Vascular anatomy-aware self-supervised pre-training for X-ray angiogram analysis
作者: De-Xing Huang, Chaohui Yu, Xiao-Hu Zhou, Tian-Yu Xiang, Qin-Yi Zhang, Mei-Jiang Gui, Rui-Ze Ma, Chen-Yu Wang, Nu-Fang Xiao, Fan Wang, Zeng-Guang Hou
分类: cs.CV
发布日期: 2026-02-12
备注: 10 pages, 10 figures, 10 tables. Journal version of VasoMIM (AAAI 2026)
🔗 代码/项目: GITHUB
💡 一句话要点
提出VasoMIM血管解剖感知自监督预训练框架,提升X光血管造影图像分析性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: X光血管造影 自监督学习 掩码图像建模 血管解剖感知 预训练模型
📋 核心要点
- 现有X光血管造影分析深度学习方法受限于标注数据稀缺,阻碍了模型性能提升。
- VasoMIM通过解剖引导的掩码策略和解剖一致性损失,使模型学习鲁棒的血管语义和结构信息。
- VasoMIM在多个下游任务上验证,相比现有方法,展现出卓越的可迁移性和SOTA性能。
📝 摘要(中文)
X光血管造影是心血管疾病诊断的金标准成像方式。然而,当前深度学习方法在X光血管造影分析中受到标注数据稀缺的严重限制。大规模自监督学习(SSL)已成为一种有前景的解决方案,但由于缺乏有效的SSL框架和大规模数据集,其在该领域的潜力仍未得到充分挖掘。为了弥合这一差距,我们提出了一种血管解剖感知的掩码图像建模框架(VasoMIM),该框架显式地整合了领域特定的解剖学知识。具体来说,VasoMIM包含两个关键设计:解剖引导的掩码策略和解剖一致性损失。前者策略性地掩盖包含血管的图像块,以迫使模型学习鲁棒的血管语义,而后者则保持原始图像和重建图像之间血管的结构一致性,从而增强学习表征的区分性。结合VasoMIM,我们整理了迄今为止最大的X光血管造影预训练数据集XA-170K。我们在六个数据集上的四个下游任务中验证了VasoMIM,结果表明,与现有方法相比,VasoMIM具有卓越的可迁移性,并实现了最先进的性能。这些发现突出了VasoMIM作为基础模型在推进各种X光血管造影分析任务方面的巨大潜力。VasoMIM和XA-170K将在https://github.com/Dxhuang-CASIA/XA-SSL上提供。
🔬 方法详解
问题定义:X光血管造影图像分析任务面临标注数据不足的挑战,限制了深度学习模型的性能。现有方法难以有效利用无标注数据进行预训练,导致模型泛化能力不足,在下游任务中表现欠佳。
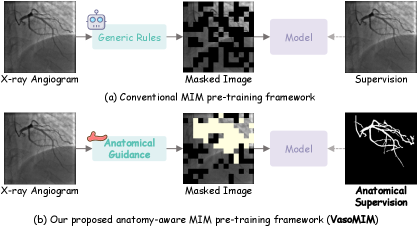
核心思路:论文的核心思路是利用血管解剖学知识,设计一种自监督学习框架VasoMIM,迫使模型学习血管的语义和结构信息。通过解剖引导的掩码策略,模型需要重建被遮挡的血管区域,从而学习到鲁棒的血管表征。解剖一致性损失则保证了重建图像与原始图像在血管结构上的一致性,进一步提升了表征的区分性。
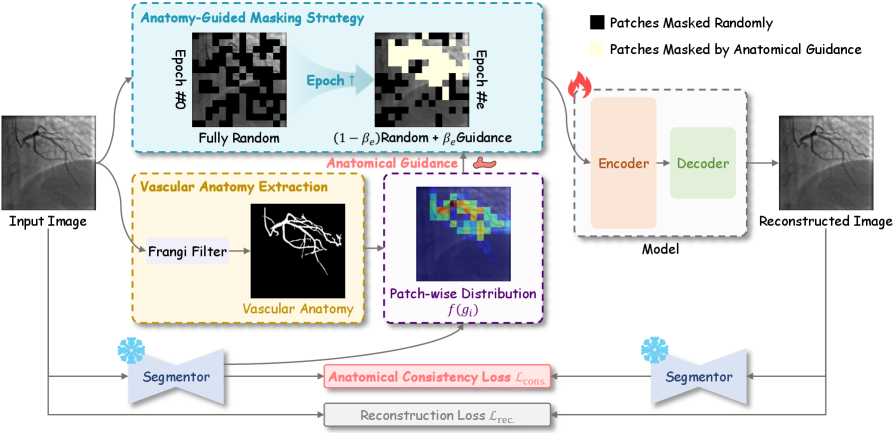
技术框架:VasoMIM框架主要包含两个关键模块:解剖引导的掩码策略和解剖一致性损失。首先,利用解剖学知识,对输入图像进行掩码,策略性地遮挡包含血管的图像块。然后,模型通过编码器-解码器结构,重建被遮挡的区域。最后,通过解剖一致性损失,约束重建图像与原始图像在血管结构上的一致性。整个框架采用自监督的方式进行训练,无需人工标注数据。
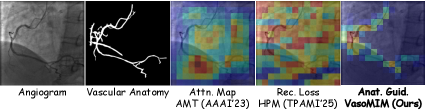
关键创新:VasoMIM的关键创新在于将领域特定的解剖学知识融入到自监督学习框架中。传统的掩码图像建模方法通常采用随机掩码策略,忽略了图像的结构信息。VasoMIM通过解剖引导的掩码策略,更加关注血管区域,迫使模型学习与血管相关的语义信息。此外,解剖一致性损失进一步提升了模型对血管结构的感知能力。
关键设计:解剖引导的掩码策略:利用预训练的血管分割模型,确定图像中血管的位置,然后根据血管的位置信息,对图像进行掩码。解剖一致性损失:采用L1损失或L2损失,衡量重建图像与原始图像在血管分割图上的差异。编码器-解码器结构:可以使用Transformer或CNN等不同的网络结构。XA-170K数据集:包含17万张X光血管造影图像,是目前最大的X光血管造影预训练数据集。
🖼️ 关键图片
📊 实验亮点
VasoMIM在四个下游任务(包括血管分割、血管狭窄检测等)的六个数据集上进行了验证,结果表明,VasoMIM相比于现有的自监督学习方法,取得了显著的性能提升。例如,在血管分割任务中,VasoMIM的Dice系数比现有方法提高了2-5个百分点,达到了SOTA水平。XA-170K数据集的发布也为X光血管造影图像分析领域的研究提供了宝贵的数据资源。
🎯 应用场景
该研究成果可广泛应用于心血管疾病的诊断和治疗,例如血管狭窄检测、血管分割、病灶识别等。通过VasoMIM预训练的模型可以作为基础模型,迁移到各种下游任务中,提高模型的性能和泛化能力。该研究有助于推动X光血管造影图像分析的自动化和智能化,提高诊断效率和准确性。
📄 摘要(原文)
X-ray angiography is the gold standard imaging modality for cardiovascular diseases. However, current deep learning approaches for X-ray angiogram analysis are severely constrained by the scarcity of annotated data. While large-scale self-supervised learning (SSL) has emerged as a promising solution, its potential in this domain remains largely unexplored, primarily due to the lack of effective SSL frameworks and large-scale datasets. To bridge this gap, we introduce a vascular anatomy-aware masked image modeling (VasoMIM) framework that explicitly integrates domain-specific anatomical knowledge. Specifically, VasoMIM comprises two key designs: an anatomy-guided masking strategy and an anatomical consistency loss. The former strategically masks vessel-containing patches to compel the model to learn robust vascular semantics, while the latter preserves structural consistency of vessels between original and reconstructed images, enhancing the discriminability of the learned representations. In conjunction with VasoMIM, we curate XA-170K, the largest X-ray angiogram pre-training dataset to date. We validate VasoMIM on four downstream tasks across six datasets, where it demonstrates superior transferability and achieves state-of-the-art performance compared to existing methods. These findings highlight the significant potential of VasoMIM as a foundation model for advancing a wide range of X-ray angiogram analysis tasks. VasoMIM and XA-170K will be available at https://github.com/Dxhuang-CASIA/XA-SSL.