Beyond VLM-Based Rewards: Diffusion-Native Latent Reward Modeling
作者: Gongye Liu, Bo Yang, Yida Zhi, Zhizhou Zhong, Lei Ke, Didan Deng, Han Gao, Yongxiang Huang, Kaihao Zhang, Hongbo Fu, Wenhan Luo
分类: cs.CV, cs.AI
发布日期: 2026-02-11
备注: Code: https://github.com/HKUST-C4G/diffusion-rm
💡 一句话要点
提出DiNa-LRM,一种扩散原生潜在奖励模型,提升扩散模型偏好优化效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 偏好优化 奖励模型 潜在空间 噪声校准
📋 核心要点
- 现有基于VLM的奖励函数计算成本高昂,且像素空间奖励与潜在扩散模型存在域不匹配问题。
- DiNa-LRM直接在噪声扩散状态上进行偏好学习,利用噪声校准的Thurstone似然和时间步条件奖励头。
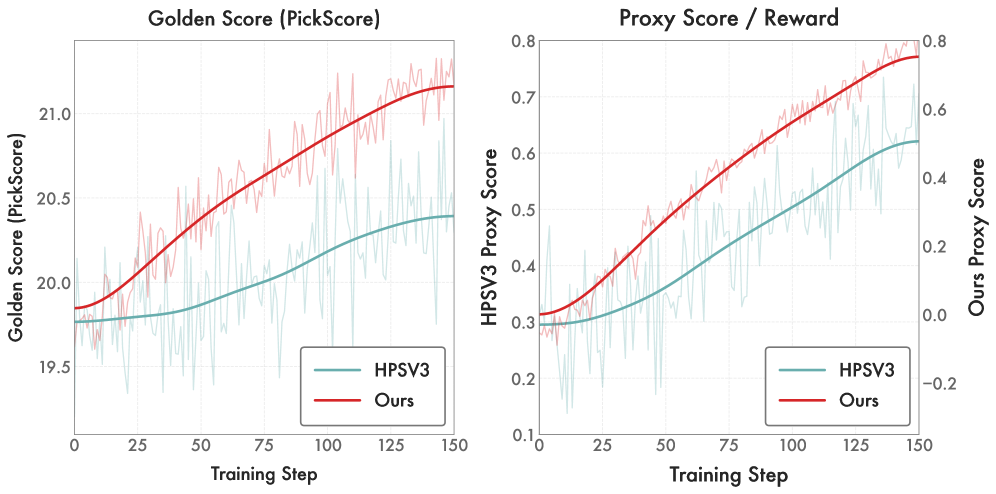
- 实验表明,DiNa-LRM在图像对齐任务上优于现有扩散模型奖励基线,并提升了偏好优化效率。
📝 摘要(中文)
扩散模型和Flow-Matching模型的偏好优化依赖于判别能力强且计算效率高的奖励函数。视觉-语言模型(VLM)已成为主要的奖励提供者,利用其丰富的多模态先验来指导对齐。然而,它们的计算和内存成本可能很高,并且通过像素空间奖励优化潜在扩散生成器会引入域不匹配,从而使对齐复杂化。本文提出了DiNa-LRM,一种扩散原生潜在奖励模型,它直接在噪声扩散状态上制定偏好学习。我们的方法引入了一种噪声校准的Thurstone似然,具有扩散噪声相关的uncertainty。DiNa-LRM利用预训练的潜在扩散骨干网络和一个时间步条件奖励头,并支持推理时噪声集成,为测试时缩放和鲁棒奖励提供了一种扩散原生机制。在图像对齐基准测试中,DiNa-LRM显著优于现有的基于扩散的奖励基线,并以一小部分的计算成本实现了与最先进的VLM竞争的性能。在偏好优化中,我们证明了DiNa-LRM改善了偏好优化动态,从而实现了更快、更资源高效的模型对齐。
🔬 方法详解
问题定义:论文旨在解决扩散模型偏好优化中,现有基于视觉-语言模型(VLM)的奖励函数计算成本高、效率低,以及像素空间奖励与潜在扩散模型之间存在域不匹配的问题。这些问题限制了扩散模型在需要人类偏好对齐的任务中的应用。
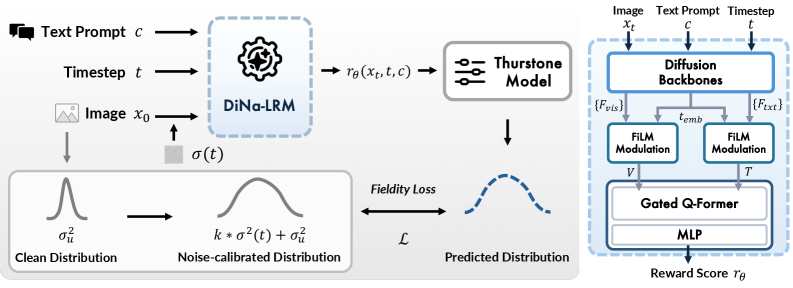
核心思路:论文的核心思路是设计一种扩散原生的潜在奖励模型(DiNa-LRM),直接在扩散过程的噪声状态上进行偏好学习。通过在潜在空间中进行奖励建模,避免了像素空间与潜在空间的域不匹配问题,并利用时间步信息来提高奖励的准确性和鲁棒性。
技术框架:DiNa-LRM的技术框架主要包括以下几个部分:1) 预训练的潜在扩散模型骨干网络,用于生成图像的潜在表示;2) 一个时间步条件奖励头,用于预测给定噪声水平下的奖励值;3) 噪声校准的Thurstone似然,用于建模人类偏好并训练奖励模型;4) 推理时噪声集成,用于提高奖励的鲁棒性。
关键创新:DiNa-LRM的关键创新在于:1) 提出了一种扩散原生的奖励建模方法,直接在噪声扩散状态上进行偏好学习,避免了域不匹配问题;2) 引入了噪声校准的Thurstone似然,考虑了扩散噪声对偏好判断的影响;3) 提出了推理时噪声集成方法,提高了奖励的鲁棒性。
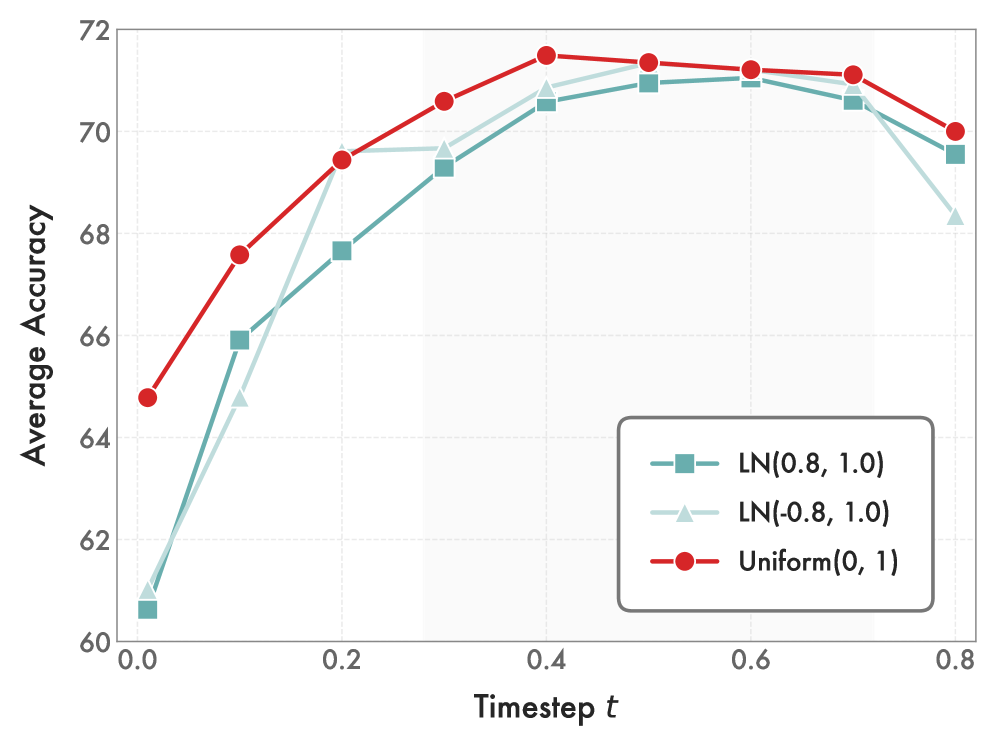
关键设计:DiNa-LRM的关键设计包括:1) 使用预训练的潜在扩散模型(如Stable Diffusion)作为骨干网络,以利用其强大的生成能力;2) 奖励头采用小型神经网络,以降低计算成本;3) 噪声校准的Thurstone似然使用扩散时间步作为条件,以建模噪声水平对偏好判断的影响;4) 推理时噪声集成通过对不同噪声水平下的奖励值进行加权平均,以提高奖励的鲁棒性。
🖼️ 关键图片
📊 实验亮点
DiNa-LRM在图像对齐基准测试中显著优于现有的基于扩散的奖励基线,并以远低于VLM的计算成本实现了与其竞争的性能。实验表明,DiNa-LRM能够改善偏好优化动态,实现更快、更资源高效的模型对齐。例如,在特定任务上,DiNa-LRM能够将训练时间缩短至原来的1/3,同时保持或提升生成质量。
🎯 应用场景
DiNa-LRM可应用于各种需要人类偏好对齐的扩散模型应用,例如个性化图像生成、风格迁移、图像编辑等。该方法降低了偏好优化的计算成本,提高了优化效率,使得扩散模型能够更好地满足用户的个性化需求,具有广泛的应用前景。
📄 摘要(原文)
Preference optimization for diffusion and flow-matching models relies on reward functions that are both discriminatively robust and computationally efficient. Vision-Language Models (VLMs) have emerged as the primary reward provider, leveraging their rich multimodal priors to guide alignment. However, their computation and memory cost can be substantial, and optimizing a latent diffusion generator through a pixel-space reward introduces a domain mismatch that complicates alignment. In this paper, we propose DiNa-LRM, a diffusion-native latent reward model that formulates preference learning directly on noisy diffusion states. Our method introduces a noise-calibrated Thurstone likelihood with diffusion-noise-dependent uncertainty. DiNa-LRM leverages a pretrained latent diffusion backbone with a timestep-conditioned reward head, and supports inference-time noise ensembling, providing a diffusion-native mechanism for test-time scaling and robust rewarding. Across image alignment benchmarks, DiNa-LRM substantially outperforms existing diffusion-based reward baselines and achieves performance competitive with state-of-the-art VLMs at a fraction of the computational cost. In preference optimization, we demonstrate that DiNa-LRM improves preference optimization dynamics, enabling faster and more resource-efficient model alignment.