Chain-of-Look Spatial Reasoning for Dense Surgical Instrument Counting
作者: Rishikesh Bhyri, Brian R Quaranto, Philip J Seger, Kaity Tung, Brendan Fox, Gene Yang, Steven D. Schwaitzberg, Junsong Yuan, Nan Xi, Peter C W Kim
分类: cs.CV, cs.AI
发布日期: 2026-02-11
备注: Accepted to WACV 2026. This version includes additional authors who contributed during the rebuttal phase
💡 一句话要点
提出Chain-of-Look空间推理框架,解决密集手术器械计数难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手术器械计数 密集场景 空间推理 视觉链 邻域损失
📋 核心要点
- 现有方法在密集场景下难以准确计数手术器械,缺乏对器械间空间关系的建模。
- Chain-of-Look通过构建视觉链模拟人类计数过程,并利用邻域损失函数强化空间约束。
- SurgCount-HD数据集上的实验表明,该方法显著优于现有计数方法和大型语言模型。
📝 摘要(中文)
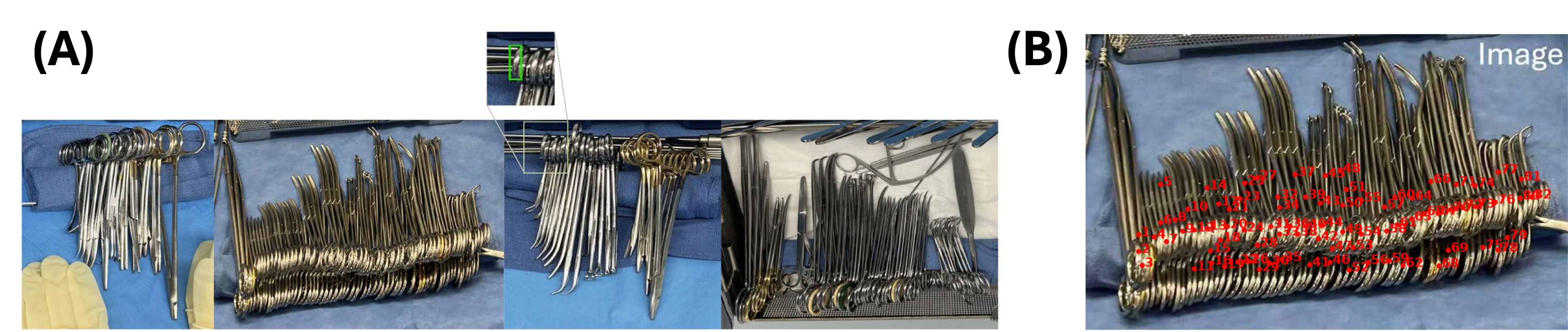
准确计数手术室(OR)中的手术器械是确保手术期间患者安全的关键前提。尽管大型视觉语言模型和智能AI取得了进展,但准确计数这些器械仍然具有挑战性,尤其是在器械密集聚集的情况下。为了解决这个问题,我们引入了Chain-of-Look,一种新颖的视觉推理框架,它通过强制执行结构化的视觉链来模仿人类的顺序计数过程,而不是依赖于经典的无序目标检测。这种视觉链引导模型沿着连贯的空间轨迹进行计数,从而提高复杂场景中的准确性。为了进一步加强视觉链的物理合理性,我们引入了邻域损失函数,该函数显式地模拟了密集堆积的手术器械固有的空间约束。我们还提出了SurgCount-HD,这是一个包含1,464张高密度手术器械图像的新数据集。大量实验表明,在具有挑战性的密集手术器械计数任务中,我们的方法优于最先进的计数方法(例如,CountGD, REC)以及多模态大型语言模型(例如,Qwen, ChatGPT)。
🔬 方法详解
问题定义:论文旨在解决手术场景中密集堆叠的手术器械的精确计数问题。现有方法,如传统的目标检测方法,通常忽略了器械之间的空间关系,导致在密集场景下计数准确率较低。此外,直接应用大型语言模型也难以有效解决该问题,因为它们缺乏对特定领域空间信息的有效利用。
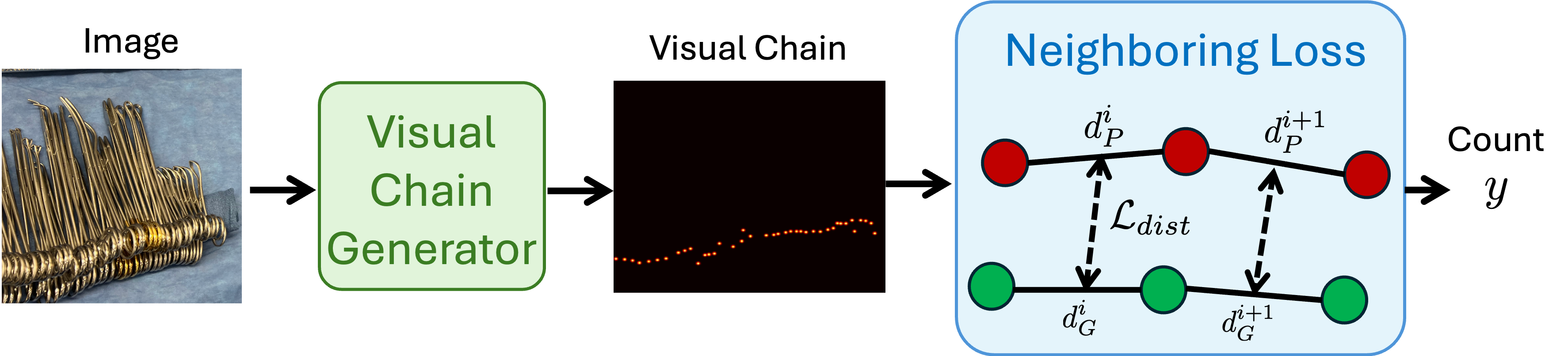
核心思路:论文的核心思路是模仿人类的计数方式,即通过建立一个有序的视觉链,沿着一个连贯的空间轨迹进行计数。这种方法能够显式地建模器械之间的空间关系,从而提高在密集场景下的计数准确率。通过强制模型按照特定的顺序观察和计数器械,可以避免重复计数或遗漏计数的情况。
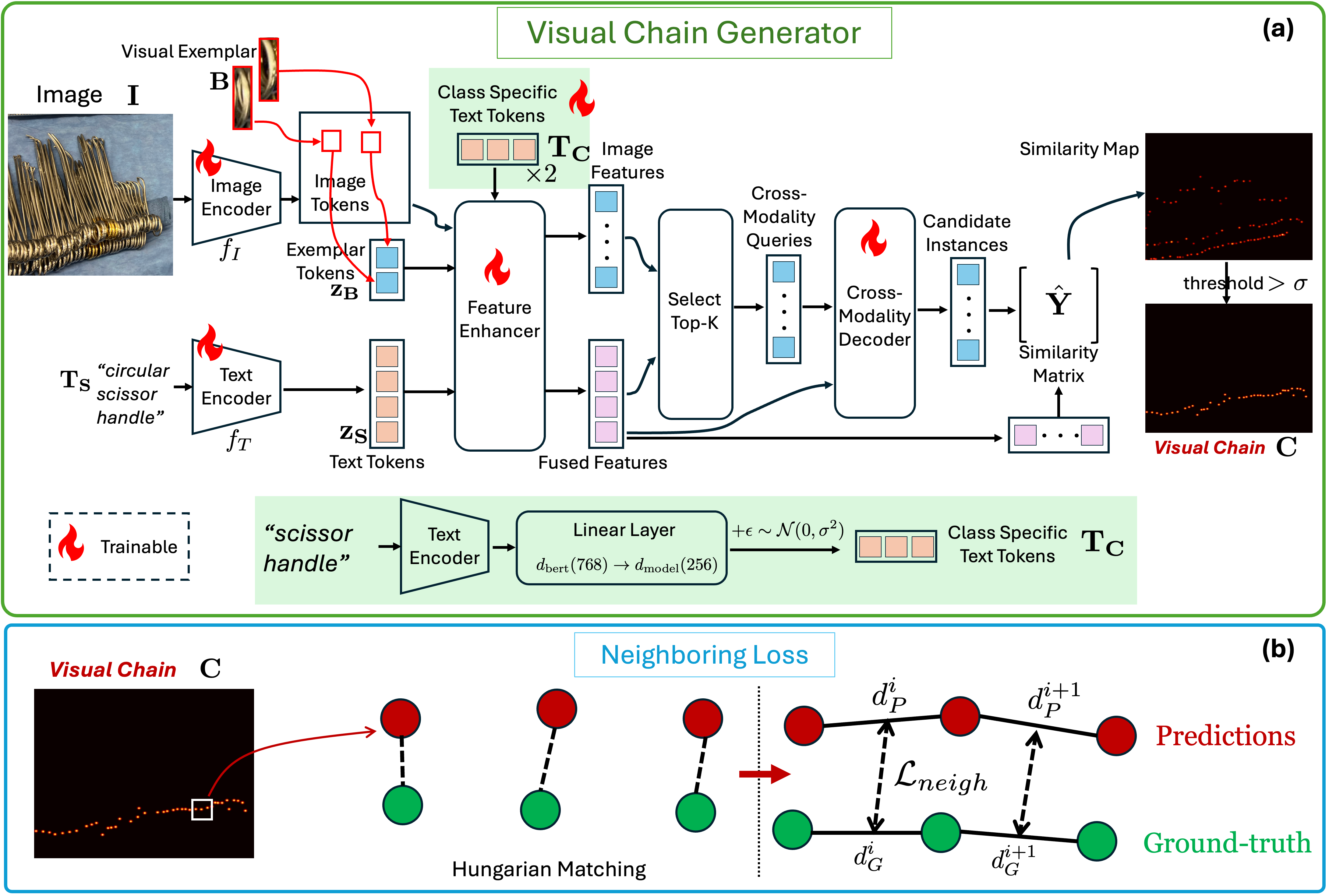
技术框架:Chain-of-Look框架包含以下主要模块:首先,通过视觉特征提取网络提取图像特征。然后,利用注意力机制构建视觉链,该视觉链指导模型按照特定的空间顺序进行计数。为了保证视觉链的物理合理性,引入了邻域损失函数,该损失函数显式地建模了相邻器械之间的空间约束。最后,通过计数头预测每个位置的器械数量。整体流程是从图像输入到特征提取,再到视觉链构建和计数预测。
关键创新:该论文最重要的技术创新点在于提出了Chain-of-Look框架,该框架通过构建视觉链来模拟人类的计数过程,从而显式地建模了器械之间的空间关系。与传统的目标检测方法相比,Chain-of-Look框架能够更好地处理密集场景下的计数问题。此外,邻域损失函数的引入进一步强化了视觉链的物理合理性。
关键设计:邻域损失函数是关键设计之一,它通过最小化相邻器械之间的距离来保证视觉链的连贯性和物理合理性。具体的损失函数形式可以根据实际情况进行调整,例如可以使用欧氏距离或余弦相似度等。此外,视觉链的构建方式也至关重要,可以使用注意力机制或循环神经网络等方法来构建视觉链。在实验中,论文使用了特定的网络结构和参数设置,但具体细节未详细描述,可能需要参考论文原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在SurgCount-HD数据集上,Chain-of-Look方法显著优于现有的计数方法(如CountGD和REC)以及多模态大型语言模型(如Qwen和ChatGPT)。具体的性能提升数据未在摘要中给出,需要在论文中查找。
🎯 应用场景
该研究成果可应用于手术室器械管理、医疗机器人辅助手术等领域。通过精确计数手术器械,可以有效减少手术风险,提高手术效率,并为术后器械清点提供可靠依据。未来,该技术有望扩展到其他密集物体计数场景,如仓库盘点、交通流量统计等。
📄 摘要(原文)
Accurate counting of surgical instruments in Operating Rooms (OR) is a critical prerequisite for ensuring patient safety during surgery. Despite recent progress of large visual-language models and agentic AI, accurately counting such instruments remains highly challenging, particularly in dense scenarios where instruments are tightly clustered. To address this problem, we introduce Chain-of-Look, a novel visual reasoning framework that mimics the sequential human counting process by enforcing a structured visual chain, rather than relying on classic object detection which is unordered. This visual chain guides the model to count along a coherent spatial trajectory, improving accuracy in complex scenes. To further enforce the physical plausibility of the visual chain, we introduce the neighboring loss function, which explicitly models the spatial constraints inherent to densely packed surgical instruments. We also present SurgCount-HD, a new dataset comprising 1,464 high-density surgical instrument images. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches for counting (e.g., CountGD, REC) as well as Multimodality Large Language Models (e.g., Qwen, ChatGPT) in the challenging task of dense surgical instrument counting.