Towards Learning a Generalizable 3D Scene Representation from 2D Observations
作者: Martin Gromniak, Jan-Gerrit Habekost, Sebastian Kamp, Sven Magg, Stefan Wermter
分类: cs.CV, cs.RO
发布日期: 2026-02-11
备注: Paper accepted at ESANN 2026
💡 一句话要点
提出一种可泛化的神经辐射场方法,用于机器人全局工作空间三维重建
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 神经辐射场 三维重建 机器人操作 全局坐标系 场景理解
📋 核心要点
- 现有方法通常在相机坐标系下进行三维重建,限制了其在机器人操作等需要全局信息的场景中的应用。
- 该论文提出在全局工作空间坐标系下构建占用表示,从而实现对机器人操作的直接应用,并提高泛化能力。
- 实验表明,该模型在真实场景中实现了26毫米的重建误差,即使在遮挡区域也能有效推断三维占用情况。
📝 摘要(中文)
本文提出了一种可泛化的神经辐射场方法,用于从以机器人为中心的观测中预测三维工作空间占用情况。与以往在相机坐标系中运行的方法不同,我们的模型在全局工作空间坐标系中构建占用表示,使其可以直接应用于机器人操作。该模型集成了灵活的源视图,并能推广到未见过的物体排列,而无需针对特定场景进行微调。我们在一个人形机器人上演示了该方法,并将预测的几何形状与三维传感器真值进行评估。在40个真实场景上训练的模型实现了26毫米的重建误差,包括遮挡区域,验证了其推断完整三维占用情况的能力,超越了传统的立体视觉方法。
🔬 方法详解
问题定义:现有基于神经辐射场的三维重建方法通常在相机坐标系下进行,这对于需要全局场景理解的机器人应用来说是不够的。此外,这些方法通常需要针对特定场景进行微调,泛化能力较差。因此,需要一种能够在全局坐标系下进行三维重建,并且具有良好泛化能力的模型。
核心思路:该论文的核心思路是在全局工作空间坐标系下构建神经辐射场,从而实现与机器人操作的直接集成。通过在全局坐标系下进行学习,模型可以更好地理解场景的整体结构,从而提高泛化能力。此外,该模型集成了灵活的源视图,可以从不同的视角进行观测,进一步提高重建的准确性和鲁棒性。
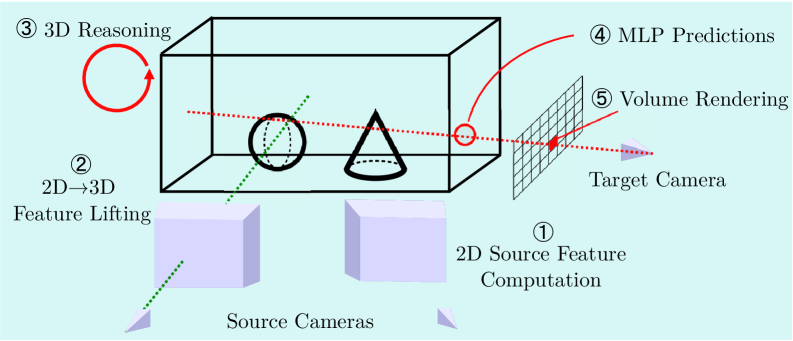
技术框架:该模型主要包含以下几个模块:1) 图像特征提取模块,用于从输入的图像中提取特征;2) 位姿估计模块,用于估计相机的位姿;3) 神经辐射场模块,用于在全局坐标系下构建三维场景表示;4) 渲染模块,用于将三维场景表示渲染成图像。整个流程如下:首先,从输入的图像中提取特征,并估计相机的位姿。然后,将特征和位姿输入到神经辐射场模块中,构建三维场景表示。最后,使用渲染模块将三维场景表示渲染成图像,并与真实图像进行比较,计算损失函数,优化模型参数。
关键创新:该论文的关键创新在于:1) 在全局工作空间坐标系下构建神经辐射场,从而实现与机器人操作的直接集成;2) 提出了一种灵活的源视图集成方法,可以从不同的视角进行观测,提高重建的准确性和鲁棒性;3) 实现了良好的泛化能力,无需针对特定场景进行微调。
关键设计:该模型使用了一个多层感知机(MLP)作为神经辐射场模块,用于将三维坐标和视角方向映射到颜色和密度。损失函数包括重建损失和正则化损失。重建损失用于衡量渲染图像与真实图像之间的差异,正则化损失用于防止过拟合。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
该模型在40个真实场景上进行了训练和评估,实现了26毫米的重建误差,包括遮挡区域。实验结果表明,该模型能够有效地推断完整的三维占用情况,超越了传统的立体视觉方法。此外,该模型具有良好的泛化能力,无需针对特定场景进行微调,可以直接应用于新的场景。
🎯 应用场景
该研究成果可应用于机器人操作、自主导航、场景理解等领域。例如,机器人可以利用该模型重建工作空间的三维模型,从而进行物体抓取、放置等操作。此外,该模型还可以用于增强现实、虚拟现实等应用,为用户提供更加逼真的三维场景体验。未来,该研究可以进一步扩展到动态场景的重建,为机器人提供更加全面的环境感知能力。
📄 摘要(原文)
We introduce a Generalizable Neural Radiance Field approach for predicting 3D workspace occupancy from egocentric robot observations. Unlike prior methods operating in camera-centric coordinates, our model constructs occupancy representations in a global workspace frame, making it directly applicable to robotic manipulation. The model integrates flexible source views and generalizes to unseen object arrangements without scene-specific finetuning. We demonstrate the approach on a humanoid robot and evaluate predicted geometry against 3D sensor ground truth. Trained on 40 real scenes, our model achieves 26mm reconstruction error, including occluded regions, validating its ability to infer complete 3D occupancy beyond traditional stereo vision methods.