Fake-HR1: Rethinking reasoning of vision language model for synthetic image detection
作者: Changjiang Jiang, Xinkuan Sha, Fengchang Yu, Jingjing Liu, Jian Liu, Mingqi Fang, Chenfeng Zhang, Wei Lu
分类: cs.CV, cs.AI
发布日期: 2026-02-10
备注: Accepted by ICASSP 2026
💡 一句话要点
提出Fake-HR1,自适应推理检测合成图像,提升效率与性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成图像检测 自适应推理 链式思考 强化学习 混合推理 大型语言模型 生成式模型检测
📋 核心要点
- 现有方法过度依赖链式思考推理,导致检测合成图像时资源开销大,效率低,尤其是在处理明显伪造的图像时。
- Fake-HR1通过混合推理机制,自适应地判断是否需要推理,从而在保证检测性能的同时,降低资源消耗。
- 实验表明,Fake-HR1在推理能力、生成检测性能和响应效率方面均优于现有大型语言模型。
📝 摘要(中文)
本文提出Fake-HR1,一种大规模混合推理模型,旨在根据生成检测任务的特点自适应地决定是否需要进行推理。该模型通过两阶段训练框架实现:首先进行混合微调(HFT)以进行冷启动初始化,然后通过在线强化学习与混合推理分组策略优化(HGRPO)隐式地学习何时选择合适的推理模式。实验结果表明,Fake-HR1能够自适应地对不同类型的查询执行推理,在推理能力和生成检测性能方面均优于现有的LLM,同时显著提高了响应效率。
🔬 方法详解
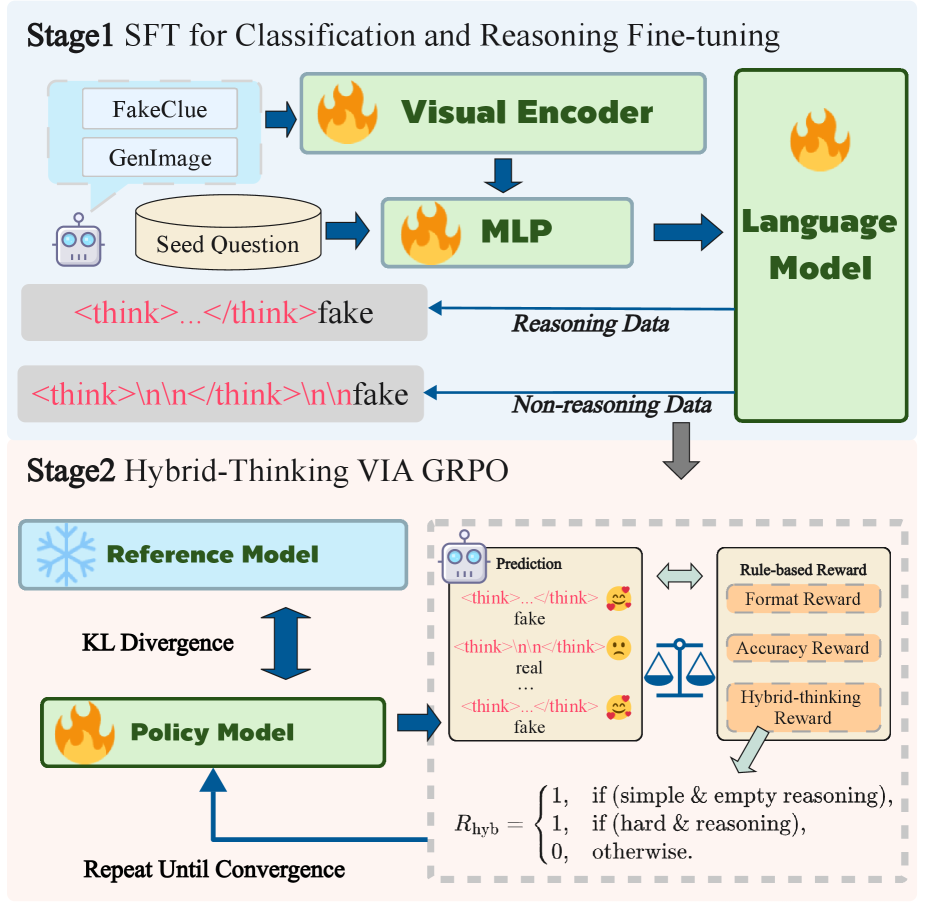
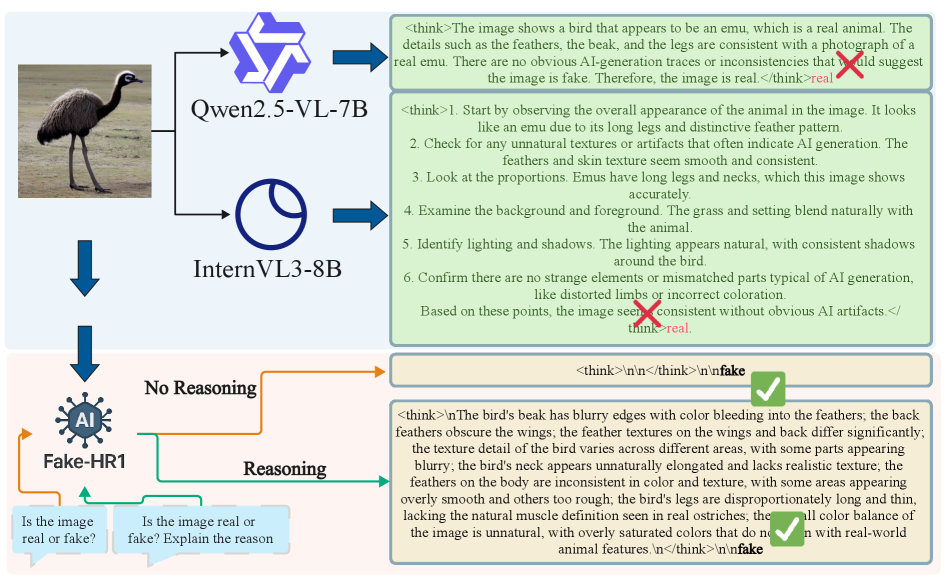
问题定义:现有基于链式思考(CoT)的合成图像检测方法,在处理所有图像时都进行冗长的推理,导致不必要的计算资源消耗和延迟,尤其是在处理容易识别的合成图像时。因此,需要一种方法能够根据图像的难易程度自适应地选择是否进行推理,从而提高效率。
核心思路:Fake-HR1的核心思路是让模型学会根据输入图像的特征,判断是否需要进行复杂的推理。对于容易识别的图像,直接给出结果;对于难以判断的图像,则进行链式思考推理。这种自适应的推理方式可以在保证检测准确率的同时,显著降低计算成本。
技术框架:Fake-HR1采用两阶段训练框架。第一阶段是混合微调(HFT),使用包含不同推理深度的样本进行训练,使模型具备初步的混合推理能力。第二阶段是使用混合推理分组策略优化(HGRPO)的在线强化学习,通过奖励机制鼓励模型选择更高效的推理策略。HGRPO将相似的样本分组,并对每个组应用不同的推理策略,从而提高学习效率。
关键创新:Fake-HR1的关键创新在于其自适应推理机制,能够根据输入图像的特征动态选择推理模式。与传统的CoT方法不同,Fake-HR1不是对所有图像都进行推理,而是只对需要推理的图像进行推理,从而显著提高了效率。此外,HGRPO通过分组策略优化,加速了强化学习的收敛。
关键设计:HFT阶段使用混合数据集进行微调,数据集包含直接预测和链式思考推理两种类型的样本。HGRPO阶段,奖励函数的设计至关重要,需要平衡检测准确率和推理成本。具体来说,如果模型正确检测出合成图像,则给予奖励;如果模型错误检测或进行了不必要的推理,则给予惩罚。推理成本可以通过推理步数或token数量来衡量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Fake-HR1在合成图像检测任务中,不仅在推理能力和检测性能上超越了现有的大型语言模型,而且显著提升了响应效率。具体数据未知,但强调了性能超越现有LLM,并显著提高了效率。
🎯 应用场景
Fake-HR1可应用于各种需要检测合成图像的场景,例如社交媒体内容审核、新闻真实性验证、金融欺诈检测等。该研究有助于提高AI系统的安全性和可靠性,减少虚假信息传播,并提升相关应用的效率和用户体验。未来,该方法可以扩展到其他需要自适应推理的任务中。
📄 摘要(原文)
Recent studies have demonstrated that incorporating Chain-of-Thought (CoT) reasoning into the detection process can enhance a model's ability to detect synthetic images. However, excessively lengthy reasoning incurs substantial resource overhead, including token consumption and latency, which is particularly redundant when handling obviously generated forgeries. To address this issue, we propose Fake-HR1, a large-scale hybrid-reasoning model that, to the best of our knowledge, is the first to adaptively determine whether reasoning is necessary based on the characteristics of the generative detection task. To achieve this, we design a two-stage training framework: we first perform Hybrid Fine-Tuning (HFT) for cold-start initialization, followed by online reinforcement learning with Hybrid-Reasoning Grouped Policy Optimization (HGRPO) to implicitly learn when to select an appropriate reasoning mode. Experimental results show that Fake-HR1 adaptively performs reasoning across different types of queries, surpassing existing LLMs in both reasoning ability and generative detection performance, while significantly improving response efficiency.