AUHead: Realistic Emotional Talking Head Generation via Action Units Control
作者: Jiayi Lyu, Leigang Qu, Wenjing Zhang, Hanyu Jiang, Kai Liu, Zhenglin Zhou, Xiaobo Xia, Jian Xue, Tat-Seng Chua
分类: cs.CV
发布日期: 2026-02-10
备注: https://openreview.net/forum?id=dmzlAUkulz&referrer=%5BAuthor%20Console%5D(%2Fgroup%3Fid%3DICLR.cc%2F2026%2FConference%2FAuthors%23your-submissions)
🔗 代码/项目: GITHUB
💡 一句话要点
AUHead:通过动作单元控制实现逼真情感的说话头生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 说话头生成 动作单元控制 情感表达 音频-语言模型 扩散模型 可控生成 虚拟化身
📋 核心要点
- 现有说话头生成方法难以精细控制情感,导致生成的情感表达不够 nuanced,这是核心问题。
- AUHead通过两阶段方法,首先利用音频-语言模型解耦音频中的动作单元,然后使用AU驱动的扩散模型生成视频。
- 实验结果表明,AUHead在情感真实感、唇部同步和视觉连贯性方面优于现有技术,实现了显著提升。
📝 摘要(中文)
逼真的说话头视频生成对于虚拟化身、电影制作和交互式系统至关重要。现有方法由于缺乏细粒度的情感控制,难以处理细微的情感表达。为了解决这个问题,我们提出了一种新颖的两阶段方法(AUHead),将细粒度的情感控制(即动作单元AUs)从音频中解耦,并实现可控生成。在第一阶段,我们通过时空AU标记化和“情感-AU”的思维链机制,探索大型音频-语言模型(ALMs)的AU生成能力,旨在从原始语音中分离出AUs,有效捕捉细微的情感线索。在第二阶段,我们提出了一个AU驱动的可控扩散模型,该模型合成以AU序列为条件的逼真说话头视频。具体来说,我们首先将AU序列映射到结构化的2D面部表示,以增强空间保真度,然后在交叉注意力模块中对AU-视觉交互进行建模。为了实现灵活的AU质量权衡控制,我们在推理过程中引入了AU解耦引导策略,进一步细化了生成视频的情感表达和身份一致性。在基准数据集上的结果表明,我们的方法在情感真实感、准确的唇部同步和视觉连贯性方面取得了有竞争力的性能,显著优于现有技术。我们的实现可在https://github.com/laura990501/AUHead_ICLR 获取。
🔬 方法详解
问题定义:现有说话头生成方法在生成具有细微情感表达的视频时面临挑战。主要痛点在于缺乏对情感的细粒度控制,难以准确捕捉和表达人物的微妙情感变化。这限制了生成视频的真实感和表现力。
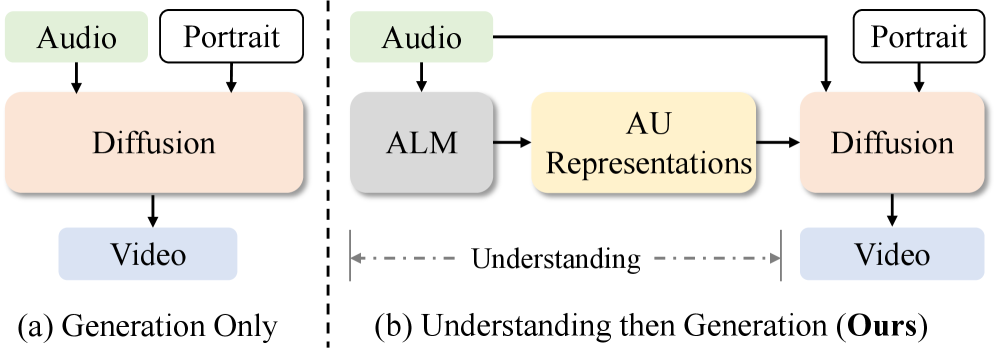
核心思路:AUHead的核心思路是将情感表达分解为可控的动作单元(AUs),并利用音频-语言模型从语音中提取这些AUs。然后,使用这些AUs作为条件,驱动一个扩散模型生成逼真的说话头视频。这种解耦的方式使得情感控制更加精细和灵活。
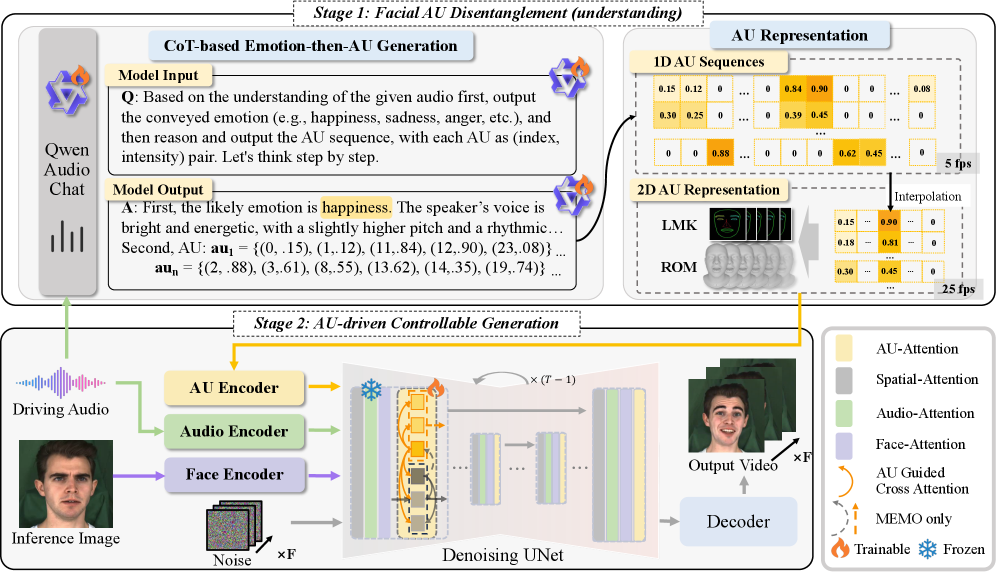
技术框架:AUHead包含两个主要阶段:1) AU生成阶段:利用大型音频-语言模型(ALMs)生成AU序列。该阶段采用时空AU标记化和“情感-AU”的思维链机制,从原始语音中提取AUs。2) 视频生成阶段:使用AU驱动的可控扩散模型合成说话头视频。该阶段首先将AU序列映射到2D面部表示,然后通过交叉注意力模块建模AU-视觉交互。
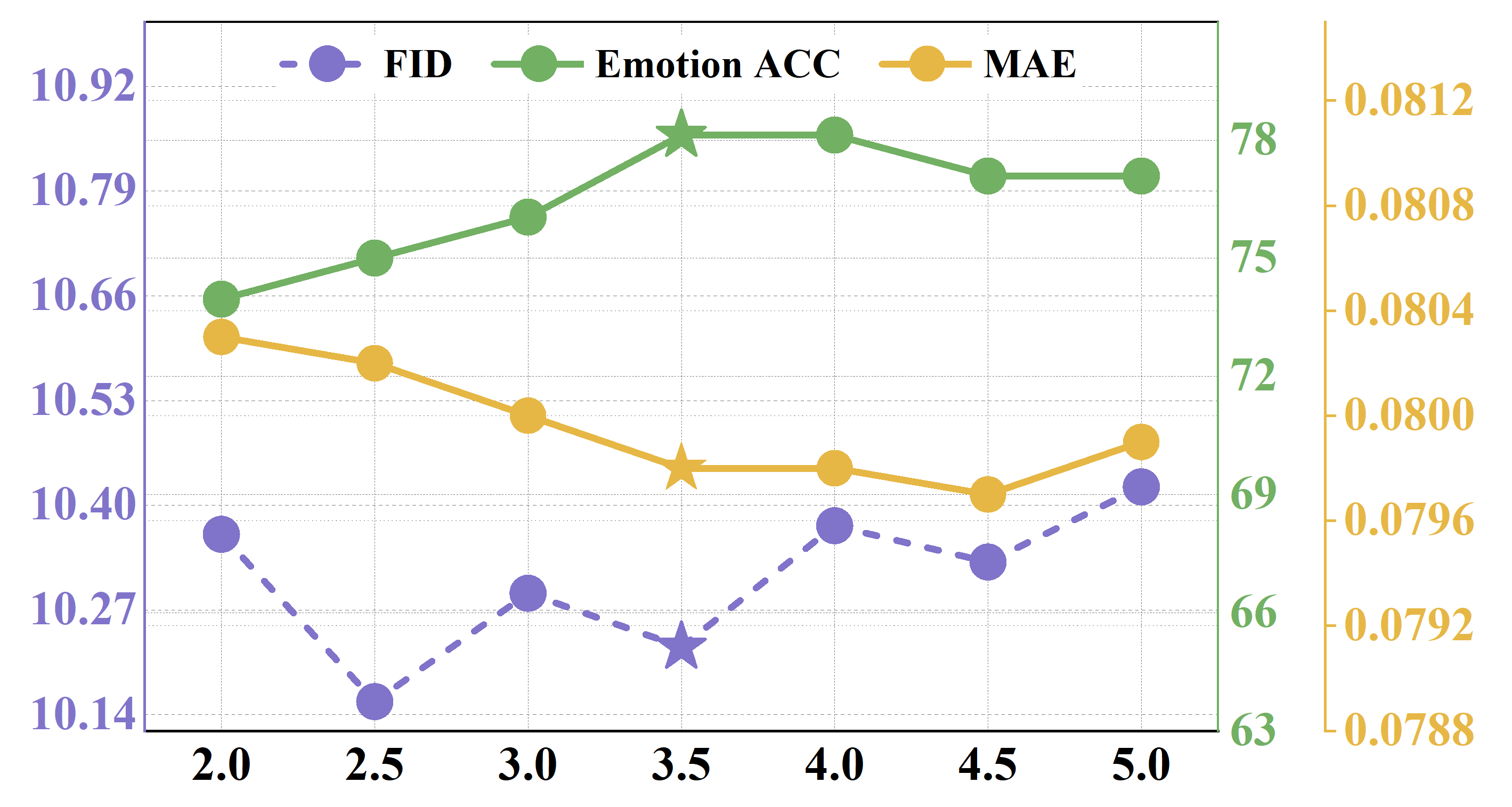
关键创新:AUHead的关键创新在于:1) AU解耦:通过音频-语言模型将情感表达解耦为可控的动作单元,实现了细粒度的情感控制。2) AU驱动的扩散模型:使用AU序列作为条件,驱动扩散模型生成逼真的说话头视频,提高了生成视频的真实感和表现力。3) AU解耦引导策略:在推理过程中引入AU解耦引导策略,进一步细化生成视频的情感表达和身份一致性。
关键设计:在AU生成阶段,采用了“情感-AU”的思维链机制,引导模型先理解情感,再生成对应的AU序列。在视频生成阶段,使用了交叉注意力模块来建模AU和视觉特征之间的交互。此外,还设计了AU解耦引导策略,通过调整AU的权重来控制生成视频的情感强度和身份一致性。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
AUHead在基准数据集上取得了显著的性能提升,在情感真实感、唇部同步和视觉连贯性方面均优于现有技术。具体而言,该方法能够生成具有细微情感表达的说话头视频,并且能够准确地同步唇部动作和语音。实验结果表明,AUHead在客观指标和主观评价上都取得了有竞争力的结果。
🎯 应用场景
AUHead技术在虚拟化身、电影制作、游戏开发和交互式系统中具有广泛的应用前景。它可以用于创建更逼真、更具表现力的虚拟角色,提升用户体验。此外,该技术还可以应用于情感识别和情感计算领域,例如,通过分析生成的AU序列来推断人物的情感状态,为情感智能应用提供支持。
📄 摘要(原文)
Realistic talking-head video generation is critical for virtual avatars, film production, and interactive systems. Current methods struggle with nuanced emotional expressions due to the lack of fine-grained emotion control. To address this issue, we introduce a novel two-stage method (AUHead) to disentangle fine-grained emotion control, i.e. , Action Units (AUs), from audio and achieve controllable generation. In the first stage, we explore the AU generation abilities of large audio-language models (ALMs), by spatial-temporal AU tokenization and an "emotion-then-AU" chain-of-thought mechanism. It aims to disentangle AUs from raw speech, effectively capturing subtle emotional cues. In the second stage, we propose an AU-driven controllable diffusion model that synthesizes realistic talking-head videos conditioned on AU sequences. Specifically, we first map the AU sequences into the structured 2D facial representation to enhance spatial fidelity, and then model the AU-vision interaction within cross-attention modules. To achieve flexible AU-quality trade-off control, we introduce an AU disentanglement guidance strategy during inference, further refining the emotional expressiveness and identity consistency of the generated videos. Results on benchmark datasets demonstrate that our approach achieves competitive performance in emotional realism, accurate lip synchronization, and visual coherence, significantly surpassing existing techniques. Our implementation is available at https://github.com/laura990501/AUHead_ICLR