Towards Training-free Multimodal Hate Localisation with Large Language Models
作者: Yueming Sun, Long Yang, Jianbo Jiao, Zeyu Fu
分类: cs.CV, cs.MM
发布日期: 2026-02-10
💡 一句话要点
提出LELA:一种基于大语言模型的无训练多模态仇恨内容定位框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 仇恨内容检测 多模态学习 大语言模型 无监督学习 视频理解
📋 核心要点
- 现有视频仇恨检测方法依赖大量人工标注或缺乏时间精度,限制了其应用。
- LELA利用大语言模型和多模态信息,通过无训练方式实现仇恨内容的检测和定位。
- 实验表明,LELA在两个基准数据集上显著优于现有无训练方法,具有可扩展性和可解释性。
📝 摘要(中文)
在线视频中仇恨内容的扩散对个人福祉和社会和谐构成严重威胁。然而,现有的视频仇恨检测解决方案要么严重依赖大规模的人工标注,要么缺乏细粒度的时间精度。本文提出了LELA,这是第一个基于大语言模型(LLM)的无训练仇恨视频定位框架。与依赖监督pipeline的现有模型不同,LELA利用LLM和特定模态的字幕生成技术,以无训练的方式检测和在时间上定位仇恨视频中的内容。该方法将视频分解为图像、语音、OCR、音乐和视频上下文五种模态,并使用多阶段提示方案计算每个帧的细粒度仇恨得分。此外,引入了一种组合匹配机制来增强跨模态推理。在HateMM和MultiHateClip两个具有挑战性的基准数据集上的实验表明,LELA的性能大大优于所有现有的无训练基线。我们还提供了广泛的消融研究和定性可视化,将LELA确立为可扩展且可解释的仇恨视频定位的强大基础。
🔬 方法详解
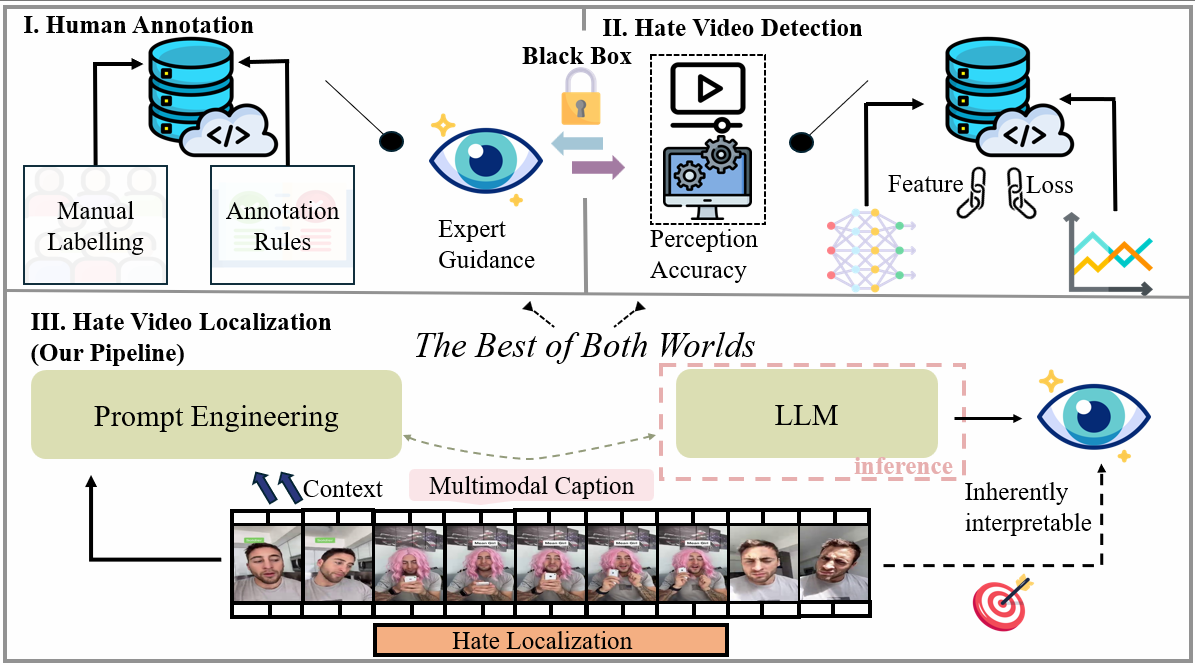
问题定义:现有视频仇恨内容检测方法主要依赖于大规模人工标注的数据集进行训练,成本高昂且泛化能力有限。此外,这些方法通常缺乏足够的时间精度,难以精确定位仇恨内容在视频中的具体时间段。
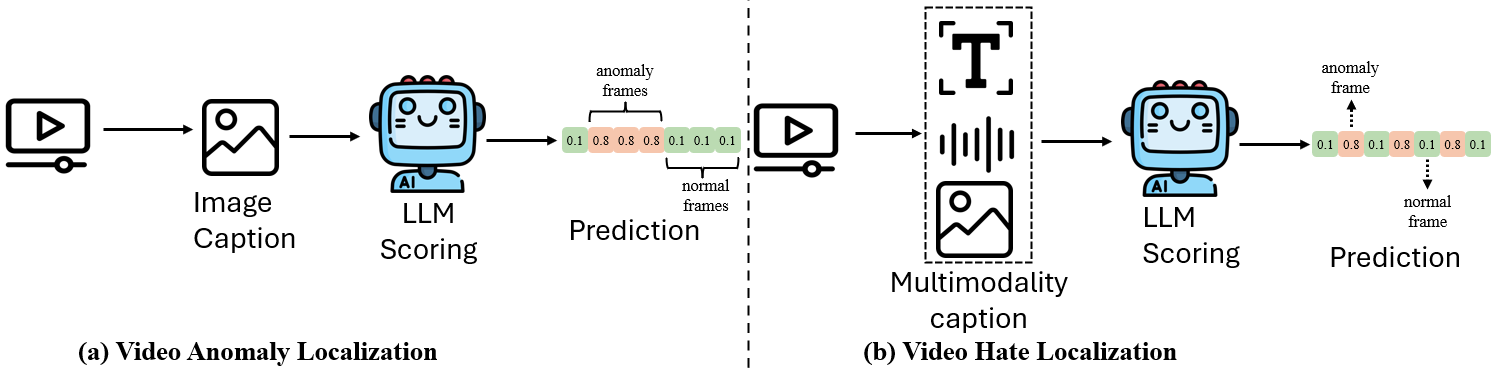
核心思路:LELA的核心思路是利用大语言模型(LLM)强大的语义理解和推理能力,结合视频的多模态信息,在不需要任何训练数据的情况下,实现仇恨内容的检测和时间定位。通过将视频分解为多个模态,并利用LLM对每个模态进行分析,可以更全面地理解视频内容,从而更准确地识别仇恨信息。
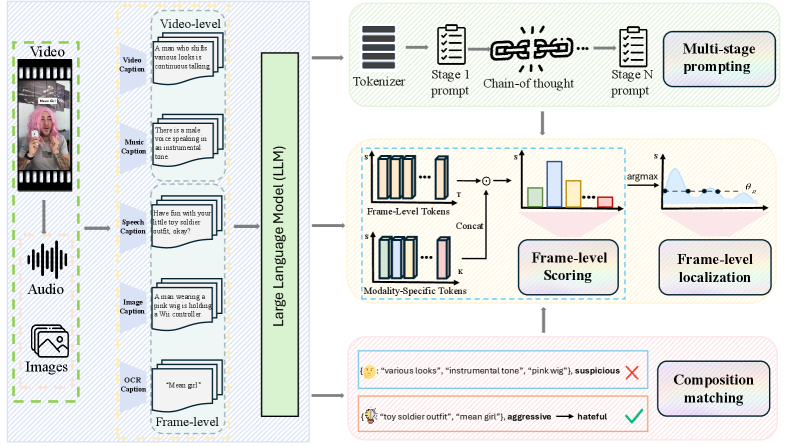
技术框架:LELA框架主要包含以下几个阶段:1) 视频分解:将视频分解为图像、语音、OCR、音乐和视频上下文五种模态。2) 模态字幕生成:使用特定模态的字幕生成技术,将每种模态转换为文本描述。3) 多阶段提示:设计多阶段提示方案,利用LLM对每个帧的文本描述进行分析,计算细粒度的仇恨得分。4) 组合匹配:引入组合匹配机制,增强跨模态推理能力,提高检测准确率。
关键创新:LELA最关键的创新在于其无训练的特性。与传统的监督学习方法不同,LELA不需要任何人工标注的数据进行训练,而是直接利用LLM的先验知识和推理能力来检测仇恨内容。这种方法大大降低了标注成本,并提高了模型的泛化能力。此外,多阶段提示和组合匹配机制也有效地提升了检测的准确率和鲁棒性。
关键设计:LELA的关键设计包括:1) 针对不同模态设计了不同的字幕生成方法,以确保文本描述的准确性和完整性。2) 多阶段提示方案的设计,通过逐步引导LLM进行分析,提高检测的准确率。3) 组合匹配机制的设计,通过考虑不同模态之间的关系,增强跨模态推理能力。具体的参数设置和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
LELA在HateMM和MultiHateClip两个基准数据集上取得了显著的性能提升,大幅超越了现有的无训练基线方法。具体性能数据和提升幅度在论文中未明确给出,属于未知信息。实验结果表明,LELA在无训练的条件下,能够有效地检测和定位视频中的仇恨内容,具有很强的实用价值。
🎯 应用场景
LELA具有广泛的应用前景,可用于在线视频平台的内容审核,自动识别和过滤仇恨、歧视等有害信息,维护健康的网络环境。此外,该技术还可应用于社交媒体监控、舆情分析等领域,帮助及时发现和应对潜在的社会风险。未来,LELA有望成为构建安全、和谐网络空间的重要技术支撑。
📄 摘要(原文)
The proliferation of hateful content in online videos poses severe threats to individual well-being and societal harmony. However, existing solutions for video hate detection either rely heavily on large-scale human annotations or lack fine-grained temporal precision. In this work, we propose LELA, the first training-free Large Language Model (LLM) based framework for hate video localization. Distinct from state-of-the-art models that depend on supervised pipelines, LELA leverages LLMs and modality-specific captioning to detect and temporally localize hateful content in a training-free manner. Our method decomposes a video into five modalities, including image, speech, OCR, music, and video context, and uses a multi-stage prompting scheme to compute fine-grained hateful scores for each frame. We further introduce a composition matching mechanism to enhance cross-modal reasoning. Experiments on two challenging benchmarks, HateMM and MultiHateClip, demonstrate that LELA outperforms all existing training-free baselines by a large margin. We also provide extensive ablations and qualitative visualizations, establishing LELA as a strong foundation for scalable and interpretable hate video localization.