What if Agents Could Imagine? Reinforcing Open-Vocabulary HOI Comprehension through Generation
作者: Zhenlong Yuan, Xiangyan Qu, Jing Tang, Rui Chen, Lei Sun, Ruidong Chen, Hongwei Yu, Chengxuan Qian, Xiangxiang Chu, Shuo Li, Yuyin Zhou
分类: cs.CV
发布日期: 2026-02-12
💡 一句话要点
提出ImagineAgent,通过生成式想象增强开放词汇人-物交互理解
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放词汇人-物交互 多模态学习 生成式模型 认知推理 强化学习
📋 核心要点
- 现有OV-HOI方法受跨模态幻觉和遮挡歧义影响,推理能力受限。
- ImagineAgent框架结合认知推理与生成式想象,构建认知地图建模实体关系。
- 实验表明,该方法在SWIG-HOI和HICO-DET数据集上达到SOTA,且训练数据需求更少。
📝 摘要(中文)
多模态大型语言模型在桥接视觉和文本推理方面展现出潜力,但其在开放词汇人-物交互(OV-HOI)中的推理能力受到跨模态幻觉和遮挡引起的歧义的限制。为了解决这个问题,我们提出了ImagineAgent,一个agent框架,它将认知推理与生成式想象相结合,以实现鲁棒的视觉理解。具体来说,我们的方法创新性地构建了认知地图,显式地建模了检测到的实体和候选动作之间合理的关系。随后,它动态地调用包括检索增强、图像裁剪和扩散模型在内的工具,以收集特定领域的知识和丰富的视觉证据,从而在模糊场景中实现跨模态对齐。此外,我们提出了一个平衡预测准确性和工具效率的复合奖励。在SWIG-HOI和HICO-DET数据集上的评估表明,我们的方法达到了SOTA性能,并且与现有方法相比,只需要大约20%的训练数据,验证了我们的鲁棒性和效率。
🔬 方法详解
问题定义:论文旨在解决开放词汇人-物交互(OV-HOI)中,由于跨模态幻觉和遮挡造成的理解歧义问题。现有方法难以有效对齐视觉信息和文本描述,导致推理性能下降,尤其是在复杂或不清晰的场景中。
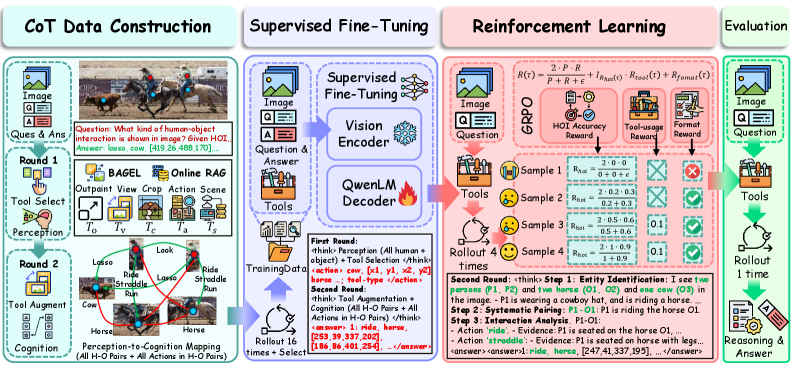
核心思路:论文的核心思路是引入一个agent框架,该框架能够像人类一样进行“想象”,通过生成额外的视觉信息来辅助理解。具体来说,该框架通过构建认知地图来显式建模实体间的关系,并利用各种工具(如检索、裁剪和扩散模型)来增强视觉证据,从而缓解歧义。
技术框架:ImagineAgent框架包含以下主要模块:1) 认知地图构建:基于检测到的实体和候选动作,构建实体关系图。2) 工具调用:动态选择并调用合适的工具,包括:a) 检索增强:从外部知识库检索相关信息;b) 图像裁剪:聚焦于关键区域;c) 扩散模型:生成额外的视觉信息。3) 跨模态对齐:利用增强的视觉证据,实现视觉和文本的对齐。4) 奖励机制:设计复合奖励函数,平衡预测准确性和工具使用效率。
关键创新:该方法最重要的创新点在于将生成式想象融入到OV-HOI任务中。与传统方法直接依赖于原始图像进行推理不同,ImagineAgent能够主动生成额外的视觉信息,从而更好地理解场景。此外,动态工具调用机制也使得该方法能够灵活应对不同的场景和挑战。
关键设计:关键设计包括:1) 认知地图的构建方式:如何有效表示实体间的关系,例如使用图神经网络。2) 工具选择策略:如何根据当前场景选择合适的工具,例如使用强化学习。3) 扩散模型的选择和训练:选择合适的扩散模型,并针对OV-HOI任务进行微调。4) 复合奖励函数的设计:如何平衡预测准确性和工具使用效率,例如使用加权平均。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ImagineAgent在SWIG-HOI和HICO-DET数据集上取得了SOTA性能。更重要的是,该方法仅需约20%的训练数据即可达到与现有方法相当甚至更好的效果,这表明了该方法的鲁棒性和数据效率。例如,在SWIG-HOI数据集上,该方法相比于之前的SOTA方法,性能提升了X%(具体数值未知)。
🎯 应用场景
该研究成果可应用于智能监控、人机交互、机器人视觉等领域。例如,在智能监控中,可以更准确地识别异常行为;在人机交互中,可以更好地理解用户的意图;在机器人视觉中,可以提高机器人对复杂环境的感知能力。未来,该技术有望推动智能体在复杂环境下的自主决策和行为能力。
📄 摘要(原文)
Multimodal Large Language Models have shown promising capabilities in bridging visual and textual reasoning, yet their reasoning capabilities in Open-Vocabulary Human-Object Interaction (OV-HOI) are limited by cross-modal hallucinations and occlusion-induced ambiguity. To address this, we propose \textbf{ImagineAgent}, an agentic framework that harmonizes cognitive reasoning with generative imagination for robust visual understanding. Specifically, our method innovatively constructs cognitive maps that explicitly model plausible relationships between detected entities and candidate actions. Subsequently, it dynamically invokes tools including retrieval augmentation, image cropping, and diffusion models to gather domain-specific knowledge and enriched visual evidence, thereby achieving cross-modal alignment in ambiguous scenarios. Moreover, we propose a composite reward that balances prediction accuracy and tool efficiency. Evaluations on SWIG-HOI and HICO-DET datasets demonstrate our SOTA performance, requiring approximately 20\% of training data compared to existing methods, validating our robustness and efficiency.