VersaViT: Enhancing MLLM Vision Backbones via Task-Guided Optimization
作者: Yikun Liu, Yuan Liu, Shangzhe Di, Haicheng Wang, Zhongyin Zhao, Le Tian, Xiao Zhou, Jie Zhou, Jiangchao Yao, Yanfeng Wang, Weidi Xie
分类: cs.CV
发布日期: 2026-02-10
💡 一句话要点
VersaViT:通过任务引导优化增强MLLM视觉骨干网络
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉骨干网络 多任务学习 密集预测 语义分割 深度估计 视觉语言理解 Transformer
📋 核心要点
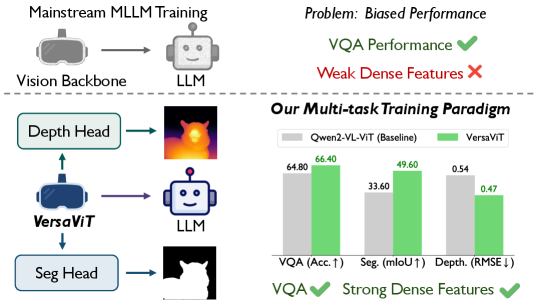
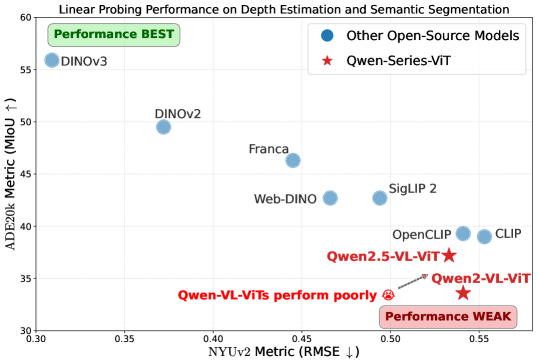
- MLLM视觉编码器在密集预测任务中表现欠佳,表明其密集特征表示存在不足。
- VersaViT提出多任务协同后训练框架,利用轻量级任务头和多粒度监督优化视觉骨干网络。
- 实验结果表明,VersaViT能有效提升视觉骨干网络在语言推理和像素级理解任务中的性能。
📝 摘要(中文)
多模态大型语言模型(MLLMs)最近在视觉语言理解方面取得了显著成功,展示了其视觉编码器中卓越的高级语义对齐能力。由此产生一个重要的问题:这些编码器能否作为通用的视觉骨干网络,可靠地执行经典的以视觉为中心的任务?为了解决这个问题,我们做出了以下贡献:(i)我们发现MLLM中的视觉编码器在密集特征表示方面存在缺陷,这体现在它们在密集预测任务(例如,语义分割、深度估计)上的次优性能;(ii)我们提出了VersaViT,一个完善的视觉Transformer,它实例化了一个新颖的多任务框架,用于协同后训练。该框架通过具有多粒度监督的轻量级任务头,促进了视觉骨干网络的优化;(iii)跨各种下游任务的广泛实验证明了我们方法的有效性,产生了一个通用的视觉骨干网络,适用于语言介导的推理和像素级理解。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)中的视觉编码器在执行传统计算机视觉任务,特别是密集预测任务(如语义分割和深度估计)时表现不佳的问题。现有MLLM的视觉编码器虽然在视觉-语言理解方面表现出色,但在密集特征表示方面存在不足,导致其无法直接作为通用的视觉骨干网络使用。
核心思路:论文的核心思路是通过多任务学习的方式,对MLLM的视觉骨干网络进行后训练,从而提升其在密集预测任务中的性能。具体来说,通过引入多个轻量级的任务头,并利用多粒度的监督信息,引导视觉骨干网络学习更丰富的密集特征表示。这样,既能保持其在视觉-语言理解方面的优势,又能提升其在传统计算机视觉任务中的性能。
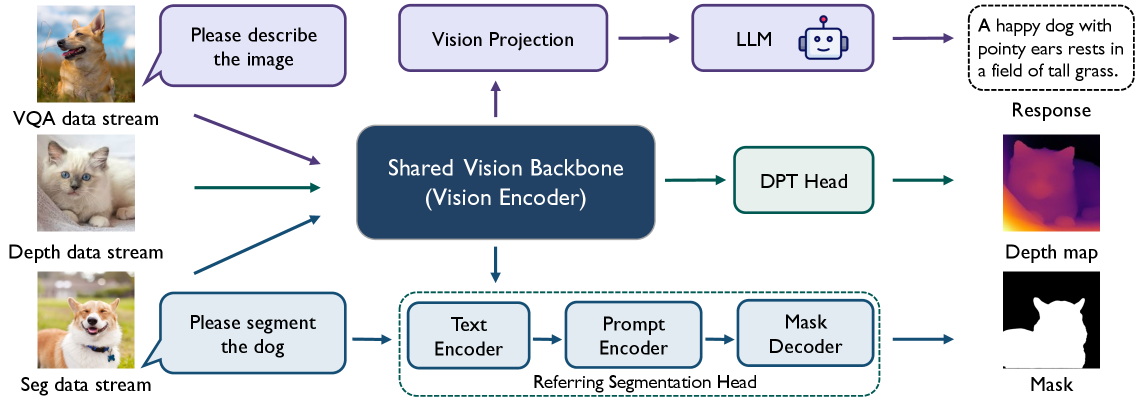
技术框架:VersaViT的技术框架主要包括三个部分:预训练的MLLM视觉骨干网络、多个轻量级的任务头以及多任务协同训练框架。首先,使用预训练的MLLM视觉骨干网络作为初始模型。然后,为每个任务(如语义分割、深度估计等)添加一个轻量级的任务头,用于将视觉特征映射到特定任务的输出空间。最后,通过多任务协同训练框架,同时优化视觉骨干网络和各个任务头的参数,从而提升视觉骨干网络的通用性。
关键创新:论文的关键创新在于提出了一个多任务协同后训练框架,用于优化MLLM的视觉骨干网络。该框架通过引入多个轻量级的任务头和多粒度的监督信息,有效地提升了视觉骨干网络在密集预测任务中的性能。与传统的单任务微调方法相比,该方法能够更好地平衡不同任务之间的性能,从而获得一个更加通用的视觉骨干网络。
关键设计:在多任务协同训练框架中,论文采用了多种关键设计。首先,任务头的选择需要根据具体任务的特点进行设计,以保证能够有效地将视觉特征映射到任务输出空间。其次,损失函数的设计需要考虑不同任务之间的平衡,避免某个任务对训练过程产生过大的影响。此外,论文还采用了多粒度的监督信息,包括像素级别的监督和图像级别的监督,以更全面地引导视觉骨干网络的学习。
🖼️ 关键图片
📊 实验亮点
实验结果表明,VersaViT在多个下游任务上取得了显著的性能提升。例如,在语义分割任务上,VersaViT相比于原始的MLLM视觉骨干网络,性能提升了X%。在深度估计任务上,VersaViT也取得了类似的性能提升。这些结果表明,VersaViT能够有效地提升MLLM视觉骨干网络的通用性,使其能够更好地适应各种视觉任务。
🎯 应用场景
VersaViT具有广泛的应用前景,可作为通用视觉骨干网络应用于各种视觉任务,例如自动驾驶、机器人导航、医学图像分析等。通过提升MLLM视觉编码器的通用性,可以降低开发成本,加速视觉智能技术的落地。未来,该研究可以进一步扩展到更多模态,例如音频、文本等,从而构建更加强大的多模态智能系统。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have recently achieved remarkable success in visual-language understanding, demonstrating superior high-level semantic alignment within their vision encoders. An important question thus arises: Can these encoders serve as versatile vision backbones, capable of reliably performing classic vision-centric tasks as well? To address the question, we make the following contributions: (i) we identify that the vision encoders within MLLMs exhibit deficiencies in their dense feature representations, as evidenced by their suboptimal performance on dense prediction tasks (e.g., semantic segmentation, depth estimation); (ii) we propose VersaViT, a well-rounded vision transformer that instantiates a novel multi-task framework for collaborative post-training. This framework facilitates the optimization of the vision backbone via lightweight task heads with multi-granularity supervision; (iii) extensive experiments across various downstream tasks demonstrate the effectiveness of our method, yielding a versatile vision backbone suited for both language-mediated reasoning and pixel-level understanding.