LaSSM: Efficient Semantic-Spatial Query Decoding via Local Aggregation and State Space Models for 3D Instance Segmentation
作者: Lei Yao, Yi Wang, Yawen Cui, Moyun Liu, Lap-Pui Chau
分类: cs.CV
发布日期: 2026-02-11
备注: Accepted at IEEE-TCSVT
🔗 代码/项目: GITHUB
💡 一句话要点
LaSSM:基于局部聚合与状态空间模型的3D实例分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D实例分割 点云处理 状态空间模型 查询解码 局部聚合
📋 核心要点
- 现有基于查询的3D实例分割方法面临点云稀疏性带来的查询初始化难题,同时解码器依赖大量计算的注意力机制。
- LaSSM通过分层语义-空间查询初始化器和坐标引导的状态空间模型解码器,实现高效的查询细化和实例预测。
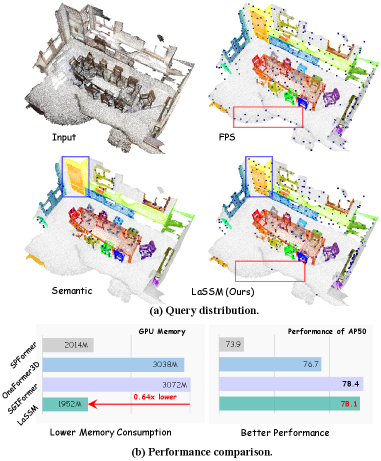
- LaSSM在ScanNet++ V2上取得领先,超越先前方法2.5% mAP,同时计算量仅为其1/3,并在其他数据集上表现出竞争力。
📝 摘要(中文)
本文提出LaSSM,一种高效的语义-空间查询解码方法,用于点云的基于查询的3D场景实例分割。现有方法受限于点云的稀疏性导致的查询初始化困境,并依赖于计算密集型的注意力机制。LaSSM在保持竞争力的同时,优先考虑简单性和效率。具体而言,我们提出了一个分层的语义-空间查询初始化器,通过考虑语义线索和空间分布,从超点中导出查询集,从而实现全面的场景覆盖和加速收敛。我们进一步提出了一个坐标引导的状态空间模型(SSM)解码器,该解码器逐步细化查询。该解码器具有局部聚合方案,限制模型专注于几何上连贯的区域,以及一个空间双路径SSM块,通过整合相关的坐标信息来捕获查询集中的潜在依赖关系。我们的设计实现了高效的实例预测,避免了噪声信息的引入,并减少了冗余计算。LaSSM在最新的ScanNet++ V2排行榜上名列第一,以仅1/3的FLOPs超越了之前的最佳方法2.5% mAP,证明了其在具有挑战性的大规模场景实例分割中的优越性。LaSSM还在ScanNet、ScanNet200、S3DIS和ScanNet++ V1基准测试中以更低的计算成本实现了具有竞争力的性能。大量的消融研究和定性结果验证了我们设计的有效性。
🔬 方法详解
问题定义:现有基于查询的3D实例分割方法,由于点云的稀疏性,难以进行有效的查询初始化,导致收敛速度慢,性能受限。此外,现有方法通常采用计算复杂度高的注意力机制进行查询解码,计算效率较低,难以应用于大规模场景。
核心思路:LaSSM的核心思路是利用语义信息和空间信息,从超点中初始化查询,从而实现更全面的场景覆盖和更快的收敛速度。同时,设计一种高效的坐标引导的状态空间模型(SSM)解码器,通过局部聚合和空间依赖建模,逐步细化查询,避免引入噪声信息,减少冗余计算。
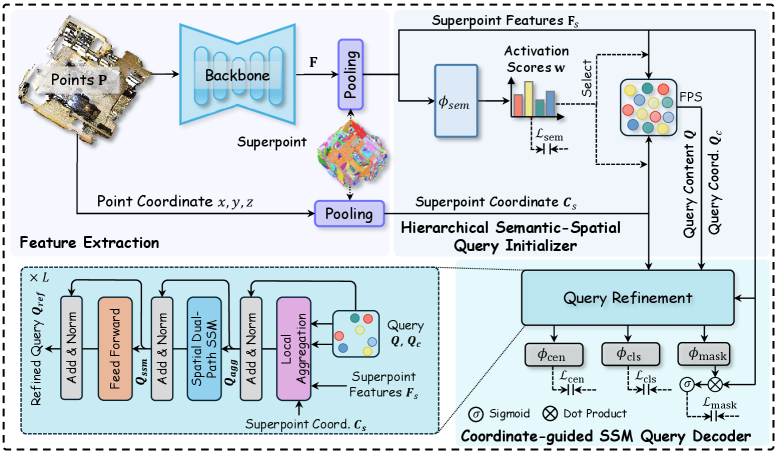
技术框架:LaSSM主要包含两个阶段:查询初始化和查询解码。首先,通过分层语义-空间查询初始化器,从超点中提取查询集。然后,利用坐标引导的状态空间模型(SSM)解码器,逐步细化查询,最终预测实例分割结果。解码器包含局部聚合模块和空间双路径SSM块。
关键创新:LaSSM的关键创新在于提出了坐标引导的状态空间模型(SSM)解码器,该解码器通过局部聚合方案限制模型专注于几何上连贯的区域,并通过空间双路径SSM块捕获查询集中的潜在依赖关系,同时整合了坐标信息。与传统的注意力机制相比,SSM解码器具有更高的计算效率和更强的建模能力。
关键设计:分层语义-空间查询初始化器利用超点的语义标签和空间分布,选择具有代表性的超点作为初始查询。局部聚合模块通过限制感受野,避免引入噪声信息。空间双路径SSM块包含两个并行的SSM,分别处理查询特征和坐标信息,从而更好地建模空间依赖关系。损失函数包括分割损失和掩码损失,用于优化实例分割结果。
🖼️ 关键图片

📊 实验亮点
LaSSM在ScanNet++ V2排行榜上取得了显著的成果,超越了先前的最佳方法2.5% mAP,同时计算量仅为其1/3。此外,LaSSM在ScanNet、ScanNet200、S3DIS和ScanNet++ V1等多个基准数据集上都取得了具有竞争力的性能,证明了其在不同场景下的泛化能力和高效性。
🎯 应用场景
LaSSM在3D场景理解领域具有广泛的应用前景,例如机器人导航、自动驾驶、虚拟现实和增强现实等。它可以用于识别和分割场景中的各种物体,从而为机器人提供更准确的环境感知,提高自动驾驶系统的安全性,并增强虚拟现实和增强现实的沉浸感。
📄 摘要(原文)
Query-based 3D scene instance segmentation from point clouds has attained notable performance. However, existing methods suffer from the query initialization dilemma due to the sparse nature of point clouds and rely on computationally intensive attention mechanisms in query decoders. We accordingly introduce LaSSM, prioritizing simplicity and efficiency while maintaining competitive performance. Specifically, we propose a hierarchical semantic-spatial query initializer to derive the query set from superpoints by considering both semantic cues and spatial distribution, achieving comprehensive scene coverage and accelerated convergence. We further present a coordinate-guided state space model (SSM) decoder that progressively refines queries. The novel decoder features a local aggregation scheme that restricts the model to focus on geometrically coherent regions and a spatial dual-path SSM block to capture underlying dependencies within the query set by integrating associated coordinates information. Our design enables efficient instance prediction, avoiding the incorporation of noisy information and reducing redundant computation. LaSSM ranks first place on the latest ScanNet++ V2 leaderboard, outperforming the previous best method by 2.5% mAP with only 1/3 FLOPs, demonstrating its superiority in challenging large-scale scene instance segmentation. LaSSM also achieves competitive performance on ScanNet, ScanNet200, S3DIS and ScanNet++ V1 benchmarks with less computational cost. Extensive ablation studies and qualitative results validate the effectiveness of our design. The code and weights are available at https://github.com/RayYoh/LaSSM.