VideoSTF: Stress-Testing Output Repetition in Video Large Language Models
作者: Yuxin Cao, Wei Song, Shangzhi Xu, Jingling Xue, Jin Song Dong
分类: cs.CV, cs.CR, cs.MM
发布日期: 2026-02-11
🔗 代码/项目: GITHUB
💡 一句话要点
VideoSTF:提出用于评估视频大语言模型中输出重复问题的基准测试框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 输出重复 稳定性测试 时间扰动 对抗攻击
📋 核心要点
- 现有VideoLLM基准测试主要关注准确性和事实性,忽略了模型生成时可能出现的输出重复问题。
- VideoSTF框架通过定义基于n-gram的指标和构建包含时间变换的测试集,系统性地评估输出重复问题。
- 实验表明,输出重复在现有VideoLLM中普遍存在,且对视频的时间扰动非常敏感,存在安全漏洞。
📝 摘要(中文)
视频大语言模型(VideoLLMs)最近在视频理解任务中取得了显著的性能。然而,我们发现了一个先前未被充分探索的生成失败:严重的输出重复,即模型退化为重复短语或句子的自我强化循环。现有的VideoLLM基准测试主要关注任务准确性和事实正确性,并未捕捉到这种失败模式。我们引入了VideoSTF,这是第一个用于系统地测量和压力测试VideoLLM中输出重复的框架。VideoSTF使用三个互补的基于n-gram的指标来形式化重复,并提供了一个包含10,000个多样化视频的标准测试平台以及一个受控的时间变换库。使用VideoSTF,我们对10个先进的VideoLLM进行了普遍测试、时间压力测试和对抗性利用。我们发现输出重复现象普遍存在,并且关键的是,对视频输入的时间扰动高度敏感。此外,我们表明,简单的时序变换可以有效地诱导黑盒环境中的重复退化,从而将输出重复暴露为一种可利用的安全漏洞。我们的结果表明,输出重复是现代VideoLLM中一个根本的稳定性问题,并激发了对视频语言系统进行稳定性感知评估。我们的评估代码和脚本可在https://github.com/yuxincao22/VideoSTF_benchmark上找到。
🔬 方法详解
问题定义:论文旨在解决视频大语言模型(VideoLLM)中存在的输出重复问题。现有VideoLLM的评估基准主要关注任务准确性和事实正确性,忽略了模型生成文本时可能出现的重复短语或句子的现象,这种重复会严重影响生成质量和用户体验。
核心思路:论文的核心思路是构建一个专门用于评估和压力测试VideoLLM输出重复问题的框架VideoSTF。通过形式化定义重复指标,并提供包含多样化视频和时间变换的测试集,系统性地分析模型在不同情况下的重复生成行为。
技术框架:VideoSTF框架主要包含以下几个部分:1) 重复指标定义:使用三个基于n-gram的指标来量化输出重复程度。2) 多样化视频测试集:包含10,000个来自不同场景的视频。3) 时间变换库:提供一系列受控的时间变换,用于模拟视频输入中的时间扰动。4) 评估流程:使用定义的指标和测试集,对VideoLLM进行普遍测试、时间压力测试和对抗性利用。
关键创新:该论文的关键创新在于:1) 首次关注并系统性地研究了VideoLLM中的输出重复问题。2) 提出了VideoSTF框架,为评估和压力测试VideoLLM的输出重复提供了一个标准化的平台。3) 揭示了输出重复对视频时间扰动的敏感性,并将其暴露为一种潜在的安全漏洞。
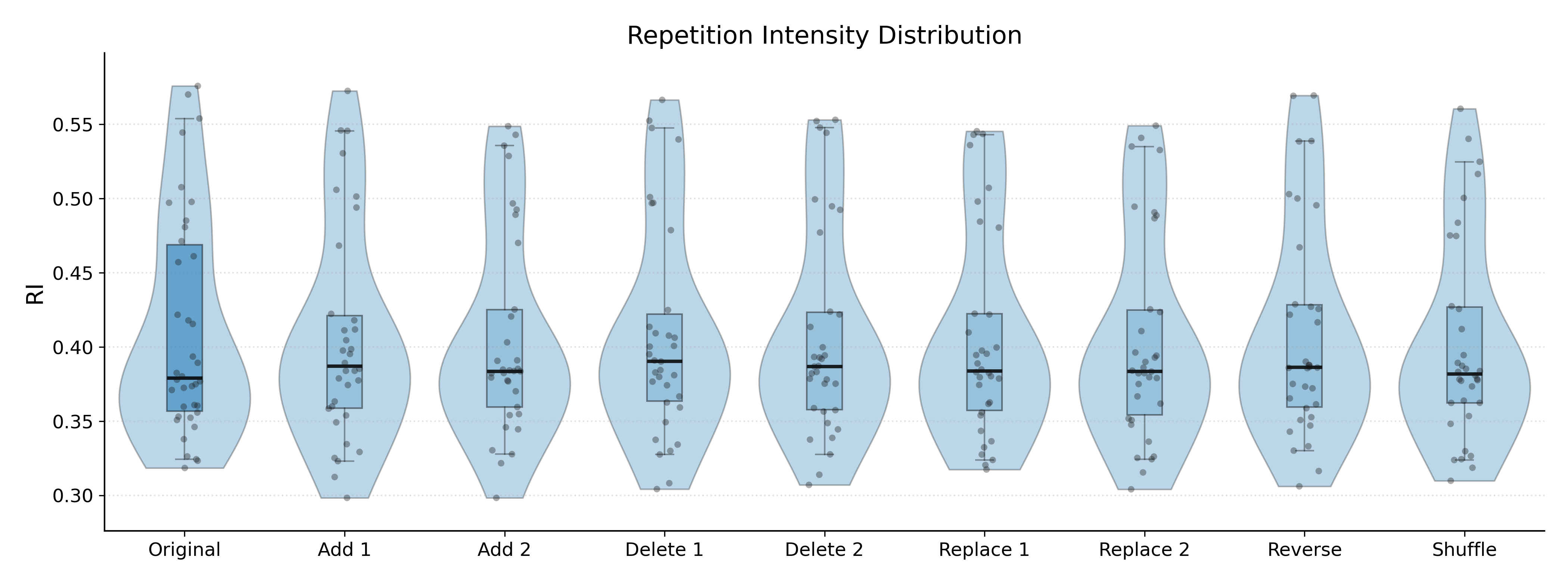
关键设计:VideoSTF的关键设计包括:1) 使用n-gram overlap, repetition ratio, 和 longest repeated span 三种指标来量化输出重复程度。2) 构建包含各种场景和主题的视频测试集,以保证评估的全面性。3) 设计一系列时间变换,如帧随机打乱、帧重复、视频倒放等,用于模拟视频输入中的时间扰动,并观察模型对这些扰动的鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有的VideoLLM普遍存在输出重复问题,且对视频的时间扰动非常敏感。通过简单的时序变换,可以有效地诱导模型产生重复的输出,甚至导致模型崩溃。例如,某些模型在经过时间扰动后,重复率显著增加,表明其在处理非标准时间序列视频时存在稳定性问题。
🎯 应用场景
该研究成果可应用于提升视频大语言模型的稳定性和可靠性,尤其是在需要生成长文本描述或故事的场景中,例如视频摘要、视频问答、视频内容创作等。通过使用VideoSTF进行评估和优化,可以有效减少模型生成重复文本的概率,提高用户体验,并增强模型抵抗对抗性攻击的能力。
📄 摘要(原文)
Video Large Language Models (VideoLLMs) have recently achieved strong performance in video understanding tasks. However, we identify a previously underexplored generation failure: severe output repetition, where models degenerate into self-reinforcing loops of repeated phrases or sentences. This failure mode is not captured by existing VideoLLM benchmarks, which focus primarily on task accuracy and factual correctness. We introduce VideoSTF, the first framework for systematically measuring and stress-testing output repetition in VideoLLMs. VideoSTF formalizes repetition using three complementary n-gram-based metrics and provides a standardized testbed of 10,000 diverse videos together with a library of controlled temporal transformations. Using VideoSTF, we conduct pervasive testing, temporal stress testing, and adversarial exploitation across 10 advanced VideoLLMs. We find that output repetition is widespread and, critically, highly sensitive to temporal perturbations of video inputs. Moreover, we show that simple temporal transformations can efficiently induce repetitive degeneration in a black-box setting, exposing output repetition as an exploitable security vulnerability. Our results reveal output repetition as a fundamental stability issue in modern VideoLLMs and motivate stability-aware evaluation for video-language systems. Our evaluation code and scripts are available at: https://github.com/yuxincao22/VideoSTF_benchmark.