Kelix Technique Report
作者: Boyang Ding, Chenglong Chu, Dunju Zang, Han Li, Jiangxia Cao, Kun Gai, Muhao Wei, Ruiming Tang, Shiyao Wang, Siyang Mao, Xinchen Luo, Yahui Liu, Zhixin Ling, Zhuoran Yang, Ziming Li, Chengru Song, Guorui Zhou, Guowang Zhang, Hao Peng, Hao Wang, Jiaxin Deng, Jin Ouyang, Jinghao Zhang, Lejian Ren, Qianqian Wang, Qigen Hu, Tao Wang, Xingmei Wang, Yiping Yang, Zixing Zhang, Ziqi Wang
分类: cs.CV
发布日期: 2026-02-10
备注: Work in progress
💡 一句话要点
Kelix:一种全离散自回归统一模型,缩小了离散和连续视觉表示之间的理解差距。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 自回归模型 离散表示 多模态学习 视觉Transformer
📋 核心要点
- 现有视觉语言模型(VLMs)依赖混合接口,即离散文本token与连续ViT特征配对,导致模型偏向文本理解,无法充分利用非文本数据。
- Kelix提出一种全离散自回归统一模型,旨在弥合离散和连续视觉表示之间的理解差距,实现更有效的多模态建模。
- 该模型通过改进离散视觉token的表示能力,力求在理解任务上达到与使用连续特征的VLMs相当的性能水平。
📝 摘要(中文)
自回归大型语言模型(LLMs)通过将各种任务表示为离散自然语言token序列,并使用下一个token预测进行训练,从而实现良好的扩展性,这在自监督下统一了理解和生成。将这种范式扩展到多模态数据需要跨模态的共享离散表示。然而,大多数视觉语言模型(VLMs)仍然依赖于混合接口:离散文本token与连续视觉Transformer(ViT)特征配对。由于监督主要由文本驱动,这些模型通常偏向于理解,并且不能充分利用非文本数据上的大规模自监督学习。最近的工作探索了离散视觉token化,以实现完全自回归的多模态建模,在统一理解和生成方面显示出有希望的进展。然而,由于代码容量有限,现有的离散视觉token经常丢失信息,导致理解能力明显弱于连续特征VLMs。我们提出了Kelix,一种全离散自回归统一模型,它缩小了离散和连续视觉表示之间的理解差距。
🔬 方法详解
问题定义:现有视觉语言模型(VLMs)通常采用混合表示,即文本使用离散token,图像使用连续的ViT特征。这种混合方式导致模型对文本的依赖性过强,无法充分利用大规模的非文本数据进行自监督学习。此外,现有的离散视觉token化方法由于码本容量的限制,会造成信息损失,导致理解能力下降。
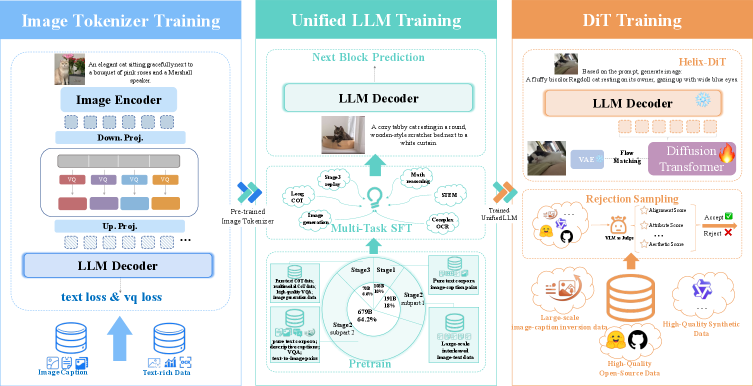
核心思路:Kelix的核心思路是构建一个完全基于离散token的自回归模型,统一处理文本和图像数据。通过改进离散视觉token的表示能力,使得模型能够更好地理解图像内容,从而缩小与使用连续特征的VLMs在理解能力上的差距。这种全离散化的方法有利于利用大规模的无标注数据进行预训练,提升模型的泛化能力。
技术框架:Kelix采用自回归Transformer架构,将文本和图像都表示为离散的token序列。图像首先通过一个视觉tokenizer转换为离散的视觉token,然后与文本token一起输入到Transformer模型中进行训练。模型的目标是预测序列中的下一个token,从而学习文本和图像之间的关联关系。
关键创新:Kelix的关键创新在于它是一个完全离散的自回归模型,避免了混合表示带来的问题。通过改进视觉tokenizer的设计,使得离散视觉token能够更好地保留图像信息,从而提升模型的理解能力。
关键设计:具体的技术细节包括:视觉tokenizer的结构和训练方式,Transformer模型的参数设置,以及损失函数的设计。论文可能会探讨不同的视觉tokenizer架构,例如VQ-VAE或Gumbel-Softmax等,并研究它们对模型性能的影响。此外,论文还可能关注如何有效地训练自回归Transformer模型,例如使用特定的学习率策略或正则化方法。
🖼️ 关键图片

📊 实验亮点
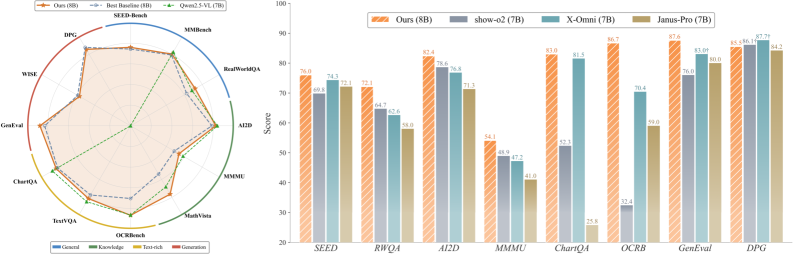
由于摘要中没有提供具体的实验数据,因此无法总结实验亮点。但是,可以推断,该论文的实验部分会重点比较Kelix与现有VLMs在各种理解任务上的性能,并展示Kelix在缩小离散和连续视觉表示差距方面的优势。具体的性能指标可能包括准确率、召回率、F1值等。
🎯 应用场景
Kelix模型具有广泛的应用前景,包括图像描述生成、视觉问答、跨模态检索等。通过统一文本和图像的表示,Kelix可以更好地理解多模态数据,从而在各种下游任务中取得更好的性能。此外,Kelix的全离散化设计也为模型部署和推理带来了便利。
📄 摘要(原文)
Autoregressive large language models (LLMs) scale well by expressing diverse tasks as sequences of discrete natural-language tokens and training with next-token prediction, which unifies comprehension and generation under self-supervision. Extending this paradigm to multimodal data requires a shared, discrete representation across modalities. However, most vision-language models (VLMs) still rely on a hybrid interface: discrete text tokens paired with continuous Vision Transformer (ViT) features. Because supervision is largely text-driven, these models are often biased toward understanding and cannot fully leverage large-scale self-supervised learning on non-text data. Recent work has explored discrete visual tokenization to enable fully autoregressive multimodal modeling, showing promising progress toward unified understanding and generation. Yet existing discrete vision tokens frequently lose information due to limited code capacity, resulting in noticeably weaker understanding than continuous-feature VLMs. We present Kelix, a fully discrete autoregressive unified model that closes the understanding gap between discrete and continuous visual representations.