Enhancing Weakly Supervised Multimodal Video Anomaly Detection through Text Guidance
作者: Shengyang Sun, Jiashen Hua, Junyi Feng, Xiaojin Gong
分类: cs.CV, cs.AI
发布日期: 2026-02-11
备注: Accepted by IEEE Transactions on Multimedia
💡 一句话要点
提出文本引导的弱监督多模态视频异常检测框架,提升异常特征表达。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频异常检测 弱监督学习 多模态融合 文本引导 上下文学习
📋 核心要点
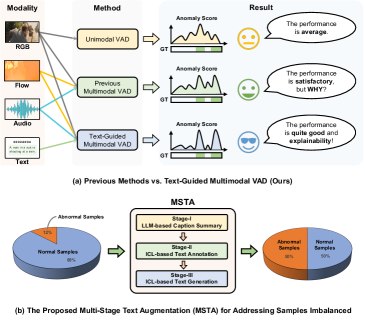
- 现有弱监督多模态视频异常检测方法对文本模态利用不足,难以有效提取异常相关语义信息。
- 提出一种文本引导框架,通过上下文学习增强文本特征,并使用瓶颈Transformer进行多模态融合。
- 在UCF-Crime和XD-Violence数据集上实验表明,该方法取得了state-of-the-art的性能。
📝 摘要(中文)
弱监督多模态视频异常检测日益受到关注,但文本模态的潜力尚未充分挖掘。文本提供了明确的语义信息,可以增强异常特征的表征并减少误报。然而,由于通用语言模型无法捕捉异常特定的细微差别以及相关描述的稀缺性,提取有效的文本特征具有挑战性。此外,多模态融合通常存在冗余和不平衡问题。为了解决这些问题,我们提出了一种新颖的文本引导框架。首先,我们引入了一种基于上下文学习的多阶段文本增强机制,以生成高质量的异常文本样本,用于微调文本特征提取器。其次,我们设计了一个多尺度瓶颈Transformer融合模块,该模块使用压缩的瓶颈tokens来逐步整合跨模态的信息,从而减轻冗余和不平衡。在UCF-Crime和XD-Violence上的实验表明,该方法达到了最先进的性能。
🔬 方法详解
问题定义:现有的弱监督多模态视频异常检测方法,尤其是在利用文本模态时,面临着两个主要问题。一是通用语言模型难以捕捉到异常事件的细微语义差别,导致提取的文本特征不够有效。二是多模态融合过程中,不同模态的信息可能存在冗余和不平衡,影响最终的异常检测性能。
核心思路:论文的核心思路是通过文本引导来增强多模态视频异常检测。具体来说,首先利用上下文学习生成高质量的异常文本描述,用于微调文本特征提取器,使其更好地捕捉异常事件的语义信息。然后,设计一个多尺度瓶颈Transformer融合模块,通过压缩的瓶颈tokens逐步整合不同模态的信息,从而减轻冗余和不平衡。
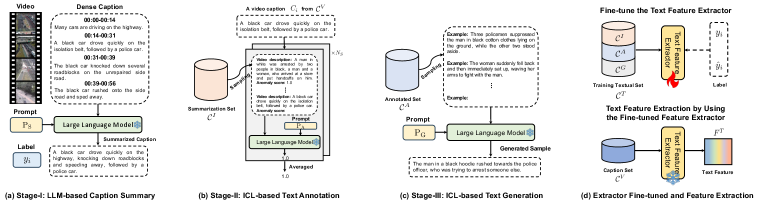
技术框架:该框架主要包含两个阶段。第一阶段是文本增强阶段,利用in-context learning的多阶段文本增强机制生成异常文本样本,用于微调文本特征提取器。第二阶段是多模态融合阶段,使用多尺度瓶颈Transformer融合模块,将视频和文本特征进行融合,最终用于异常检测。
关键创新:该论文的关键创新点在于:1) 提出了基于上下文学习的多阶段文本增强机制,能够生成高质量的异常文本样本,有效提升了文本特征提取器的性能。2) 设计了多尺度瓶颈Transformer融合模块,通过压缩的瓶颈tokens逐步整合不同模态的信息,有效减轻了冗余和不平衡问题。
关键设计:在文本增强阶段,使用了多阶段的in-context learning方法,具体细节未知。在多模态融合阶段,使用了Transformer结构,并引入了瓶颈tokens来压缩信息,具体参数设置未知。损失函数的设计也未知。
🖼️ 关键图片

📊 实验亮点
该方法在UCF-Crime和XD-Violence数据集上取得了state-of-the-art的性能。具体提升幅度未知,但表明该方法在弱监督多模态视频异常检测方面具有显著优势。文本引导策略和瓶颈Transformer融合模块的有效性得到了验证。
🎯 应用场景
该研究成果可应用于智能监控、公共安全等领域,例如在视频监控系统中自动检测异常事件,如打架斗殴、盗窃等,从而提高安全防范能力。此外,该方法还可以扩展到其他多模态异常检测任务中,例如医疗影像分析、工业故障诊断等。
📄 摘要(原文)
Weakly supervised multimodal video anomaly detection has gained significant attention, yet the potential of the text modality remains under-explored. Text provides explicit semantic information that can enhance anomaly characterization and reduce false alarms. However, extracting effective text features is challenging due to the inability of general-purpose language models to capture anomaly-specific nuances and the scarcity of relevant descriptions. Furthermore, multimodal fusion often suffers from redundancy and imbalance. To address these issues, we propose a novel text-guided framework. First, we introduce an in-context learning-based multi-stage text augmentation mechanism to generate high-quality anomaly text samples for fine-tuning the text feature extractor. Second, we design a multi-scale bottleneck Transformer fusion module that uses compressed bottleneck tokens to progressively integrate information across modalities, mitigating redundancy and imbalance. Experiments on UCF-Crime and XD-Violence demonstrate state-of-the-art performance.