C^2ROPE: Causal Continuous Rotary Positional Encoding for 3D Large Multimodal-Models Reasoning
作者: Guanting Ye, Qiyan Zhao, Wenhao Yu, Xiaofeng Zhang, Jianmin Ji, Yanyong Zhang, Ka-Veng Yuen
分类: cs.CV, cs.AI
发布日期: 2026-02-11
备注: Accepted in ICRA 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出C^2RoPE,解决3D多模态大模型推理中RoPE的位置编码局限性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D多模态大模型 位置编码 旋转位置编码 空间连续性 因果关系 视觉推理 3D视觉问答
📋 核心要点
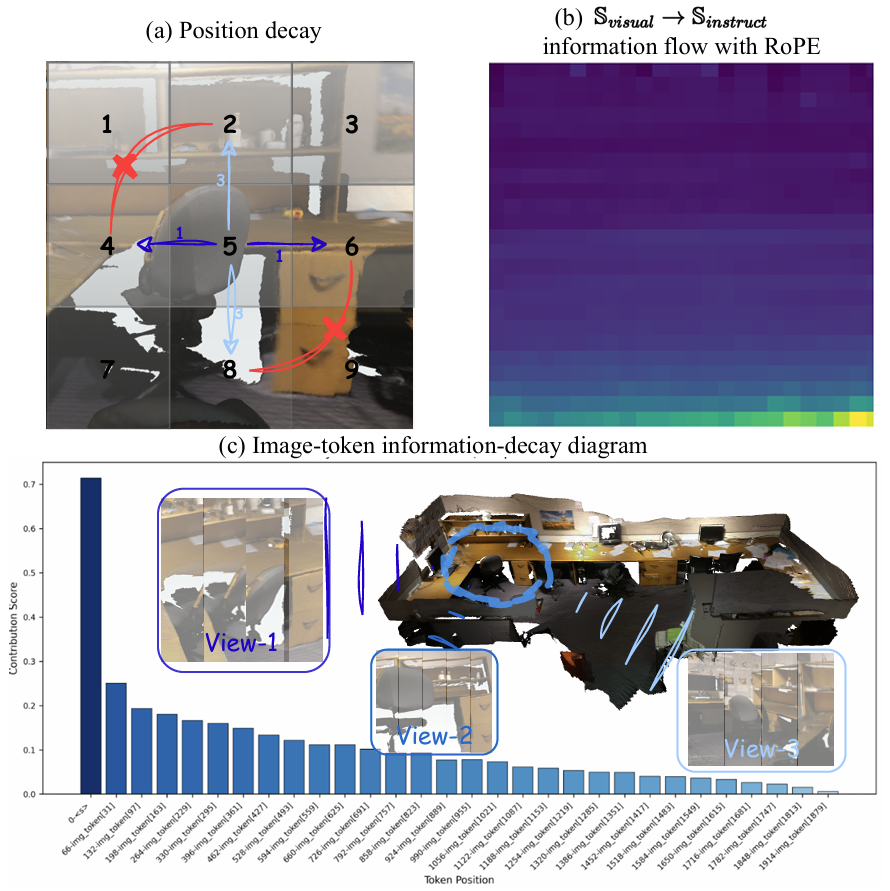
- 现有3D多模态大模型中的RoPE位置编码破坏了视觉特征在列维度上的连续性,导致空间局部性损失。
- C^2RoPE通过构建混合位置索引三元组,并采用频率分配策略编码时空位置信息,显式建模局部空间连续性和空间因果关系。
- 实验结果表明,C^2RoPE在3D场景推理和3D视觉问答等任务上表现出有效性,验证了其性能。
📝 摘要(中文)
本文针对3D大语言模型(LLM)中基于旋转位置编码(RoPE)的3D视觉特征与LLM表示对齐方法的局限性,提出了一种改进的RoPE方法C^2RoPE,用于显式建模视觉处理中的局部空间连续性和空间因果关系。C^2RoPE为视觉tokens引入了一种时空连续的位置嵌入机制,首先将一维时间位置与基于笛卡尔坐标的空间坐标相结合,构建混合位置索引三元组,然后采用频率分配策略对三个索引分量中的时空位置信息进行编码。此外,本文还引入了切比雪夫因果掩码,通过计算图像tokens在2D空间中的切比雪夫距离来确定因果依赖关系。在包括3D场景推理和3D视觉问答在内的多个基准测试上的评估结果表明了C^2RoPE的有效性。代码可在https://github.com/ErikZ719/C2RoPE 获取。
🔬 方法详解
问题定义:现有基于RoPE的3D多模态大模型在处理视觉信息时存在局限性。RoPE将1D时间位置索引应用于图像tokens,破坏了视觉特征在列维度上的连续性,导致空间局部性损失。此外,RoPE假设时间上更接近的图像tokens在因果关系上更相关,导致注意力分配的长期衰减,使得模型逐渐忽略较早的视觉tokens,影响长序列建模能力。
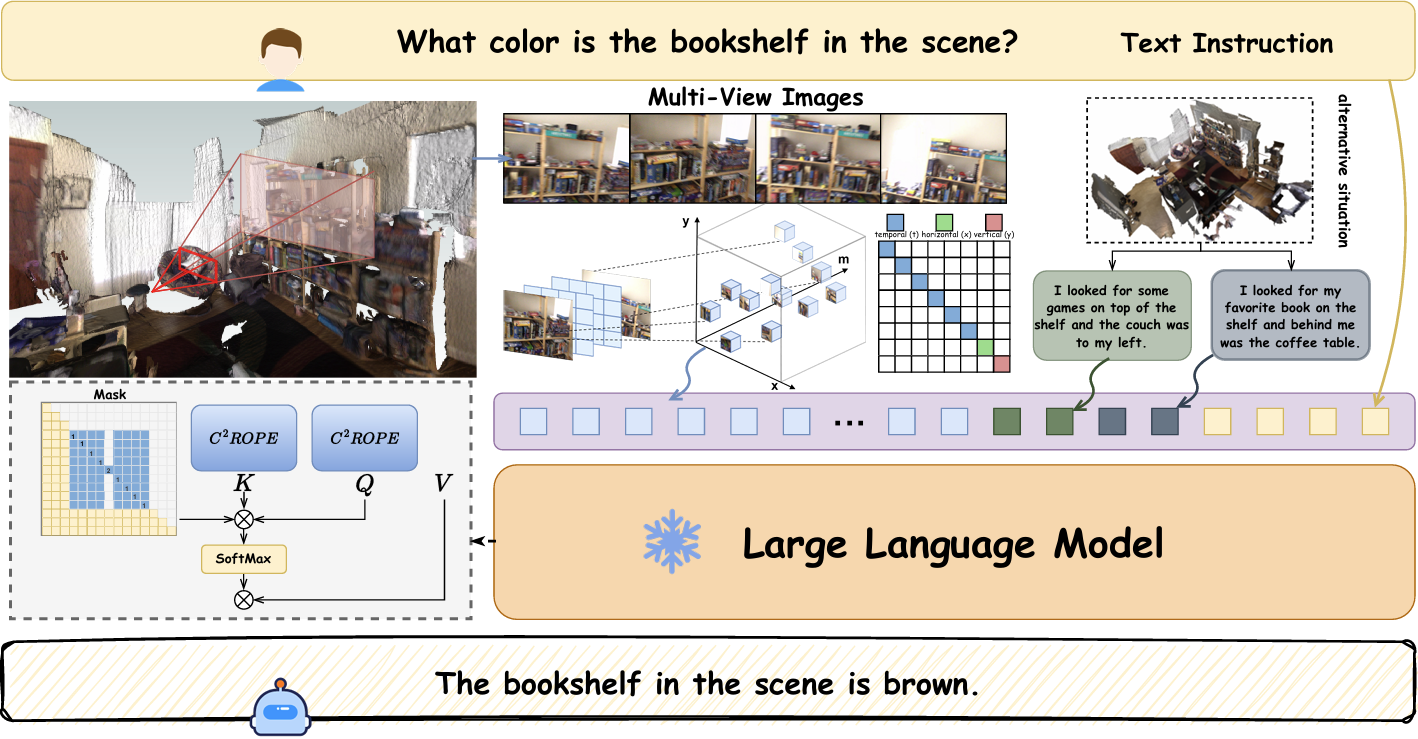
核心思路:C^2RoPE的核心思路是显式地建模视觉tokens之间的局部空间连续性和空间因果关系。通过引入时空连续的位置嵌入机制,将时间位置信息与空间坐标信息相结合,构建混合位置索引,从而保留视觉特征的空间连续性。同时,利用切比雪夫距离来确定tokens之间的因果依赖关系,避免了RoPE中基于时间距离的因果关系假设。
技术框架:C^2RoPE主要包含两个关键模块:时空连续位置编码和切比雪夫因果掩码。首先,将1D时间位置与基于笛卡尔坐标的空间坐标融合,构建混合位置索引三元组。然后,采用频率分配策略对三个索引分量中的时空位置信息进行编码。其次,引入切比雪夫因果掩码,通过计算图像tokens在2D空间中的切比雪夫距离来确定因果依赖关系,用于注意力机制中的掩码操作。
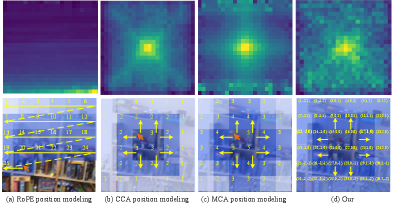
关键创新:C^2RoPE的关键创新在于其显式地建模了视觉tokens之间的局部空间连续性和空间因果关系。与传统的RoPE方法相比,C^2RoPE不再依赖于时间距离来确定因果关系,而是通过计算空间距离来建模tokens之间的依赖关系,更符合视觉信息的特点。此外,混合位置索引的设计能够更好地融合时空信息,保留视觉特征的空间连续性。
关键设计:在时空连续位置编码中,频率分配策略是一个关键的设计。通过合理地分配不同频率给时间和空间坐标,可以更好地平衡时空信息的重要性。切比雪夫因果掩码中,切比雪夫距离的选择也是一个关键设计,因为它能够更好地反映图像tokens之间的空间关系。具体的参数设置和网络结构细节需要在实际应用中进行调整和优化。
🖼️ 关键图片
📊 实验亮点
论文在3D场景推理和3D视觉问答等多个基准测试上验证了C^2RoPE的有效性。实验结果表明,C^2RoPE能够显著提升模型的性能,尤其是在需要长序列建模的任务中。具体的性能提升数据需要在论文中查找,但总体而言,C^2RoPE提供了一种更有效的3D多模态大模型位置编码方法。
🎯 应用场景
C^2RoPE在3D场景理解、机器人导航、自动驾驶等领域具有广泛的应用前景。通过提升3D多模态大模型对视觉信息的理解能力,可以提高这些应用场景中的决策和控制精度。例如,在机器人导航中,C^2RoPE可以帮助机器人更好地理解周围环境,从而规划出更安全、更高效的路径。在自动驾驶中,C^2RoPE可以提高车辆对交通场景的感知能力,从而减少交通事故的发生。
📄 摘要(原文)
Recent advances in 3D Large Multimodal Models (LMMs) built on Large Language Models (LLMs) have established the alignment of 3D visual features with LLM representations as the dominant paradigm. However, the inherited Rotary Position Embedding (RoPE) introduces limitations for multimodal processing. Specifically, applying 1D temporal positional indices disrupts the continuity of visual features along the column dimension, resulting in spatial locality loss. Moreover, RoPE follows the prior that temporally closer image tokens are more causally related, leading to long-term decay in attention allocation and causing the model to progressively neglect earlier visual tokens as the sequence length increases. To address these issues, we propose C^2RoPE, an improved RoPE that explicitly models local spatial Continuity and spatial Causal relationships for visual processing. C^2RoPE introduces a spatio-temporal continuous positional embedding mechanism for visual tokens. It first integrates 1D temporal positions with Cartesian-based spatial coordinates to construct a triplet hybrid positional index, and then employs a frequency allocation strategy to encode spatio-temporal positional information across the three index components. Additionally, we introduce Chebyshev Causal Masking, which determines causal dependencies by computing the Chebyshev distance of image tokens in 2D space. Evaluation results across various benchmarks, including 3D scene reasoning and 3D visual question answering, demonstrate C^2RoPE's effectiveness. The code is be available at https://github.com/ErikZ719/C2RoPE.