Dual-End Consistency Model
作者: Linwei Dong, Ruoyu Guo, Ge Bai, Zehuan Yuan, Yawei Luo, Changqing Zou
分类: cs.CV
发布日期: 2026-02-11
💡 一句话要点
提出双端一致性模型(DE-CM),解决一致性模型训练不稳定和采样不灵活的问题,实现高效图像生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 一致性模型 生成模型 扩散模型 蒸馏训练 图像生成 快速采样 轨迹选择
📋 核心要点
- 扩散模型和流模型采样速度慢,一致性模型存在训练不稳定和采样不灵活的问题。
- 提出双端一致性模型(DE-CM),通过选择关键子轨迹簇,并结合流匹配正则化,实现稳定训练。
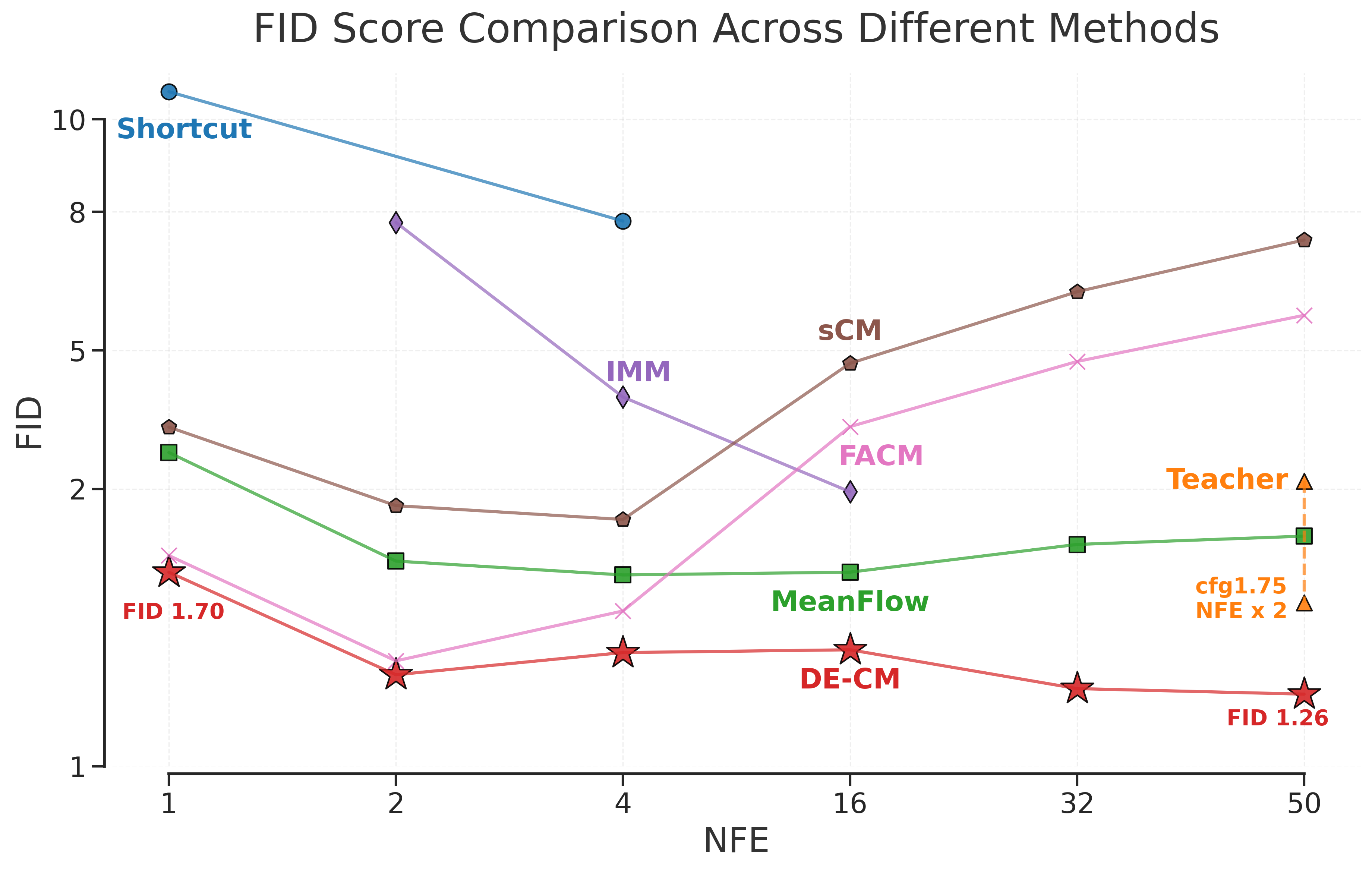
- 在ImageNet 256x256数据集上,一步生成实现了1.70的FID分数,优于现有方法。
📝 摘要(中文)
扩散模型和基于流的生成模型因其缓慢的迭代采样过程而难以实际部署。一致性模型(CMs)是目前最先进的基于蒸馏的高效生成方法,但其大规模应用仍受训练不稳定和采样不灵活两大问题的限制。现有方法试图通过架构调整或正则化目标来缓解这些问题,但忽略了对轨迹选择的关键依赖。本文首先分析了这两个限制:训练不稳定源于不稳定的自监督项引起的损失发散,而采样不灵活源于误差累积。基于这些分析,我们提出了双端一致性模型(DE-CM),该模型选择重要的子轨迹簇来实现稳定有效的训练。DE-CM分解了PF-ODE轨迹,并选择三个关键子轨迹作为优化目标。具体来说,我们的方法利用连续时间CMs目标来实现少步蒸馏,并利用流匹配作为边界正则化器来稳定训练过程。此外,我们提出了一种新颖的噪声到噪声(N2N)映射,可以将噪声映射到任何点,从而减轻第一步中的误差累积。大量的实验结果表明了我们方法的有效性:在ImageNet 256x256数据集上,一步生成实现了1.70的最先进FID分数,优于现有的基于CM的一步方法。
🔬 方法详解
问题定义:一致性模型(CMs)虽然在加速生成式模型采样方面表现出色,但其训练过程常常不稳定,且采样过程不够灵活。训练不稳定主要源于自监督学习中的损失发散,而采样不灵活则导致误差在初始步骤中累积,最终影响生成质量。现有方法试图通过修改网络结构或添加正则化项来解决这些问题,但忽略了轨迹选择的重要性。
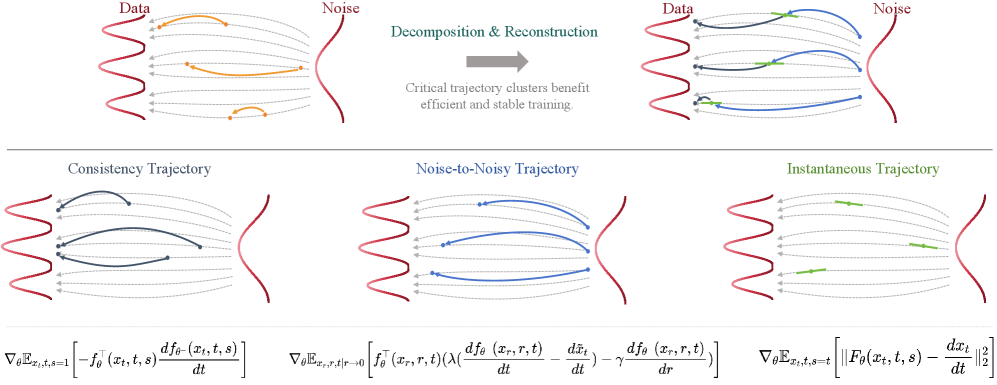
核心思路:DE-CM的核心思路是通过选择关键的子轨迹簇来稳定训练过程,并设计一种新的噪声到噪声(N2N)映射来缓解采样过程中的误差累积。通过分解概率流常微分方程(PF-ODE)轨迹,并选择三个关键子轨迹作为优化目标,DE-CM能够更有效地进行蒸馏训练,并提高生成质量。
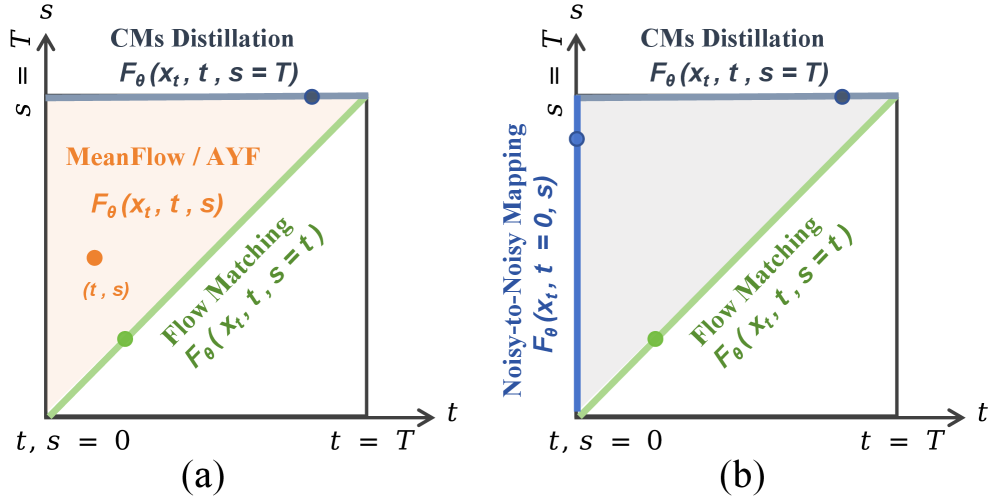
技术框架:DE-CM的整体框架包括以下几个主要部分:1) PF-ODE轨迹分解与子轨迹选择;2) 基于连续时间CMs目标的少步蒸馏;3) 利用流匹配作为边界正则化器以稳定训练;4) 新颖的噪声到噪声(N2N)映射,用于减轻初始采样步骤中的误差累积。该框架旨在通过优化关键子轨迹和减少初始误差,从而实现更稳定、更高效的生成过程。
关键创新:DE-CM的关键创新在于:1) 提出了一种新的轨迹选择策略,通过选择关键子轨迹簇来优化训练过程,而非简单地依赖整个轨迹;2) 引入了噪声到噪声(N2N)映射,允许将噪声映射到轨迹上的任意点,从而显著降低了初始采样步骤中的误差累积。这与传统方法仅关注整体损失函数的优化或网络结构的调整有所不同。
关键设计:DE-CM的关键设计包括:1) 损失函数的设计,结合了连续时间CMs目标和流匹配正则化项,以实现稳定训练;2) 子轨迹的选择策略,通过实验确定了三个关键子轨迹,并将其作为优化目标;3) 噪声到噪声(N2N)映射的具体实现方式,包括如何选择目标点以及如何训练映射网络。
🖼️ 关键图片
📊 实验亮点
DE-CM在ImageNet 256x256数据集上的一步生成任务中取得了显著成果,FID分数达到了1.70,超越了现有的基于一致性模型的一步生成方法。这一结果表明,DE-CM在保证生成质量的同时,显著提高了生成速度,为实际应用奠定了基础。此外,该模型在训练稳定性和采样灵活性方面也表现出优越性。
🎯 应用场景
DE-CM具有广泛的应用前景,包括图像生成、视频生成、3D模型生成等。其高效的生成能力使其适用于对实时性要求较高的场景,例如游戏、虚拟现实和增强现实。此外,该方法还可以应用于图像修复、超分辨率等图像处理任务,以及数据增强等机器学习任务。未来,DE-CM有望成为各种生成式任务的基础模型。
📄 摘要(原文)
The slow iterative sampling nature remains a major bottleneck for the practical deployment of diffusion and flow-based generative models. While consistency models (CMs) represent a state-of-the-art distillation-based approach for efficient generation, their large-scale application is still limited by two key issues: training instability and inflexible sampling. Existing methods seek to mitigate these problems through architectural adjustments or regularized objectives, yet overlook the critical reliance on trajectory selection. In this work, we first conduct an analysis on these two limitations: training instability originates from loss divergence induced by unstable self-supervised term, whereas sampling inflexibility arises from error accumulation. Based on these insights and analysis, we propose the Dual-End Consistency Model (DE-CM) that selects vital sub-trajectory clusters to achieve stable and effective training. DE-CM decomposes the PF-ODE trajectory and selects three critical sub-trajectories as optimization targets. Specifically, our approach leverages continuous-time CMs objectives to achieve few-step distillation and utilizes flow matching as a boundary regularizer to stabilize the training process. Furthermore, we propose a novel noise-to-noisy (N2N) mapping that can map noise to any point, thereby alleviating the error accumulation in the first step. Extensive experimental results show the effectiveness of our method: it achieves a state-of-the-art FID score of 1.70 in one-step generation on the ImageNet 256x256 dataset, outperforming existing CM-based one-step approaches.