低分辨率的运动潜在表示,保证运动的一致性。2) 视频潜在上采样:在潜在空间中直接进行分辨率上采样,避免在高分辨率图像空间中进行计算,降低内存和计算开销。3) 高分辨率内容细化:利用低频和高频专家,分别增强语义连贯性和精细细节生成。整个框架采用级联的方式,逐步提升视频的分辨率和质量。
关键创新:LUVE的关键创新在于以下几个方面:一是提出了潜在级联的视频生成框架,有效降低了计算复杂度;二是引入了双频专家,分别处理低频语义信息和高频细节信息,提高了生成视频的质量和真实感;三是在潜在空间中进行分辨率上采样,避免了在高分辨率图像空间中进行计算,降低了内存和计算开销。
关键设计:在低分辨率运动生成阶段,可以使用各种视频生成模型,例如扩散模型或GAN。在视频潜在上采样阶段,可以使用各种图像超分辨率模型。在高分辨率内容细化阶段,低频专家可以使用卷积神经网络,高频专家可以使用Transformer网络。损失函数可以包括对抗损失、感知损失和运动一致性损失等。具体参数设置需要根据具体数据集和任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LUVE在超高分辨率视频生成任务中取得了显著的性能提升。与现有方法相比,LUVE生成的视频具有更高的照片真实感和内容保真度。消融实验验证了每个组件的有效性,特别是双频专家的作用。具体性能数据(如PSNR、SSIM等)和对比基线需要在论文中查找。
🎯 应用场景
LUVE框架在多个领域具有广泛的应用前景,包括电影制作、游戏开发、虚拟现实、增强现实等。它可以用于生成高质量的电影特效、逼真的游戏场景、沉浸式的虚拟现实体验以及交互式的增强现实应用。此外,LUVE还可以应用于视频修复、视频编辑和视频压缩等领域,提高视频处理的效率和质量。
📄 摘要(原文)
Recent advances in video diffusion models have significantly improved visual quality, yet ultra-high-resolution (UHR) video generation remains a formidable challenge due to the compounded difficulties of motion modeling, semantic planning, and detail synthesis. To address these limitations, we propose \textbf{LUVE}, a \textbf{L}atent-cascaded \textbf{U}HR \textbf{V}ideo generation framework built upon dual frequency \textbf{E}xperts. LUVE employs a three-stage architecture comprising low-resolution motion generation for motion-consistent latent synthesis, video latent upsampling that performs resolution upsampling directly in the latent space to mitigate memory and computational overhead, and high-resolution content refinement that integrates low-frequency and high-frequency experts to jointly enhance semantic coherence and fine-grained detail generation. Extensive experiments demonstrate that our LUVE achieves superior photorealism and content fidelity in UHR video generation, and comprehensive ablation studies further validate the effectiveness of each component. The project is available at \href{https://unicornanrocinu.github.io/LUVE_web/}{https://github.io/LUVE/}.