Beyond Next-Token Alignment: Distilling Multimodal Large Language Models via Token Interactions
作者: Lin Chen, Xiaoke Zhao, Kun Ding, Weiwei Feng, Changtao Miao, Zili Wang, Wenxuan Guo, Ying Wang, Kaiyuan Zheng, Bo Zhang, Zhe Li, Shiming Xiang
分类: cs.CV
发布日期: 2026-02-10
🔗 代码/项目: GITHUB
💡 一句话要点
提出Align-TI,通过token交互蒸馏多模态大语言模型,显著提升模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 知识蒸馏 Token交互 视觉-指令对齐 生成概率对齐 模型压缩 参数高效
📋 核心要点
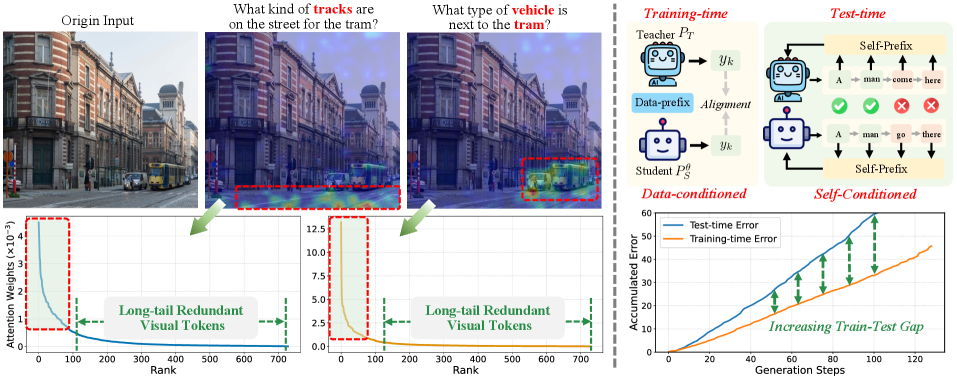
- 现有MLLM知识蒸馏方法侧重于静态的next-token对齐,忽略了token间的动态交互,限制了蒸馏效果。
- Align-TI通过对齐视觉-指令token交互和响应内部token交互,使学生模型模仿教师模型的视觉信息提取和动态生成逻辑。
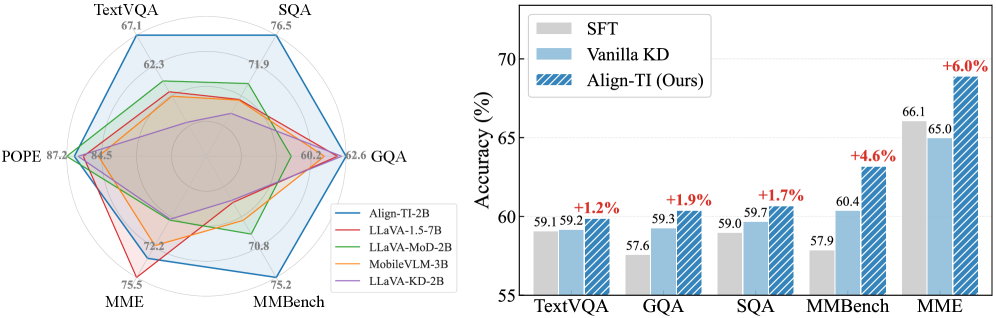
- 实验表明,Align-TI显著优于传统KD方法,蒸馏后的2B模型甚至超越了更大的7B模型,实现了性能提升。
📝 摘要(中文)
多模态大语言模型(MLLMs)展现了卓越的跨模态能力,但其庞大的规模带来了巨大的部署挑战。知识蒸馏(KD)是压缩这些模型的一个有前景的解决方案,但现有的方法主要依赖于静态的next-token对齐,忽略了动态的token交互,而token交互嵌入了多模态理解和生成的基本能力。为此,我们从Token交互的角度出发,提出了一种新的KD框架Align-TI。我们的方法基于这样的洞察:MLLMs依赖于两种主要的交互:视觉-指令token交互,用于提取相关的视觉信息;以及响应内部token交互,用于连贯的生成。因此,Align-TI引入了两个组件:IVA,通过对齐显著的视觉区域,使学生模型能够模仿教师模型的指令相关视觉信息提取能力;TPA,通过对齐连续的token-to-token转移概率,捕捉教师模型的动态生成逻辑。大量的实验证明了Align-TI的优越性。值得注意的是,我们的方法比Vanilla KD实现了2.6%的相对改进,并且我们蒸馏的Align-TI-2B甚至优于LLaVA-1.5-7B(一个更大的MLLM)7.0%,为训练参数高效的MLLM建立了一个新的最先进的蒸馏框架。代码可在https://github.com/lchen1019/Align-TI获得。
🔬 方法详解
问题定义:现有MLLM的知识蒸馏方法主要依赖于静态的next-token对齐,这种方法忽略了模型内部token之间的动态交互,而这些交互对于多模态理解和连贯生成至关重要。因此,如何有效地将教师模型中蕴含的token交互知识迁移到学生模型,是本文要解决的关键问题。现有方法的痛点在于无法充分利用教师模型在token交互层面的知识,导致蒸馏后的学生模型性能受限。
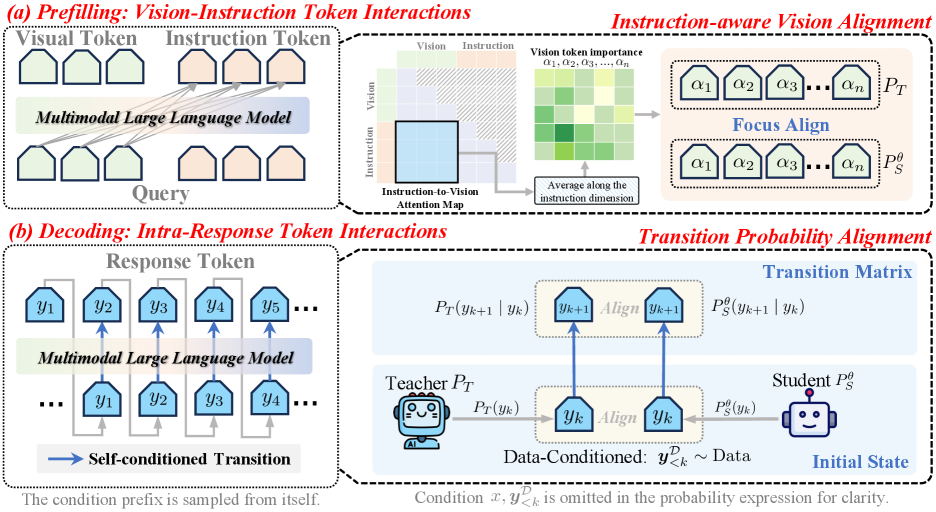
核心思路:本文的核心思路是通过对齐教师模型和学生模型之间的token交互,从而实现更有效的知识迁移。具体来说,论文认为MLLM依赖于两种主要的token交互:视觉-指令token交互(用于提取相关视觉信息)和响应内部token交互(用于连贯生成)。因此,论文设计了相应的对齐策略,使学生模型能够模仿教师模型在这两种交互上的行为。
技术框架:Align-TI框架包含两个主要组件:IVA(Instruction-relevant Visual Alignment)和TPA(Token-to-token Probability Alignment)。IVA旨在使学生模型能够模仿教师模型的指令相关视觉信息提取能力,通过对齐显著的视觉区域来实现。TPA旨在捕捉教师模型的动态生成逻辑,通过对齐连续的token-to-token转移概率来实现。整体流程是,首先利用IVA对齐视觉-指令token交互,然后利用TPA对齐响应内部token交互,从而完成知识蒸馏。
关键创新:本文最重要的技术创新点在于从token交互的角度进行知识蒸馏,并提出了IVA和TPA两种对齐策略。与现有方法仅关注next-token对齐不同,本文更加关注模型内部的动态交互,从而能够更全面地迁移教师模型的知识。这种方法能够更好地保留教师模型的多模态理解和生成能力。
关键设计:IVA的关键设计在于如何确定显著的视觉区域,论文可能采用了注意力机制或其他方法来识别这些区域,并设计了相应的损失函数来对齐教师模型和学生模型在这些区域上的表示。TPA的关键设计在于如何计算token-to-token转移概率,并设计了相应的损失函数来对齐教师模型和学生模型之间的转移概率分布。具体的损失函数形式和参数设置需要在论文中进一步查找。
🖼️ 关键图片
📊 实验亮点
Align-TI在实验中表现出色,相较于Vanilla KD,实现了2.6%的相对性能提升。更令人瞩目的是,经过Align-TI蒸馏后的2B模型,其性能甚至超越了更大的LLaVA-1.5-7B模型,提升幅度达到7.0%。这表明Align-TI是一种非常有效的多模态大语言模型蒸馏方法。
🎯 应用场景
该研究成果可应用于各种需要部署参数高效的多模态大语言模型的场景,例如移动设备、边缘计算等资源受限的环境。通过知识蒸馏,可以在保证模型性能的同时,显著降低模型大小和计算复杂度,从而实现更广泛的应用。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) demonstrate impressive cross-modal capabilities, yet their substantial size poses significant deployment challenges. Knowledge distillation (KD) is a promising solution for compressing these models, but existing methods primarily rely on static next-token alignment, neglecting the dynamic token interactions, which embed essential capabilities for multimodal understanding and generation. To this end, we introduce Align-TI, a novel KD framework designed from the perspective of Token Interactions. Our approach is motivated by the insight that MLLMs rely on two primary interactions: vision-instruction token interactions to extract relevant visual information, and intra-response token interactions for coherent generation. Accordingly, Align-TI introduces two components: IVA enables the student model to imitate the teacher's instruction-relevant visual information extract capability by aligning on salient visual regions. TPA captures the teacher's dynamic generative logic by aligning the sequential token-to-token transition probabilities. Extensive experiments demonstrate Align-TI's superiority. Notably, our approach achieves $2.6\%$ relative improvement over Vanilla KD, and our distilled Align-TI-2B even outperforms LLaVA-1.5-7B (a much larger MLLM) by $7.0\%$, establishing a new state-of-the-art distillation framework for training parameter-efficient MLLMs. Code is available at https://github.com/lchen1019/Align-TI.