ARK: A Dual-Axis Multimodal Retrieval Benchmark along Reasoning and Knowledge
作者: Yijie Lin, Guofeng Ding, Haochen Zhou, Haobin Li, Mouxing Yang, Xi Peng
分类: cs.CV
发布日期: 2026-02-10
💡 一句话要点
提出ARK基准,用于评估多模态检索在推理和知识方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 基准数据集 知识推理 视觉推理 难负样本 双轴评估 专业知识 异构数据
📋 核心要点
- 现有基准缺乏对专业知识和复杂推理的诊断,限制了多模态检索的深入研究。
- ARK基准通过知识领域和推理技能两个维度,全面评估多模态检索的能力。
- 实验表明,现有模型在知识密集型和推理密集型检索上存在差距,细粒度视觉推理是瓶颈。
📝 摘要(中文)
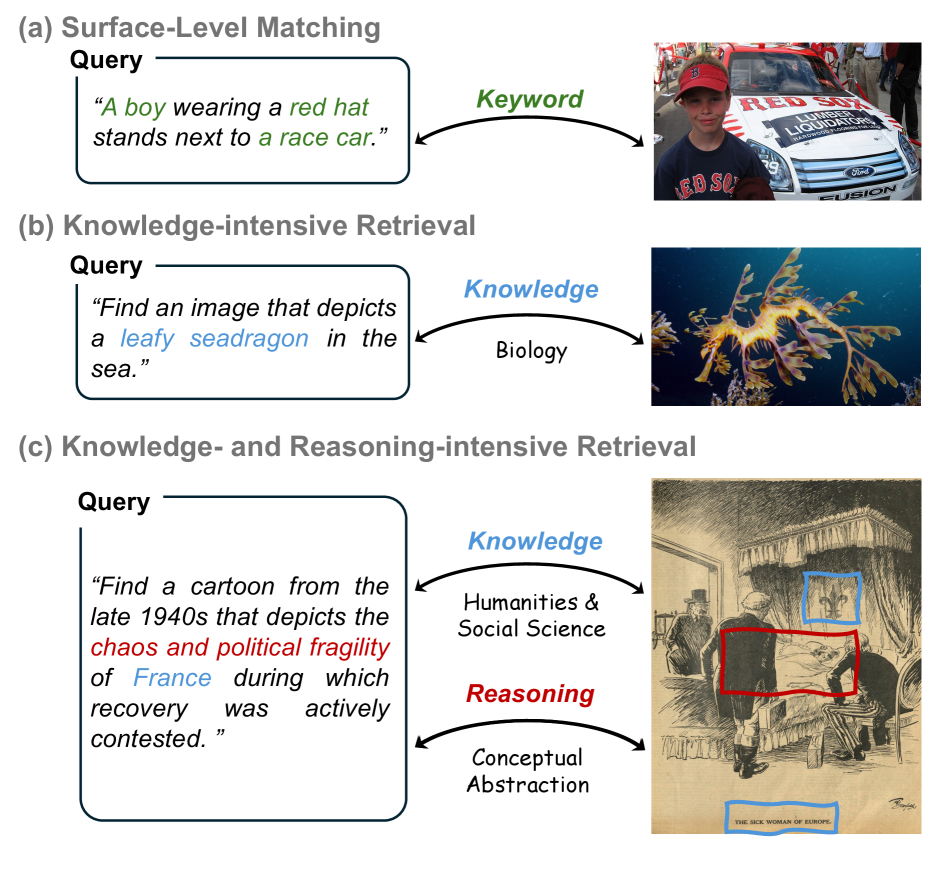
现有的多模态检索基准主要侧重于日常图像的语义匹配,对专业知识和复杂推理的诊断能力有限。为了弥补这一差距,我们引入了ARK,一个旨在从两个互补角度分析多模态检索的基准:(i)知识领域(五个领域,17个子类型),用于表征检索所依赖的内容和专业知识;(ii)推理技能(六个类别),用于表征识别正确候选对象所需的多模态证据推理类型。具体而言,ARK评估了单模态和多模态查询与候选对象的检索,涵盖16种异构视觉数据类型。为了避免评估期间的捷径匹配,大多数查询都配有需要多步推理的针对性难负样本。我们评估了ARK上的23个代表性的基于文本和多模态的检索器,并观察到知识密集型和推理密集型检索之间存在明显的差距,其中细粒度的视觉和空间推理成为持续的瓶颈。我们进一步表明,诸如重新排序和重写之类的简单增强可以产生持续的改进,但仍有很大的提升空间。
🔬 方法详解
问题定义:现有的多模态检索基准数据集主要关注日常场景的语义匹配,缺乏对专业知识和复杂推理能力的评估。这使得研究人员难以深入分析现有模型在处理需要专业知识和推理能力的检索任务时的不足之处。因此,需要一个新的基准数据集,能够更全面地评估多模态检索模型在知识和推理方面的能力,并为未来的研究提供更具挑战性的测试平台。
核心思路:ARK基准的核心思路是从知识领域和推理技能两个互补的角度来评估多模态检索。通过定义不同的知识领域(如医学、工程等)和推理技能(如空间推理、因果推理等),ARK能够更细粒度地分析模型在不同类型知识和推理任务上的表现。此外,ARK还引入了难负样本,迫使模型进行多步推理,避免简单的语义匹配。
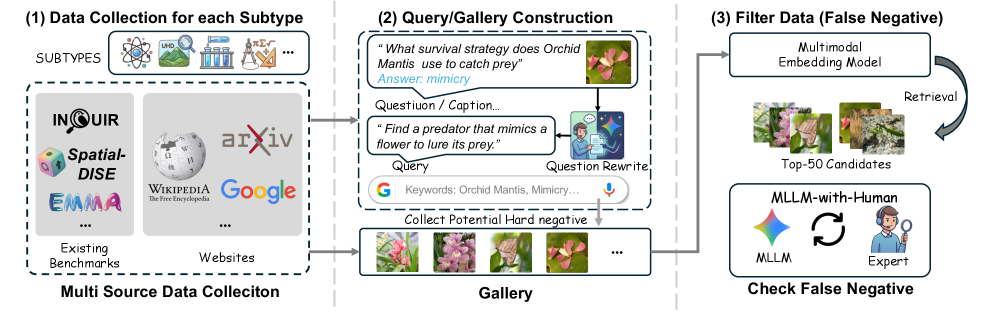
技术框架:ARK基准数据集的构建流程主要包括以下几个阶段:1) 定义知识领域和推理技能的类别;2) 收集和标注多模态数据,包括图像、文本等;3) 设计查询和候选对象,并配以难负样本;4) 评估现有模型在ARK上的表现,并分析结果。该基准涵盖了16种异构视觉数据类型,包括图像、图表、公式等。
关键创新:ARK基准的关键创新在于其双轴评估体系,即知识领域和推理技能。这种双轴评估方式能够更全面地评估多模态检索模型的能力,并揭示模型在不同类型知识和推理任务上的优缺点。此外,ARK还引入了难负样本,迫使模型进行多步推理,避免简单的语义匹配,从而更真实地反映了模型在实际应用中的表现。
关键设计:ARK基准在设计时考虑了以下关键因素:1) 知识领域的选择:选择了五个具有代表性的知识领域,涵盖了不同的专业领域;2) 推理技能的定义:定义了六种常见的推理技能,包括空间推理、因果推理等;3) 难负样本的生成:采用了多种策略生成难负样本,包括基于规则的方法和基于模型的方法;4) 评估指标的选择:选择了多种评估指标,包括Recall@K、NDCG等,以全面评估模型的性能。
🖼️ 关键图片

📊 实验亮点
在ARK基准上,23个代表性的文本和多模态检索器表现出明显的差距,尤其是在知识密集型和推理密集型检索方面。细粒度的视觉和空间推理成为持续的瓶颈。通过简单的重新排序和重写等增强方法,性能可以得到一致的提升,但仍有很大的改进空间。例如,某些模型在特定知识领域上的Recall@10仅为个位数。
🎯 应用场景
ARK基准的潜在应用领域包括智能问答系统、医学图像检索、工程图纸检索等。通过使用ARK进行评估,可以帮助研究人员开发更强大的多模态检索模型,从而提高这些应用领域的性能和效率。此外,ARK还可以用于教育领域,帮助学生学习和理解专业知识。
📄 摘要(原文)
Existing multimodal retrieval benchmarks largely emphasize semantic matching on daily-life images and offer limited diagnostics of professional knowledge and complex reasoning. To address this gap, we introduce ARK, a benchmark designed to analyze multimodal retrieval from two complementary perspectives: (i) knowledge domains (five domains with 17 subtypes), which characterize the content and expertise retrieval relies on, and (ii) reasoning skills (six categories), which characterize the type of inference over multimodal evidence required to identify the correct candidate. Specifically, ARK evaluates retrieval with both unimodal and multimodal queries and candidates, covering 16 heterogeneous visual data types. To avoid shortcut matching during evaluation, most queries are paired with targeted hard negatives that require multi-step reasoning. We evaluate 23 representative text-based and multimodal retrievers on ARK and observe a pronounced gap between knowledge-intensive and reasoning-intensive retrieval, with fine-grained visual and spatial reasoning emerging as persistent bottlenecks. We further show that simple enhancements such as re-ranking and rewriting yield consistent improvements, but substantial headroom remains.