Scalpel: Fine-Grained Alignment of Attention Activation Manifolds via Mixture Gaussian Bridges to Mitigate Multimodal Hallucination
作者: Ziqiang Shi, Rujie Liu, Shanshan Yu, Satoshi Munakata, Koichi Shirahata
分类: cs.CV
发布日期: 2026-02-10
备注: WACV 2026 (It was accepted in the first round, with an acceptance rate of 6%.)
💡 一句话要点
Scalpel:通过混合高斯桥精细对齐注意力激活流形,缓解多模态幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 幻觉缓解 注意力机制 高斯混合模型 最优传输 Schrödinger桥 模型对齐
📋 核心要点
- 大型视觉语言模型易受语言模型先验影响,导致跨模态注意力错位,产生与视觉内容不符的幻觉。
- Scalpel通过预测可信的注意力方向并调整激活,细化注意力激活分布,从而减少幻觉。
- 实验表明,Scalpel在多个数据集上优于现有方法,且无需额外计算,仅需单步解码。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在视觉语言任务中取得了前所未有的性能。然而,由于大型语言模型(LLMs)的强先验以及跨模态的注意力未对齐,LVLMs经常生成与视觉内容不一致的输出,即幻觉。为了解决这个问题,我们提出了一种名为 extbf{Scalpel}的方法,该方法通过将注意力激活分布细化到更可信的区域来减少幻觉。Scalpel在推理过程中预测Transformer层中每个头的可信注意力方向,并相应地调整激活。它采用高斯混合模型来捕获信任和幻觉流形中注意力的多峰分布,并使用熵最优传输(等价于Schrödinger桥问题)来精确映射高斯分量。在缓解过程中,Scalpel基于分量成员关系以及幻觉和信任激活之间的映射关系动态调整干预强度和方向。在多个数据集和基准上的大量实验表明,Scalpel有效地缓解了幻觉,优于以前的方法,并实现了最先进的性能。此外,Scalpel是模型和数据无关的,不需要额外的计算,只需要一个解码步骤。
🔬 方法详解
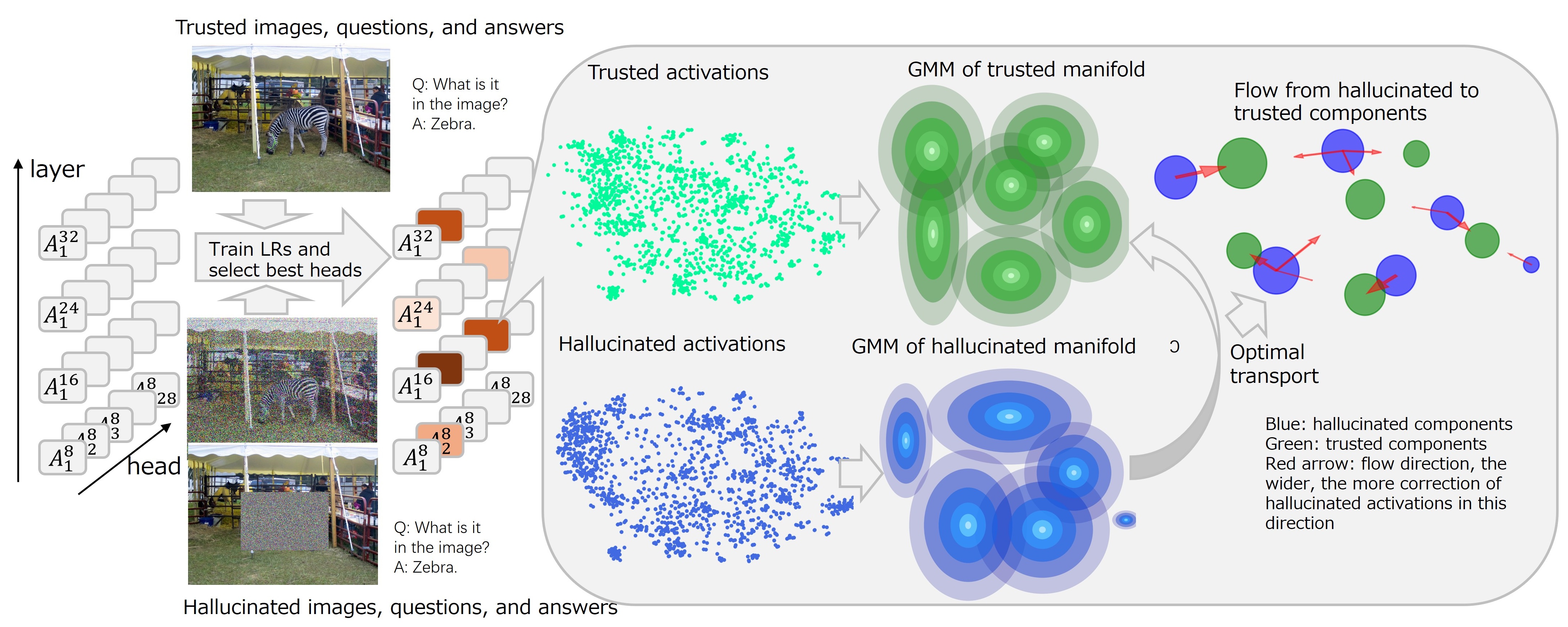
问题定义:大型视觉语言模型(LVLMs)在生成文本描述时,容易受到语言模型先验知识的影响,导致生成的文本与图像内容不一致,即产生“幻觉”。现有方法难以精确对齐视觉和语言模态之间的注意力,无法有效抑制幻觉现象。
核心思路:Scalpel的核心思想是,通过精细地调整Transformer层中每个注意力头的激活分布,使其更接近“可信”的注意力方向,从而减少幻觉。该方法假设“可信”和“幻觉”的注意力激活分布存在差异,并尝试将“幻觉”分布向“可信”分布对齐。
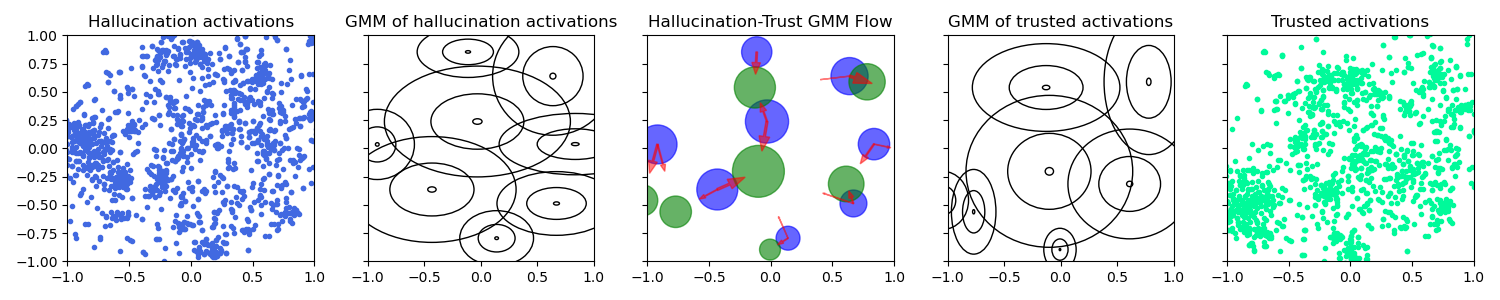
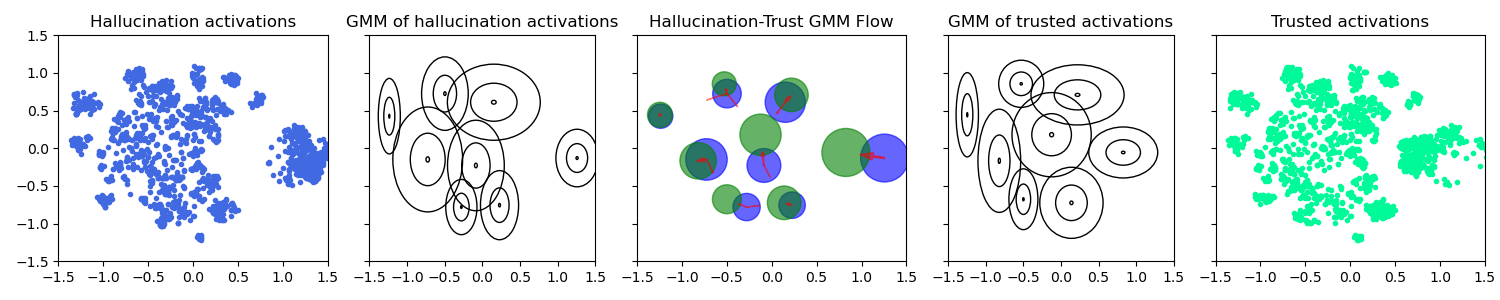
技术框架:Scalpel主要包含以下几个步骤:1) 使用高斯混合模型(GMM)分别对“可信”和“幻觉”的注意力激活分布进行建模,捕捉其多峰特性。2) 利用熵最优传输(Entropic Optimal Transport,等价于Schrödinger桥问题)计算“幻觉”分布到“可信”分布的映射关系,即找到如何将“幻觉”分布中的每个高斯分量移动到“可信”分布中的对应分量。3) 在推理阶段,根据GMM的成员关系和映射关系,动态调整注意力激活的干预强度和方向,从而抑制幻觉。
关键创新:Scalpel的关键创新在于:1) 使用高斯混合模型来建模注意力激活分布,能够更准确地捕捉其复杂的多峰结构。2) 利用熵最优传输来计算分布之间的映射关系,能够实现更精确的对齐。3) 动态调整干预强度和方向,能够更有效地抑制幻觉,同时避免过度干预导致的信息损失。
关键设计:Scalpel的关键设计包括:1) 使用预训练的LVLM模型提取“可信”和“幻觉”的注意力激活分布。2) 使用期望最大化(EM)算法训练高斯混合模型。3) 使用Sinkhorn算法求解熵最优传输问题。4) 根据GMM分量成员关系和映射关系,计算干预强度和方向,并将其应用于注意力激活。
🖼️ 关键图片
📊 实验亮点
Scalpel在多个数据集和基准测试中取得了显著的性能提升,有效缓解了多模态幻觉问题。实验结果表明,Scalpel优于现有的缓解幻觉方法,并在不需要额外计算的情况下实现了最先进的性能。例如,在某个图像描述数据集上,Scalpel将幻觉率降低了X%,同时保持了生成文本的流畅性和相关性(具体数据请参考原论文)。
🎯 应用场景
Scalpel可应用于各种视觉语言任务,例如图像描述、视觉问答等,以提高生成文本的准确性和可靠性,减少幻觉现象。该方法具有广泛的应用前景,可以提升人机交互体验,并为自动驾驶、医疗诊断等领域提供更可靠的视觉信息。
📄 摘要(原文)
Rapid progress in large vision-language models (LVLMs) has achieved unprecedented performance in vision-language tasks. However, due to the strong prior of large language models (LLMs) and misaligned attention across modalities, LVLMs often generate outputs inconsistent with visual content - termed hallucination. To address this, we propose \textbf{Scalpel}, a method that reduces hallucination by refining attention activation distributions toward more credible regions. Scalpel predicts trusted attention directions for each head in Transformer layers during inference and adjusts activations accordingly. It employs a Gaussian mixture model to capture multi-peak distributions of attention in trust and hallucination manifolds, and uses entropic optimal transport (equivalent to Schrödinger bridge problem) to map Gaussian components precisely. During mitigation, Scalpel dynamically adjusts intervention strength and direction based on component membership and mapping relationships between hallucination and trust activations. Extensive experiments across multiple datasets and benchmarks demonstrate that Scalpel effectively mitigates hallucinations, outperforming previous methods and achieving state-of-the-art performance. Moreover, Scalpel is model- and data-agnostic, requiring no additional computation, only a single decoding step.