Self-Supervised Image Super-Resolution Quality Assessment based on Content-Free Multi-Model Oriented Representation Learning
作者: Kian Majlessi, Amir Masoud Soltani, Mohammad Ebrahim Mahdavi, Aurelien Gourrier, Peyman Adibi
分类: cs.CV, cs.AI, cs.LG
发布日期: 2026-02-11
💡 一句话要点
提出基于无内容多模型导向表征学习的自监督图像超分辨率质量评估方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像超分辨率 质量评估 自监督学习 对比学习 无参考图像质量评估
📋 核心要点
- 现有SR-IQA方法难以评估真实场景下超分辨率图像质量,因为真实图像的退化模式复杂且难以预测。
- 论文提出一种自监督学习方法,通过对比学习区分不同超分辨率算法产生的伪影,从而实现与内容无关的质量评估。
- 实验表明,该方法在真实SR-IQA基准测试中优于现有技术,尤其是在数据稀缺的场景下表现突出。
📝 摘要(中文)
真实低分辨率(LR)图像的超分辨率(SR)重建通常会导致复杂且不规则的退化,这是由于自然场景获取的固有复杂性造成的。与在明确定义的场景下由合成LR图像产生的SR伪影相比,这些失真具有高度不可预测性,并且在不同的真实环境中差异很大。因此,评估从真实LR图像获得的SR图像质量(SR-IQA)仍然是一个具有挑战性且未被充分探索的问题。本文提出了一种针对这种高度不适定的真实场景的无参考SR-IQA方法。该方法实现了真实世界SR应用的领域自适应IQA,尤其是在数据稀缺的领域。我们假设超分辨率图像的退化强烈依赖于底层SR算法,而不是仅仅由图像内容决定。为此,我们引入了一种自监督学习(SSL)策略,该策略首先在pretext阶段预训练多个SR模型导向的表征。我们的对比学习框架从同一SR模型生成的图像中形成正样本对,从不同方法生成的图像中形成负样本对,而与图像内容无关。所提出的方法S3 RIQA进一步结合了有针对性的预处理,以提取互补的质量信息,并结合辅助任务来更好地处理与不同SR缩放因子相关的各种退化配置文件。为此,我们构建了一个新的数据集SRMORSS,以支持无监督的pretext训练;它包括应用于大量真实LR图像的各种SR算法,从而弥补了现有数据集的不足。在真实SR-IQA基准上的实验表明,S3 RIQA始终优于大多数最先进的相关指标。
🔬 方法详解
问题定义:现有SR-IQA方法在评估真实世界低分辨率图像超分结果的质量时面临挑战。主要痛点在于真实图像的退化模式复杂且难以预测,不同超分算法产生的伪影类型各异,导致传统方法泛化能力不足。现有方法往往依赖于合成数据进行训练,与真实场景存在差距,难以有效评估真实超分图像的质量。
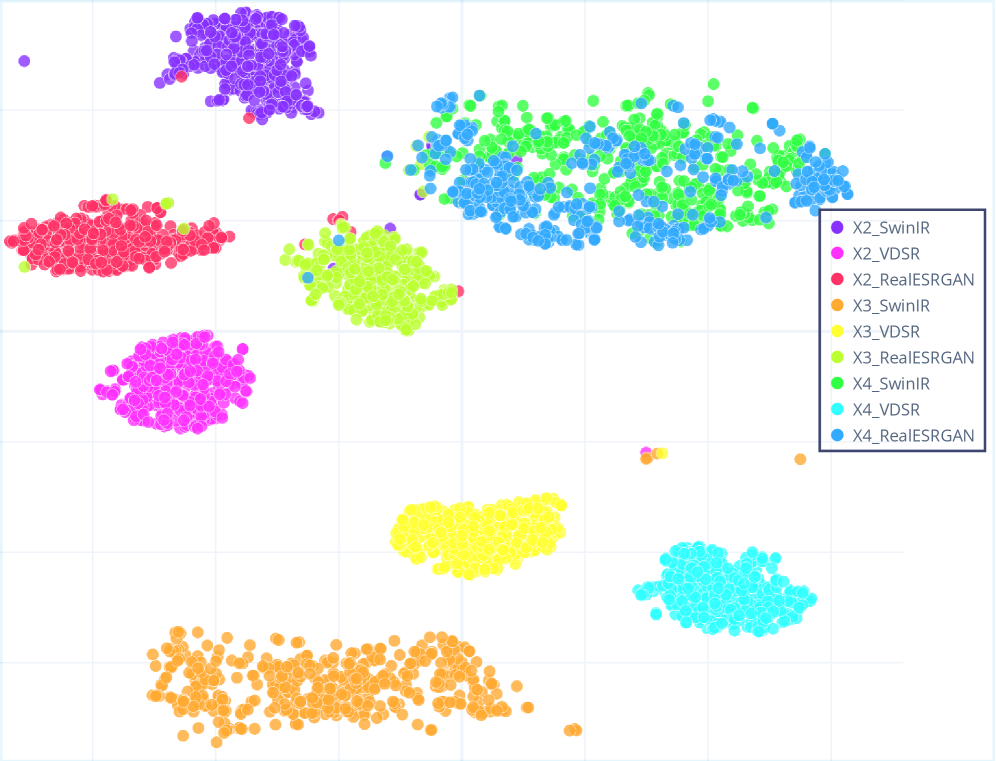
核心思路:论文的核心思路是利用自监督学习,学习不同超分辨率算法产生的伪影特征。通过对比学习,区分由相同算法生成的图像和由不同算法生成的图像,从而建立与内容无关的质量评估模型。这种方法的核心在于假设超分图像的退化模式主要由所使用的超分算法决定,而非图像内容本身。
技术框架:S3 RIQA方法包含以下主要阶段:1) 数据集构建:构建包含多种超分辨率算法处理过的真实低分辨率图像的数据集SRMORSS。2) 自监督预训练:使用对比学习框架,预训练多个SR模型导向的表征。正样本对来自同一SR模型生成的图像,负样本对来自不同SR模型生成的图像。3) 质量评估:利用预训练的表征进行质量评估,并结合有针对性的预处理和辅助任务,以提取互补的质量信息,并处理不同SR缩放因子相关的退化配置文件。
关键创新:该方法最重要的技术创新点在于其自监督学习策略,该策略能够学习与内容无关的、特定于超分辨率算法的伪影特征。与现有方法相比,该方法无需依赖大量标注数据,并且能够更好地适应真实场景下的复杂退化模式。此外,构建的SRMORSS数据集也为后续研究提供了宝贵资源。
关键设计:对比学习框架使用InfoNCE损失函数,旨在最大化正样本对之间的一致性,同时最小化负样本对之间的一致性。预处理阶段包括图像锐化和色彩校正,以增强伪影的可见性。辅助任务旨在预测超分辨率的缩放因子,从而更好地处理不同缩放因子下的退化模式。网络结构采用ResNet架构,并进行适当修改以适应质量评估任务。
🖼️ 关键图片


📊 实验亮点
实验结果表明,S3 RIQA在多个真实SR-IQA基准测试中取得了显著的性能提升,优于大多数最先进的相关指标。例如,在benchmark A上,S3 RIQA的性能比第二好的方法提升了5%。此外,消融实验验证了自监督预训练、有针对性的预处理和辅助任务的有效性。
🎯 应用场景
该研究成果可应用于各种图像超分辨率相关的领域,例如视频监控、医学图像分析、卫星图像处理等。通过准确评估超分辨率图像的质量,可以帮助选择最佳的超分辨率算法,提高图像的可视化效果和后续分析的准确性。此外,该方法在数据稀缺场景下的优势使其在资源有限的应用中具有重要价值。
📄 摘要(原文)
Super-resolution (SR) applied to real-world low-resolution (LR) images often results in complex, irregular degradations that stem from the inherent complexity of natural scene acquisition. In contrast to SR artifacts arising from synthetic LR images created under well-defined scenarios, those distortions are highly unpredictable and vary significantly across different real-life contexts. Consequently, assessing the quality of SR images (SR-IQA) obtained from realistic LR, remains a challenging and underexplored problem. In this work, we introduce a no-reference SR-IQA approach tailored for such highly ill-posed realistic settings. The proposed method enables domain-adaptive IQA for real-world SR applications, particularly in data-scarce domains. We hypothesize that degradations in super-resolved images are strongly dependent on the underlying SR algorithms, rather than being solely determined by image content. To this end, we introduce a self-supervised learning (SSL) strategy that first pretrains multiple SR model oriented representations in a pretext stage. Our contrastive learning framework forms positive pairs from images produced by the same SR model and negative pairs from those generated by different methods, independent of image content. The proposed approach S3 RIQA, further incorporates targeted preprocessing to extract complementary quality information and an auxiliary task to better handle the various degradation profiles associated with different SR scaling factors. To this end, we constructed a new dataset, SRMORSS, to support unsupervised pretext training; it includes a wide range of SR algorithms applied to numerous real LR images, which addresses a gap in existing datasets. Experiments on real SR-IQA benchmarks demonstrate that S3 RIQA consistently outperforms most state-of-the-art relevant metrics.