Code2World: A GUI World Model via Renderable Code Generation
作者: Yuhao Zheng, Li'an Zhong, Yi Wang, Rui Dai, Kaikui Liu, Xiangxiang Chu, Linyuan Lv, Philip Torr, Kevin Qinghong Lin
分类: cs.CV, cs.AI, cs.CL, cs.HC
发布日期: 2026-02-10
备注: github: https://github.com/AMAP-ML/Code2World project page: https://amap-ml.github.io/Code2World/
🔗 代码/项目: GITHUB
💡 一句话要点
提出Code2World,通过可渲染代码生成实现GUI世界模型,提升GUI Agent的交互能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: GUI世界模型 可渲染代码生成 视觉语言模型 强化学习 UI预测 Android导航 人机交互 视觉反馈修正
📋 核心要点
- 现有GUI世界模型在视觉保真度和细粒度结构控制方面存在不足,限制了Agent的预测能力。
- Code2World通过生成可渲染的代码来模拟GUI环境,从而实现高保真和可控的预测。
- 实验表明,Code2World在UI预测和下游导航任务中均取得了显著的性能提升。
📝 摘要(中文)
本文提出Code2World,一个通过可渲染代码生成来模拟GUI环境的视觉语言模型,旨在解决现有基于文本和像素的方法在GUI世界模型中视觉保真度和细粒度结构可控性之间的矛盾。为了克服数据稀缺问题,作者构建了AndroidCode数据集,通过将GUI轨迹翻译成高保真HTML,并利用视觉反馈修正机制优化合成代码,最终得到超过8万个高质量的屏幕-动作对。为了使现有的视觉语言模型适应代码预测,首先进行监督微调(SFT)作为格式布局的冷启动,然后应用渲染感知强化学习,使用渲染结果作为奖励信号,以保证视觉语义的保真度和动作的一致性。实验表明,Code2World-8B在UI预测任务上表现优异,可与GPT-5和Gemini-3-Pro-Image相媲美,并且显著提高了下游导航任务的成功率,例如在AndroidWorld导航中,Gemini-2.5-Flash的成功率提升了9.5%。
🔬 方法详解
问题定义:现有基于文本和像素的GUI世界模型方法难以同时保证高视觉保真度和细粒度结构可控性。文本描述可能不够精确,无法捕捉UI的细节,而像素级别的预测则缺乏结构信息,难以进行精确的动作规划。这限制了GUI Agent的预测能力和交互效率。
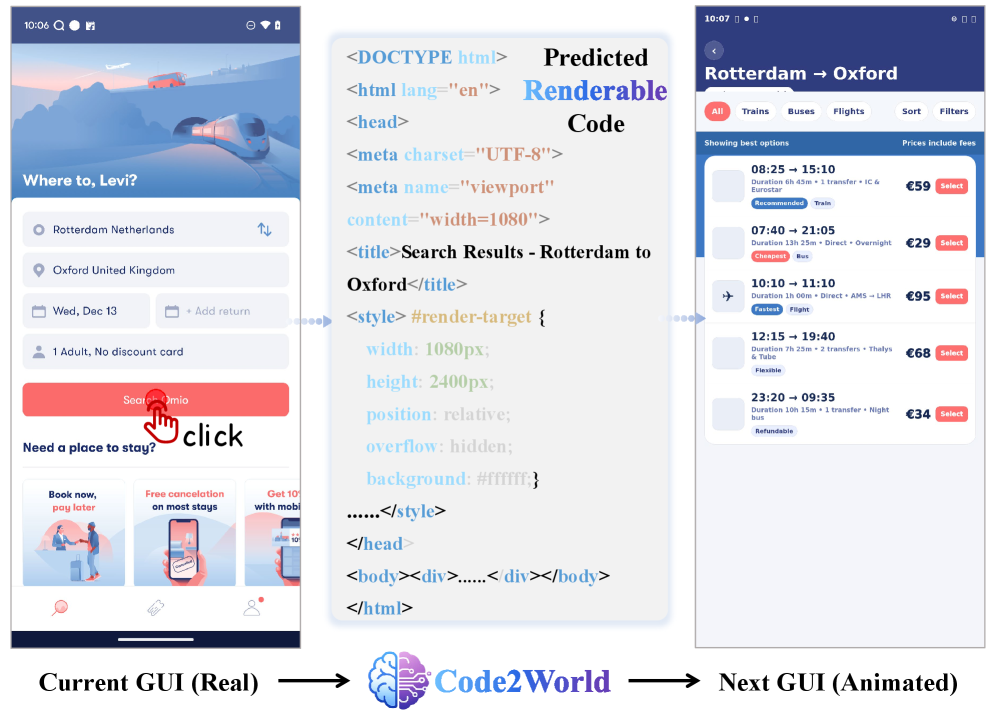
核心思路:Code2World的核心思路是通过生成可渲染的代码(HTML)来模拟GUI环境。代码具有结构化的特点,可以精确地描述UI的各个元素及其属性,从而实现高保真度和细粒度控制。通过将动作转化为对代码的修改,可以预测执行动作后的UI状态。
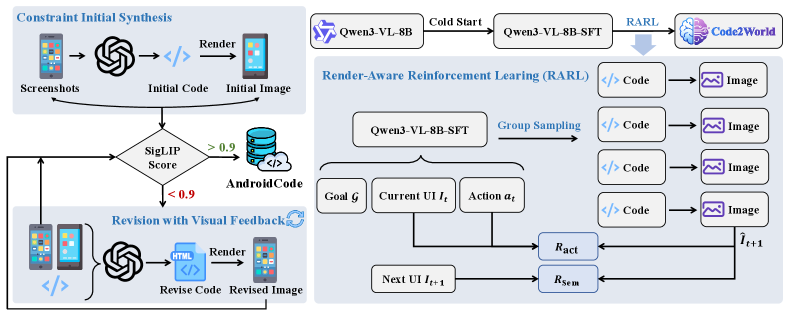
技术框架:Code2World的整体框架包含以下几个主要模块:1) AndroidCode数据集构建:将GUI轨迹翻译成HTML代码,并通过视觉反馈修正机制进行优化。2) 监督微调(SFT):使用AndroidCode数据集对视觉语言模型进行微调,使其具备生成HTML代码的能力。3) 渲染感知强化学习:使用渲染后的UI图像作为奖励信号,对模型进行强化学习,以提高视觉语义保真度和动作一致性。
关键创新:Code2World的关键创新在于使用可渲染的代码作为GUI世界模型的表示形式。与传统的文本或像素表示相比,代码具有更高的精度和可控性,能够更好地模拟GUI环境。此外,渲染感知强化学习的引入,使得模型能够更好地学习视觉语义和动作之间的关系。
关键设计:在AndroidCode数据集构建中,使用了视觉反馈修正机制,通过比较渲染后的UI图像与真实UI图像之间的差异,来修正生成的HTML代码。在渲染感知强化学习中,奖励函数的设计至关重要,需要综合考虑视觉语义的相似度和动作的一致性。具体而言,可以使用预训练的视觉模型提取UI图像的特征,并计算特征之间的相似度。同时,需要对不合理的动作进行惩罚,以保证动作的合理性。
🖼️ 关键图片

📊 实验亮点
Code2World-8B在UI预测任务上取得了领先的性能,可以与GPT-5和Gemini-3-Pro-Image等大型模型相媲美。在AndroidWorld导航任务中,Code2World显著提高了Gemini-2.5-Flash的成功率,提升幅度达到9.5%。这些实验结果表明,Code2World能够有效地模拟GUI环境,并提升Agent的交互能力。
🎯 应用场景
Code2World具有广泛的应用前景,例如可以用于开发更智能的GUI Agent,帮助用户自动完成各种任务。此外,还可以用于UI设计的辅助工具,帮助设计师快速生成和修改UI界面。该研究对于提升人机交互的效率和智能化水平具有重要意义。
📄 摘要(原文)
Autonomous GUI agents interact with environments by perceiving interfaces and executing actions. As a virtual sandbox, the GUI World model empowers agents with human-like foresight by enabling action-conditioned prediction. However, existing text- and pixel-based approaches struggle to simultaneously achieve high visual fidelity and fine-grained structural controllability. To this end, we propose Code2World, a vision-language coder that simulates the next visual state via renderable code generation. Specifically, to address the data scarcity problem, we construct AndroidCode by translating GUI trajectories into high-fidelity HTML and refining synthesized code through a visual-feedback revision mechanism, yielding a corpus of over 80K high-quality screen-action pairs. To adapt existing VLMs into code prediction, we first perform SFT as a cold start for format layout following, then further apply Render-Aware Reinforcement Learning which uses rendered outcome as the reward signal by enforcing visual semantic fidelity and action consistency. Extensive experiments demonstrate that Code2World-8B achieves the top-performing next UI prediction, rivaling the competitive GPT-5 and Gemini-3-Pro-Image. Notably, Code2World significantly enhances downstream navigation success rates in a flexible manner, boosting Gemini-2.5-Flash by +9.5% on AndroidWorld navigation. The code is available at https://github.com/AMAP-ML/Code2World.