HII-DPO: Eliminate Hallucination via Accurate Hallucination-Inducing Counterfactual Images
作者: Yilin Yang, Zhenghui Guo, Yuke Wang, Omprakash Gnawali, Sheng Di, Chengming Zhang
分类: cs.CV
发布日期: 2026-02-11
💡 一句话要点
提出HII-DPO,通过对抗图像消除视觉语言模型中的幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 幻觉消除 对抗图像 语言偏差 偏好学习
📋 核心要点
- 现有视觉语言模型易受语言偏差影响,产生幻觉,现有方法未能充分解决这一问题。
- 通过合成诱导幻觉的图像(HIIs),揭示模型在特定场景下倾向于提及典型对象的幻觉模式。
- 构建MOH基准评估模型对幻觉的敏感性,并利用HIIs构建偏好数据集进行微调,显著缓解幻觉。
📝 摘要(中文)
大型视觉语言模型(VLMs)在各种多模态任务中取得了显著成功,但仍然容易受到源于固有语言偏差的幻觉影响。尽管最近取得了一些进展,但现有的幻觉缓解方法通常忽略了由语言偏差驱动的潜在幻觉模式。本文设计了一种新颖的流程,用于准确合成诱导幻觉的图像(HIIs)。利用合成的HIIs,我们揭示了一种一致的场景条件幻觉模式:即使视觉证据被移除,模型也倾向于提及场景中高度典型的对象。为了量化VLMs对这种幻觉模式的敏感性,我们建立了Masked-Object-Hallucination(MOH)基准,以严格评估现有的最先进的对齐框架。最后,我们利用HIIs构建高质量的偏好数据集,用于细粒度的对齐。实验结果表明,我们的方法有效地缓解了幻觉,同时保留了一般的模型能力。具体而言,我们的方法在标准幻觉基准上实现了比当前最先进技术高达38%的改进。
🔬 方法详解
问题定义:视觉语言模型(VLMs)在多模态任务中表现出色,但存在幻觉问题,即模型在没有视觉证据的情况下生成与图像内容不符的信息。现有方法未能充分解决由语言偏差驱动的幻觉模式,导致缓解效果有限。
核心思路:通过生成专门设计的、能够诱导模型产生幻觉的图像(Hallucination-Inducing Images, HIIs),来揭示和利用模型固有的语言偏差。然后,利用这些HIIs构建高质量的偏好数据集,通过微调来纠正模型的偏差。
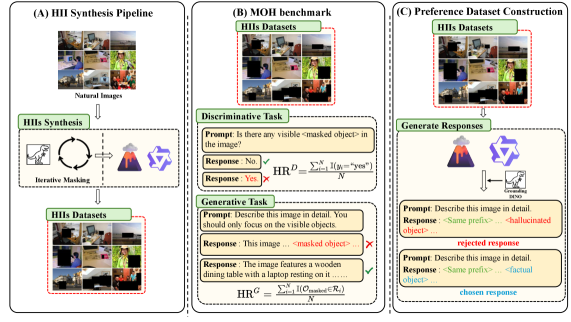
技术框架:该方法包含三个主要阶段:1) HII生成:设计一种流程来合成HIIs,这些图像旨在诱导模型产生特定的幻觉。2) MOH基准测试:建立Masked-Object-Hallucination (MOH) 基准,用于评估模型对特定幻觉模式的敏感性。3) HII-DPO微调:利用HIIs构建的偏好数据集,使用Direct Preference Optimization (DPO) 算法对模型进行微调,以减少幻觉。
关键创新:该方法的核心创新在于准确合成HIIs,并利用这些图像揭示了VLMs中一种一致的、场景条件下的幻觉模式。与以往方法不同,该方法直接针对语言偏差导致的幻觉模式进行干预,而不是简单地增加视觉信息的权重。
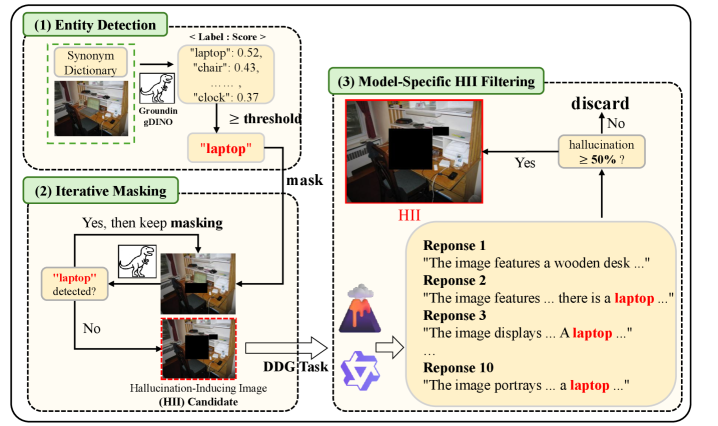
关键设计:HII生成过程的关键在于控制图像的内容,使其在视觉上缺乏特定对象,但场景的上下文暗示了该对象的存在。MOH基准通过掩盖图像中的特定对象来评估模型是否会产生幻觉。HII-DPO微调使用DPO算法,通过比较模型在原始图像和HII上的输出,来优化模型的偏好,从而减少幻觉。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在标准幻觉基准上实现了高达38%的性能提升,显著优于当前最先进的方法。同时,该方法在缓解幻觉的同时,能够保持模型的一般能力,避免了性能下降。
🎯 应用场景
该研究成果可应用于提升视觉语言模型在图像描述、视觉问答等任务中的可靠性和准确性。通过减少幻觉,可以提高模型在安全监控、自动驾驶、医疗诊断等领域的应用价值,并增强人机交互的信任度。
📄 摘要(原文)
Large Vision-Language Models (VLMs) have achieved remarkable success across diverse multimodal tasks but remain vulnerable to hallucinations rooted in inherent language bias. Despite recent progress, existing hallucination mitigation methods often overlook the underlying hallucination patterns driven by language bias. In this work, we design a novel pipeline to accurately synthesize Hallucination-Inducing Images (HIIs). Using synthesized HIIs, we reveal a consistent scene-conditioned hallucination pattern: models tend to mention objects that are highly typical of the scene even when visual evidence is removed. To quantify the susceptibility of VLMs to this hallucination pattern, we establish the Masked-Object-Hallucination (MOH) benchmark to rigorously evaluate existing state-of-the-art alignment frameworks. Finally, we leverage HIIs to construct high-quality preference datasets for fine-grained alignment. Experimental results demonstrate that our approach effectively mitigates hallucinations while preserving general model capabilities. Specifically, our method achieves up to a 38% improvement over the current state-of-the-art on standard hallucination benchmarks.