Multimodal Priors-Augmented Text-Driven 3D Human-Object Interaction Generation
作者: Yin Wang, Ziyao Zhang, Zhiying Leng, Haitian Liu, Frederick W. B. Li, Mu Li, Xiaohui Liang
分类: cs.CV
发布日期: 2026-02-11
💡 一句话要点
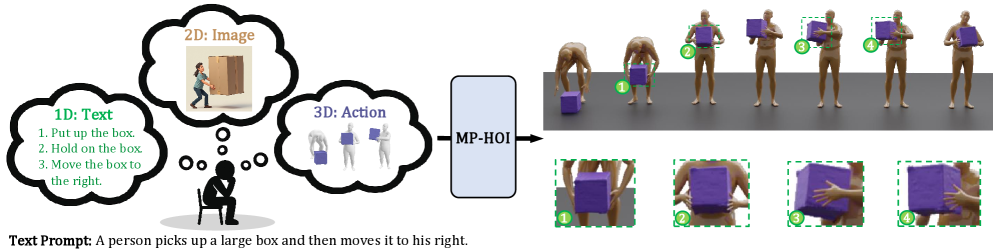
提出MP-HOI框架,利用多模态先验知识生成高质量的文本驱动3D人-物交互动作
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人-物交互生成 文本驱动生成 多模态学习 扩散模型 3D动作生成
📋 核心要点
- 现有文本驱动3D人-物交互生成方法受限于跨模态鸿沟,导致人体运动不自然、物体运动不真实、交互效果弱。
- MP-HOI框架利用多模态数据先验指导生成,增强物体表示,并采用多模态混合专家模型进行特征融合。
- 实验结果表明,MP-HOI在生成高质量和细粒度的人-物交互动作方面优于现有方法,提升了生成效果。
📝 摘要(中文)
本文致力于解决文本驱动的3D人-物交互(HOI)动作生成这一具有挑战性的任务。现有方法主要依赖于直接的文本到HOI映射,但由于显著的跨模态差距,存在三个关键限制:(Q1)次优的人体运动,(Q2)不自然的物体运动,以及(Q3)人与物体之间较弱的交互。为了应对这些挑战,我们提出了MP-HOI,这是一个基于四个核心见解的新颖框架:(1)多模态数据先验:我们利用来自大型多模态模型的多模态数据(文本、图像、姿势/物体)作为先验来指导HOI生成,从而解决数据建模中的Q1和Q2。(2)增强的物体表示:我们通过结合几何关键点、接触特征和动态属性来改进现有的物体表示,从而实现富有表现力的物体表示,从而解决数据表示中的Q2。(3)多模态感知的混合专家(MoE)模型:我们提出了一种模态感知的MoE模型,用于有效的多模态特征融合范式,从而解决特征融合中的Q1和Q2。(4)具有交互监督的级联扩散:我们设计了一个级联扩散框架,该框架在专门的监督下逐步细化人-物交互特征,从而解决交互细化中的Q3。综合实验表明,MP-HOI在生成高保真度和细粒度的HOI动作方面优于现有方法。
🔬 方法详解
问题定义:论文旨在解决文本驱动的3D人-物交互(HOI)动作生成问题。现有方法直接将文本映射到HOI动作,但由于文本和3D动作之间存在巨大的模态差异,导致生成的人体运动不自然,物体运动不真实,人与物体之间的交互较弱。这些问题限制了生成HOI动作的真实性和自然性。
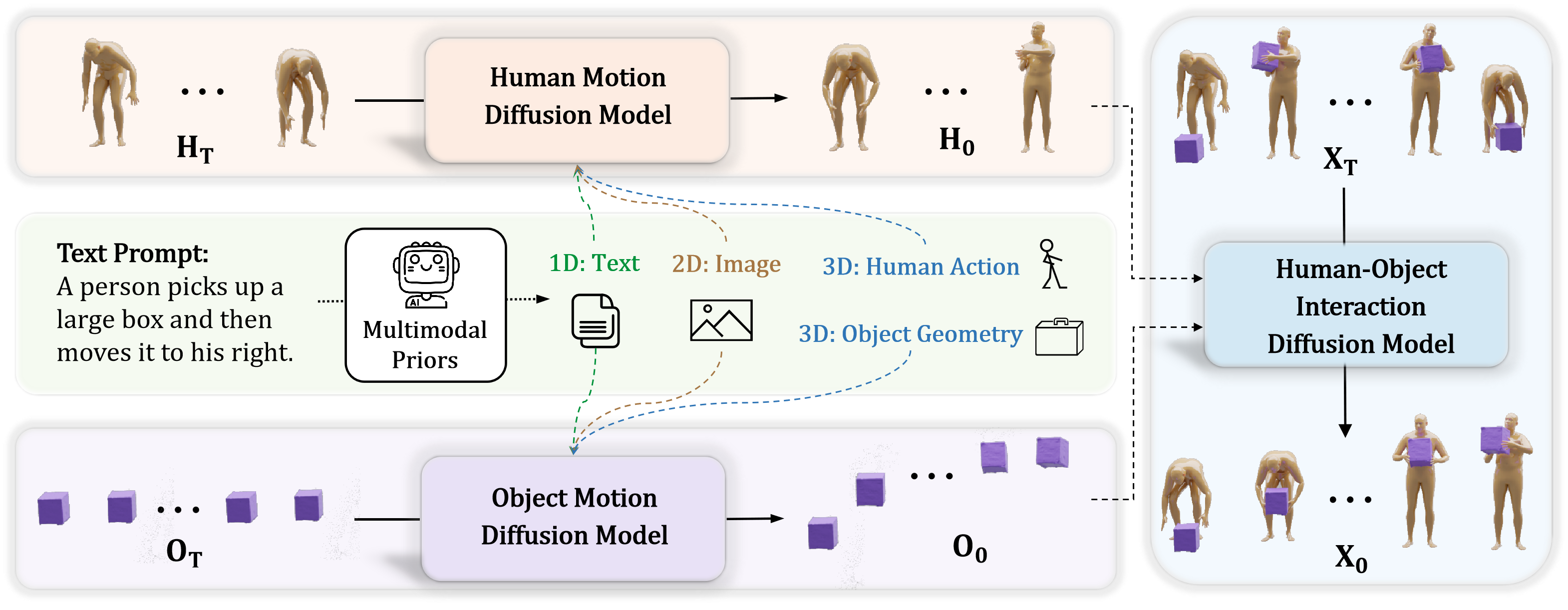
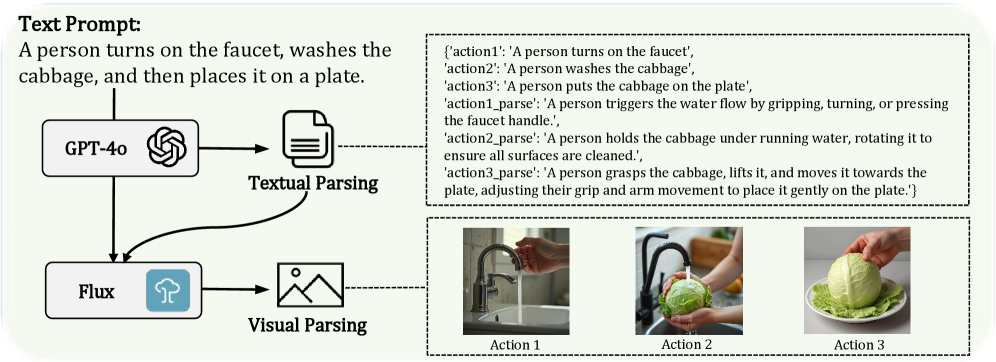
核心思路:论文的核心思路是利用多模态数据作为先验知识来指导HOI动作的生成。通过引入来自大型多模态模型(如文本、图像、姿势和物体)的信息,可以更好地约束生成过程,从而生成更自然、更真实的HOI动作。此外,论文还通过增强物体表示和设计多模态特征融合方法来进一步提高生成质量。
技术框架:MP-HOI框架包含以下几个主要模块:1) 多模态数据先验模块:利用大型多模态模型提取文本、图像、姿势和物体的特征作为先验知识。2) 增强的物体表示模块:通过结合几何关键点、接触特征和动态属性来改进物体表示。3) 多模态感知的混合专家(MoE)模型:用于融合来自不同模态的特征。4) 级联扩散模块:逐步细化人-物交互特征,并使用交互监督来提高交互质量。整个框架采用级联扩散的方式,逐步优化生成结果。
关键创新:论文的关键创新在于以下几个方面:1) 引入多模态数据先验来指导HOI动作生成,从而解决了跨模态鸿沟问题。2) 提出了增强的物体表示方法,可以更准确地描述物体的几何形状、接触状态和动态属性。3) 设计了多模态感知的混合专家(MoE)模型,可以有效地融合来自不同模态的特征。4) 采用了级联扩散框架,可以逐步细化生成结果,并使用交互监督来提高交互质量。
关键设计:在多模态数据先验模块中,使用了预训练的大型多模态模型来提取特征。在增强的物体表示模块中,使用了几何关键点、接触特征和动态属性来描述物体。在多模态感知的混合专家(MoE)模型中,使用了多个专家网络来处理来自不同模态的特征,并使用门控机制来选择合适的专家。在级联扩散模块中,使用了扩散模型来逐步细化生成结果,并使用交互损失函数来监督交互质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MP-HOI在生成高质量和细粒度的人-物交互动作方面显著优于现有方法。具体来说,MP-HOI在多个指标上都取得了最佳性能,例如,在动作真实性、物体运动自然性和交互质量等方面都优于现有方法。这些结果验证了MP-HOI框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、机器人控制等领域。例如,可以根据文本描述自动生成虚拟人物与物体的交互动画,提升虚拟现实体验的真实感和沉浸感。在机器人控制领域,可以根据指令生成机器人与环境的交互动作,实现更智能、更自然的机器人行为。
📄 摘要(原文)
We address the challenging task of text-driven 3D human-object interaction (HOI) motion generation. Existing methods primarily rely on a direct text-to-HOI mapping, which suffers from three key limitations due to the significant cross-modality gap: (Q1) sub-optimal human motion, (Q2) unnatural object motion, and (Q3) weak interaction between humans and objects. To address these challenges, we propose MP-HOI, a novel framework grounded in four core insights: (1) Multimodal Data Priors: We leverage multimodal data (text, image, pose/object) from large multimodal models as priors to guide HOI generation, which tackles Q1 and Q2 in data modeling. (2) Enhanced Object Representation: We improve existing object representations by incorporating geometric keypoints, contact features, and dynamic properties, enabling expressive object representations, which tackles Q2 in data representation. (3) Multimodal-Aware Mixture-of-Experts (MoE) Model: We propose a modality-aware MoE model for effective multimodal feature fusion paradigm, which tackles Q1 and Q2 in feature fusion. (4) Cascaded Diffusion with Interaction Supervision: We design a cascaded diffusion framework that progressively refines human-object interaction features under dedicated supervision, which tackles Q3 in interaction refinement. Comprehensive experiments demonstrate that MP-HOI outperforms existing approaches in generating high-fidelity and fine-grained HOI motions.