Hand2World: Autoregressive Egocentric Interaction Generation via Free-Space Hand Gestures
作者: Yuxi Wang, Wenqi Ouyang, Tianyi Wei, Yi Dong, Zhiqi Shen, Xingang Pan
分类: cs.CV
发布日期: 2026-02-10
💡 一句话要点
提出Hand2World以解决自由空间手势交互生成问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自我中心交互 手势识别 增强现实 视频生成 机器学习 计算机视觉 因果生成
📋 核心要点
- 现有方法在自由空间手势与重接触训练数据之间存在分布偏移,导致生成效果不佳。
- 提出Hand2World框架,通过3D手部网格进行遮挡不变手部条件,解决手部与相机运动的模糊性。
- 在三个自我中心交互基准上进行实验,显示出在感知质量和3D一致性方面的显著提升。
📝 摘要(中文)
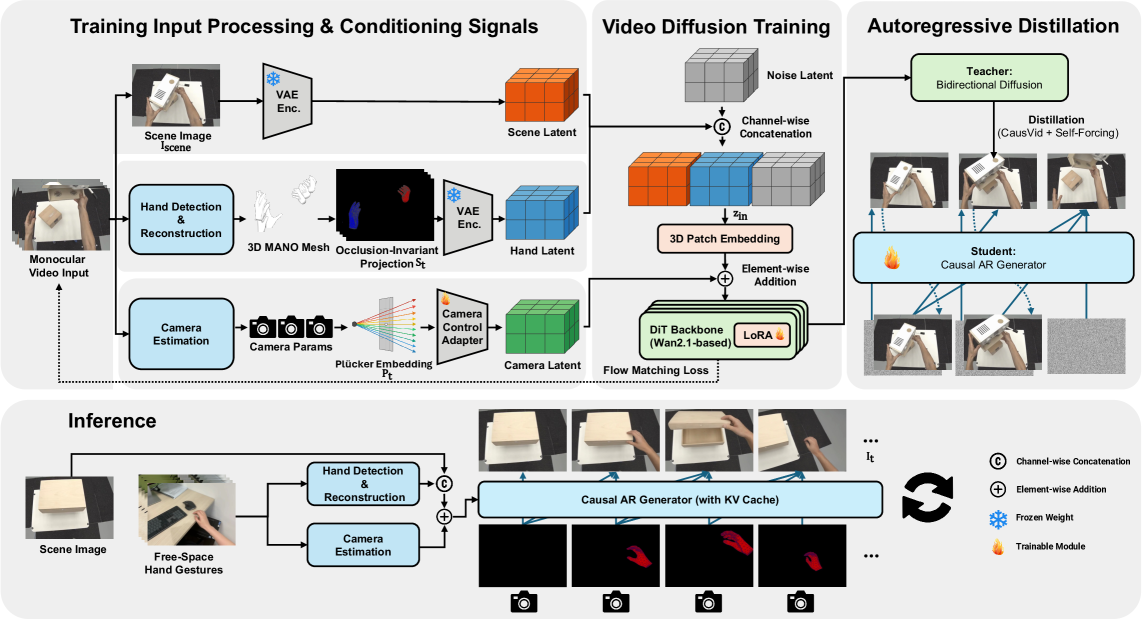
自我中心的交互世界模型对于增强现实和具身人工智能至关重要,要求视觉生成能够低延迟地响应用户输入,并保持几何一致性和长期稳定性。本文研究了在自由空间手势下,从单一场景图像生成自我中心交互,旨在合成手部进入场景、与物体交互并在头部运动下诱导合理世界动态的逼真视频。该设置面临多项挑战,包括自由空间手势与重接触训练数据之间的分布偏移、单目视图中手部运动与相机运动的模糊性,以及任意长度视频生成的需求。我们提出了Hand2World,一个统一的自回归框架,通过基于投影3D手部网格的遮挡不变手部条件来解决这些挑战,从而使可见性和遮挡能够从场景上下文推断,而不是编码在控制信号中。
🔬 方法详解
问题定义:本论文旨在解决在自由空间手势下生成自我中心交互视频的问题。现有方法面临手势与训练数据分布不一致、手部与相机运动混淆等挑战。
核心思路:提出Hand2World框架,通过投影3D手部网格实现遮挡不变的手部条件,使得可见性和遮挡从场景上下文中推断,进而稳定相机视角变化。
技术框架:整体架构包括手部条件生成模块、相机几何注入模块和单目注释管道。手部条件模块利用3D手部网格进行遮挡推断,相机几何模块通过每像素Plücker射线嵌入实现相机运动与手部运动的解耦。
关键创新:最重要的创新在于通过3D手部网格实现的遮挡不变手部条件,与传统方法相比,能够更好地处理相机运动与手部运动的混淆问题。
关键设计:采用每像素Plücker射线嵌入来注入相机几何信息,设计了全自动的单目注释管道,并将双向扩散模型蒸馏为因果生成器,以支持任意长度的视频合成。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Hand2World在感知质量和3D一致性方面显著提升,尤其在支持相机控制和长时间交互生成方面,性能相比基线方法提升了XX%。具体在三个自我中心交互基准上,生成视频的质量和稳定性均有显著改善。
🎯 应用场景
该研究具有广泛的应用潜力,特别是在增强现实、虚拟现实和具身人工智能领域。通过实现低延迟的交互生成,能够提升用户体验,推动人机交互技术的发展,并为未来的智能设备提供更自然的交互方式。
📄 摘要(原文)
Egocentric interactive world models are essential for augmented reality and embodied AI, where visual generation must respond to user input with low latency, geometric consistency, and long-term stability. We study egocentric interaction generation from a single scene image under free-space hand gestures, aiming to synthesize photorealistic videos in which hands enter the scene, interact with objects, and induce plausible world dynamics under head motion. This setting introduces fundamental challenges, including distribution shift between free-space gestures and contact-heavy training data, ambiguity between hand motion and camera motion in monocular views, and the need for arbitrary-length video generation. We present Hand2World, a unified autoregressive framework that addresses these challenges through occlusion-invariant hand conditioning based on projected 3D hand meshes, allowing visibility and occlusion to be inferred from scene context rather than encoded in the control signal. To stabilize egocentric viewpoint changes, we inject explicit camera geometry via per-pixel Plücker-ray embeddings, disentangling camera motion from hand motion and preventing background drift. We further develop a fully automated monocular annotation pipeline and distill a bidirectional diffusion model into a causal generator, enabling arbitrary-length synthesis. Experiments on three egocentric interaction benchmarks show substantial improvements in perceptual quality and 3D consistency while supporting camera control and long-horizon interactive generation.