MetaphorStar: Image Metaphor Understanding and Reasoning with End-to-End Visual Reinforcement Learning
作者: Chenhao Zhang, Yazhe Niu, Hongsheng Li
分类: cs.CV, cs.AI, cs.CY
发布日期: 2026-02-11
备注: 14 pages, 4 figures, 11 tables; Code: https://github.com/MING-ZCH/MetaphorStar, Model & Dataset: https://huggingface.co/collections/MING-ZCH/metaphorstar
💡 一句话要点
提出MetaphorStar,利用端到端视觉强化学习解决图像隐喻理解与推理难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像隐喻理解 视觉强化学习 多模态学习 视觉推理 心智理论 数据集 基准测试
📋 核心要点
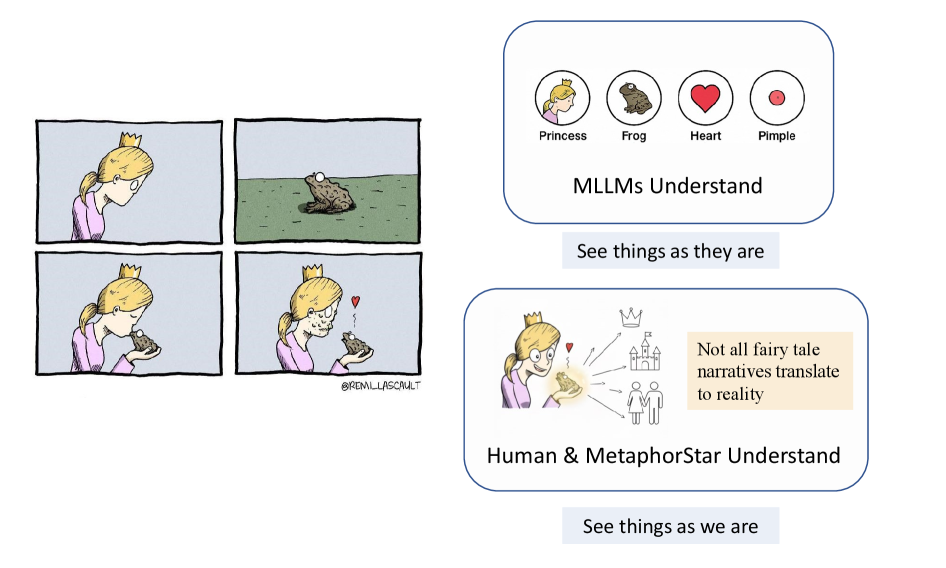
- 现有MLLM难以理解图像中蕴含的文化、情感和语境含义,缺乏复杂推理和心智理论能力。
- 提出MetaphorStar,一个端到端视觉强化学习框架,包含数据集、RL方法和基准测试,用于图像隐喻理解。
- MetaphorStar在图像隐喻基准测试中性能平均提高82.6%,并在多项选择和开放式问题上达到SOTA。
📝 摘要(中文)
图像隐喻理解对于当前人工智能系统来说仍然是一个关键挑战。尽管多模态大型语言模型(MLLM)在基础视觉问答(VQA)方面表现出色,但它们始终难以掌握视觉内容中蕴含的细微文化、情感和语境含义。这种困难源于该任务对复杂的多跳推理、文化背景和心智理论(ToM)能力的需求,而当前模型缺乏这些能力。为了填补这一空白,我们提出了MetaphorStar,这是第一个用于图像隐喻任务的端到端视觉强化学习(RL)框架。我们的框架包括三个核心组件:细粒度数据集TFQ-Data,视觉RL方法TFQ-GRPO,以及结构良好的基准TFQ-Bench。我们完全开源的MetaphorStar系列,使用TFQ-GRPO在TFQ-Data上训练,在图像隐喻基准测试中,性能平均提高了82.6%。与20多个主流MLLM相比,MetaphorStar-32B在多项选择题和开放式问题上达到了最先进水平(SOTA),并在真假题上显著优于顶级闭源模型Gemini-3.0-pro。至关重要的是,我们的实验表明,学习图像隐喻任务可以提高通用理解能力,尤其是复杂的视觉推理能力。我们进一步系统地分析了模型参数缩放、训练数据缩放以及不同模型架构和训练策略的影响,证明了我们方法的广泛适用性。我们开源了所有模型权重、数据集和方法代码。
🔬 方法详解
问题定义:论文旨在解决图像隐喻理解与推理问题,即让AI系统能够理解图像中蕴含的深层含义,包括文化、情感和语境信息。现有方法,特别是多模态大型语言模型(MLLMs),在处理这类问题时表现不佳,因为它们缺乏复杂的多跳推理、文化背景知识和心智理论能力。现有方法难以捕捉图像中细微的隐喻信息,导致理解偏差或错误。
核心思路:论文的核心思路是利用视觉强化学习(RL)来训练模型,使其能够通过与环境的交互逐步学习图像隐喻的理解和推理。通过奖励机制,鼓励模型学习如何从图像中提取关键信息,并进行多步推理,最终理解图像的隐喻含义。这种方法模拟了人类学习隐喻的过程,即通过观察、思考和反馈来逐步掌握。
技术框架:MetaphorStar框架包含三个主要组件:1) TFQ-Data:一个细粒度的图像隐喻数据集,用于训练和评估模型;2) TFQ-GRPO:一种视觉强化学习方法,用于训练模型理解图像隐喻;3) TFQ-Bench:一个结构化的基准测试,用于评估模型在图像隐喻理解任务上的性能。TFQ-GRPO方法通过与环境交互,根据奖励信号调整策略,从而学习如何理解图像隐喻。
关键创新:该论文的关键创新在于提出了第一个端到端视觉强化学习框架用于图像隐喻理解。与传统的基于监督学习的方法不同,该框架能够通过与环境的交互自主学习,从而更好地捕捉图像中蕴含的复杂信息。此外,该框架还引入了细粒度的数据集和结构化的基准测试,为图像隐喻理解的研究提供了有力的支持。
关键设计:TFQ-GRPO方法的具体设计细节包括:奖励函数的设计,用于引导模型学习正确的隐喻理解;状态表示的设计,用于将图像信息编码成适合RL算法处理的形式;动作空间的设计,用于定义模型可以采取的推理步骤。此外,论文还对模型参数缩放、训练数据缩放以及不同模型架构和训练策略的影响进行了详细的实验分析,为模型的优化提供了指导。
🖼️ 关键图片

📊 实验亮点
MetaphorStar在图像隐喻基准测试中取得了显著的性能提升,平均提高了82.6%。与20多个主流MLLM相比,MetaphorStar-32B在多项选择题和开放式问题上达到了SOTA,并在真假题上显著优于Gemini-3.0-pro。实验还表明,学习图像隐喻任务可以提高通用理解能力,特别是复杂的视觉推理能力。
🎯 应用场景
该研究成果可应用于多个领域,例如智能图像搜索、情感分析、文化遗产保护和教育。通过提升AI系统对图像隐喻的理解能力,可以改善人机交互体验,提高信息检索的准确性,并促进跨文化交流。未来,该技术有望应用于创意设计、广告营销等领域,帮助人们更好地理解和利用图像的表达能力。
📄 摘要(原文)
Metaphorical comprehension in images remains a critical challenge for Nowadays AI systems. While Multimodal Large Language Models (MLLMs) excel at basic Visual Question Answering (VQA), they consistently struggle to grasp the nuanced cultural, emotional, and contextual implications embedded in visual content. This difficulty stems from the task's demand for sophisticated multi-hop reasoning, cultural context, and Theory of Mind (ToM) capabilities, which current models lack. To fill this gap, we propose MetaphorStar, the first end-to-end visual reinforcement learning (RL) framework for image implication tasks. Our framework includes three core components: the fine-grained dataset TFQ-Data, the visual RL method TFQ-GRPO, and the well-structured benchmark TFQ-Bench. Our fully open-source MetaphorStar family, trained using TFQ-GRPO on TFQ-Data, significantly improves performance by an average of 82.6% on the image implication benchmarks. Compared with 20+ mainstream MLLMs, MetaphorStar-32B achieves state-of-the-art (SOTA) on Multiple-Choice Question and Open-Style Question, significantly outperforms the top closed-source model Gemini-3.0-pro on True-False Question. Crucially, our experiments reveal that learning image implication tasks improves the general understanding ability, especially the complex visual reasoning ability. We further provide a systematic analysis of model parameter scaling, training data scaling, and the impact of different model architectures and training strategies, demonstrating the broad applicability of our method. We open-sourced all model weights, datasets, and method code at https://metaphorstar.github.io.