Tele-Omni: a Unified Multimodal Framework for Video Generation and Editing
作者: Jialun Liu, Yukuo Ma, Xiao Cao, Tian Li, Gonghu Shang, Haibin Huang, Chi Zhang, Xuelong Li, Cong Liu, Junqi Liu, Jiakui Hu, Robby T. Tan, Shiwen Zhang, Liying Yang, Xiaoyan Yang, Qizhen Weng, Xiangzhen Chang, Yuanzhi Liang, Yifan Xu, Zhiyong Huang, Zuoxin Li, Xuelong Li
分类: cs.CV
发布日期: 2026-02-10
💡 一句话要点
Tele-Omni:统一多模态视频生成与编辑框架,支持文本、图像和视频指令。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 视频编辑 多模态学习 扩散模型 大型语言模型 统一框架 任务感知 指令解析
📋 核心要点
- 现有视频生成方法缺乏统一性,难以处理多模态输入和多样化任务,且编辑流程复杂,限制了可扩展性。
- Tele-Omni框架利用多模态大语言模型解析指令,并使用扩散模型生成视频,实现多模态控制和任务统一。
- Tele-Omni在文本到视频、图像到视频等多种任务上表现出竞争力,验证了其有效性和泛化能力。
📝 摘要(中文)
扩散模型在视频生成方面取得了显著进展,但在处理多模态输入、上下文参考以及多样化的视频生成和编辑场景时,现有方法通常是任务特定的,并且主要依赖于文本指令,缺乏统一性。此外,许多视频编辑方法依赖于为特定操作量身定制的复杂流程,限制了可扩展性和可组合性。本文提出了Tele-Omni,一个统一的多模态视频生成和编辑框架,它可以在单个模型中遵循包括文本、图像和参考视频在内的多模态指令。Tele-Omni利用预训练的多模态大型语言模型来解析异构指令并推断结构化的生成或编辑意图,而基于扩散的生成器则根据这些结构化信号执行高质量的视频合成。为了实现跨异构视频任务的联合训练,我们引入了一个任务感知的的数据处理流程,该流程将多模态输入统一为结构化的指令格式,同时保留特定于任务的约束。Tele-Omni支持广泛的视频中心任务,包括文本到视频生成、图像到视频生成、首尾帧视频生成、上下文视频生成和上下文视频编辑。通过将指令解析与视频合成分离,并将其与任务感知的数据设计相结合,Tele-Omni实现了灵活的多模态控制,同时保持了强大的时间连贯性和视觉一致性。实验结果表明,Tele-Omni在多个任务上取得了有竞争力的性能。
🔬 方法详解
问题定义:现有视频生成和编辑方法通常是任务特定的,难以处理多种模态的输入(如文本、图像、视频),并且缺乏一个统一的框架来支持不同的视频生成和编辑任务。此外,许多视频编辑方法依赖于复杂的、针对特定操作设计的流程,这限制了它们的可扩展性和可组合性。因此,需要一个能够处理多模态输入、支持多种视频任务,并且具有良好可扩展性的统一框架。
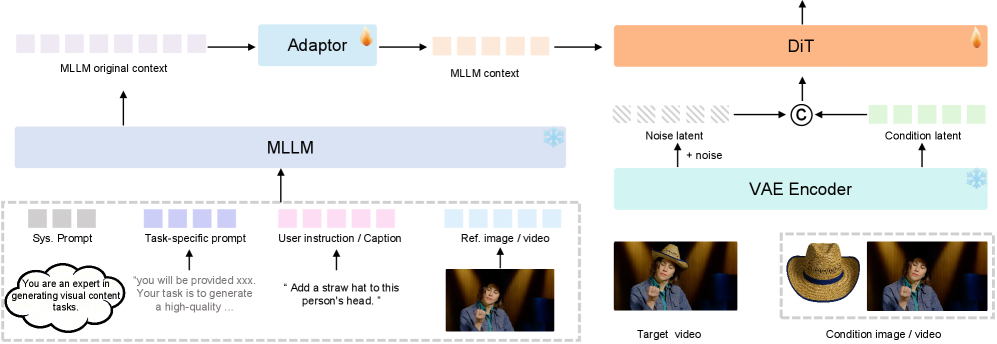
核心思路:Tele-Omni的核心思路是将指令解析和视频生成解耦。利用预训练的多模态大型语言模型(LLM)来解析各种模态的指令(文本、图像、视频),并将其转化为结构化的意图表示。然后,使用基于扩散模型的生成器,根据这些结构化的意图表示来合成高质量的视频。这种解耦的设计使得模型可以灵活地处理不同的输入模态和任务,并且可以利用LLM的强大语义理解能力。
技术框架:Tele-Omni框架主要包含两个模块:指令解析模块和视频生成模块。指令解析模块使用预训练的多模态LLM,将输入的文本、图像和视频指令解析成结构化的意图表示。视频生成模块使用基于扩散模型的生成器,根据指令解析模块输出的意图表示来生成视频。为了支持多种视频任务的联合训练,该框架还引入了一个任务感知的的数据处理流程,将多模态输入统一为结构化的指令格式,同时保留特定于任务的约束。
关键创新:Tele-Omni的关键创新在于提出了一个统一的多模态视频生成和编辑框架,该框架能够处理多种模态的输入,并且支持多种视频任务。通过将指令解析和视频生成解耦,并利用预训练的多模态LLM,该框架实现了灵活的多模态控制和强大的语义理解能力。此外,任务感知的的数据处理流程使得模型可以支持多种视频任务的联合训练。
关键设计:Tele-Omni的关键设计包括:1) 使用预训练的多模态LLM进行指令解析,这使得模型可以利用LLM的强大语义理解能力;2) 使用基于扩散模型的生成器进行视频生成,这使得模型可以生成高质量的视频;3) 引入任务感知的的数据处理流程,这使得模型可以支持多种视频任务的联合训练。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
Tele-Omni在多个视频生成和编辑任务上取得了有竞争力的性能,包括文本到视频生成、图像到视频生成、首尾帧视频生成、上下文视频生成和上下文视频编辑。具体性能数据和对比基线在论文中进行了详细描述(未知),但总体而言,Tele-Omni展示了其在多模态视频生成和编辑方面的有效性和泛化能力。
🎯 应用场景
Tele-Omni具有广泛的应用前景,例如:视频内容创作、电影特效制作、游戏开发、虚拟现实和增强现实等领域。它可以帮助用户快速生成和编辑高质量的视频内容,降低视频制作的门槛,并为创意表达提供更多的可能性。未来,Tele-Omni有望成为视频内容创作的重要工具。
📄 摘要(原文)
Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.