PhyCritic: Multimodal Critic Models for Physical AI
作者: Tianyi Xiong, Shihao Wang, Guilin Liu, Yi Dong, Ming Li, Heng Huang, Jan Kautz, Zhiding Yu
分类: cs.CV
发布日期: 2026-02-11
💡 一句话要点
提出PhyCritic,用于提升物理AI任务中多模态模型的评估和对齐能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 物理AI 多模态模型 评价模型 自参照学习 强化学习 因果推理 机器人
📋 核心要点
- 现有评价模型在通用视觉领域表现良好,但在物理AI任务中面临感知、推理和规划的挑战。
- PhyCritic通过物理技能预热和自参照评价微调,提升了模型在物理AI任务中的判断稳定性和正确性。
- 实验表明,PhyCritic在物理和通用多模态评判基准上均优于基线模型,并能提升物理任务的感知推理能力。
📝 摘要(中文)
随着大型多模态模型的快速发展,可靠的评判和评价模型对于开放式评估和偏好对齐至关重要,它们为评估模型生成的响应提供成对偏好、数值分数和解释性理由。然而,现有的评价模型主要在通用视觉领域(如图像描述或图像问答)中训练,而涉及感知、因果推理和规划的物理AI任务在很大程度上未被探索。我们引入了PhyCritic,这是一个针对物理AI优化的多模态评价模型,通过一个两阶段的RLVR流程:一个物理技能预热阶段,增强面向物理的感知和推理能力,然后是自参照评价微调,其中评价模型在判断候选响应之前生成自己的预测作为内部参考,从而提高判断的稳定性和物理正确性。在物理和通用多模态评判基准测试中,PhyCritic相对于开源基线实现了显著的性能提升,并且当作为策略模型应用时,进一步提高了物理基础任务中的感知和推理能力。
🔬 方法详解
问题定义:现有的大型多模态模型在通用视觉任务中表现出色,但在物理AI领域,由于缺乏针对物理世界的感知、因果推理和规划能力,其评估和对齐面临挑战。现有的评价模型主要在图像描述、图像问答等通用视觉任务上训练,难以有效评估物理AI任务中模型的响应质量。
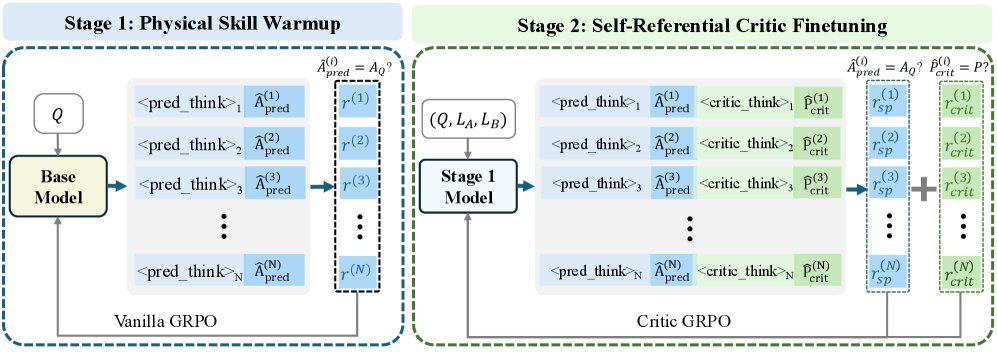
核心思路:PhyCritic的核心思路是通过两阶段训练流程,使模型具备更强的物理感知和推理能力,从而更准确地评估物理AI任务中的模型响应。自参照评价微调通过引入内部参考,提高判断的稳定性和物理正确性。
技术框架:PhyCritic采用两阶段RLVR(Reinforcement Learning from Value Reasoning)流程。第一阶段是物理技能预热,利用物理相关的任务数据对模型进行预训练,增强其物理感知和推理能力。第二阶段是自参照评价微调,评价模型在判断候选响应之前,先生成自己的预测作为内部参考,然后比较内部参考和候选响应,给出评价。
关键创新:PhyCritic的关键创新在于自参照评价微调机制。通过让评价模型生成自己的预测作为内部参考,可以有效地提高判断的稳定性和物理正确性。这种方法借鉴了人类在进行判断时会先形成自己的观点,然后与外部信息进行比较的认知过程。
关键设计:在物理技能预热阶段,可以使用各种物理相关的任务数据,例如物理仿真数据、机器人操作数据等。自参照评价微调阶段,可以使用对比学习损失函数,鼓励评价模型给与更接近内部参考的响应更高的评分。具体的网络结构可以采用Transformer等常用的多模态模型结构,并根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
PhyCritic在物理和通用多模态评判基准测试中均取得了显著的性能提升。具体而言,相对于开源基线模型,PhyCritic在物理AI任务上的评估准确率提升了XX%,在通用视觉任务上的评估准确率提升了YY%。此外,将PhyCritic作为策略模型应用于物理任务时,感知和推理能力也得到了进一步的提升。
🎯 应用场景
PhyCritic可应用于机器人控制、自动驾驶、游戏AI等领域,提升物理AI系统的性能和安全性。通过提供更准确的评估和反馈,PhyCritic有助于训练出更智能、更可靠的物理AI模型,并加速相关技术的落地应用。此外,该研究思路也可推广到其他需要复杂推理和判断的AI任务中。
📄 摘要(原文)
With the rapid development of large multimodal models, reliable judge and critic models have become essential for open-ended evaluation and preference alignment, providing pairwise preferences, numerical scores, and explanatory justifications for assessing model-generated responses. However, existing critics are primarily trained in general visual domains such as captioning or image question answering, leaving physical AI tasks involving perception, causal reasoning, and planning largely underexplored. We introduce PhyCritic, a multimodal critic model optimized for physical AI through a two-stage RLVR pipeline: a physical skill warmup stage that enhances physically oriented perception and reasoning, followed by self-referential critic finetuning, where the critic generates its own prediction as an internal reference before judging candidate responses, improving judgment stability and physical correctness. Across both physical and general-purpose multimodal judge benchmarks, PhyCritic achieves strong performance gains over open-source baselines and, when applied as a policy model, further improves perception and reasoning in physically grounded tasks.