WorldCompass: Reinforcement Learning for Long-Horizon World Models
作者: Zehan Wang, Tengfei Wang, Haiyu Zhang, Xuhui Zuo, Junta Wu, Haoyuan Wang, Wenqiang Sun, Zhenwei Wang, Chenjie Cao, Hengshuang Zhao, Chunchao Guo, Zhou Zhao
分类: cs.CV
发布日期: 2026-02-09
备注: Project page: \url{https://3d-models.hunyuan.tencent.com/world/}
💡 一句话要点
WorldCompass:强化学习后训练长时域交互视频世界模型,提升探索能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 强化学习 长时域预测 交互视频 视频生成
📋 核心要点
- 现有世界模型在长时域交互视频中探索能力不足,难以准确一致地模拟真实世界。
- WorldCompass 通过强化学习后训练,利用片段级 rollout 策略、互补奖励函数和高效 RL 算法来引导世界模型探索。
- 实验表明,WorldCompass 显著提高了世界模型在交互准确性和视觉保真度方面的性能。
📝 摘要(中文)
本文提出了WorldCompass,一种新颖的强化学习(RL)后训练框架,用于长时域、基于交互视频的世界模型。该框架使世界模型能够基于交互信号更准确、更一致地探索世界。为了有效地“引导”世界模型的探索,我们针对自回归视频生成范式引入了三个核心创新:1) 片段级 rollout 策略:我们在单个目标片段生成并评估多个样本,显著提高了 rollout 效率并提供了细粒度的奖励信号。2) 互补奖励函数:我们设计了交互跟随准确性和视觉质量的奖励函数,提供了直接监督并有效抑制了奖励利用行为。3) 高效的 RL 算法:我们采用负感知微调策略,结合各种效率优化,以高效且有效地增强模型能力。在最先进的开源世界模型 WorldPlay 上的评估表明,WorldCompass 显著提高了各种场景中的交互准确性和视觉保真度。
🔬 方法详解
问题定义:现有基于视频的世界模型在长时域交互场景下,难以准确预测未来状态,尤其是在需要与环境进行交互的情况下。痛点在于模型难以有效利用交互信号,导致探索效率低,预测结果不准确,容易出现奖励利用等问题。
核心思路:WorldCompass 的核心思路是通过强化学习对预训练的世界模型进行后训练,利用奖励信号引导模型学习更有效的交互策略,从而提升其在长时域交互场景下的探索能力和预测准确性。通过精细化的奖励设计和高效的训练方法,克服了传统强化学习在世界模型训练中的挑战。
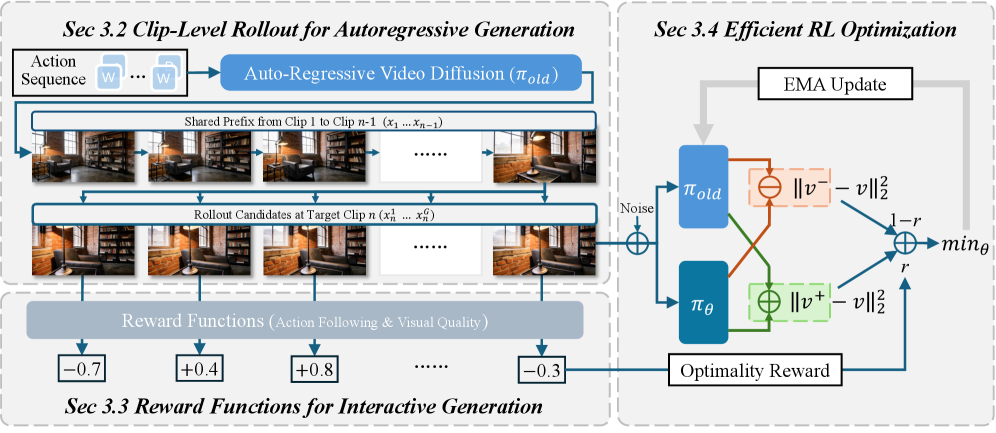
技术框架:WorldCompass 的整体框架包括三个主要模块:1) 片段级 Rollout 策略:在每个时间步,模型生成多个候选片段,并根据奖励函数进行评估。2) 互补奖励函数:设计了交互跟随准确性和视觉质量两个方面的奖励函数,前者鼓励模型准确预测交互结果,后者保证生成视频的视觉质量。3) 高效 RL 算法:采用负感知微调策略,并结合多种优化技术,加速训练过程,提高模型性能。
关键创新:WorldCompass 的关键创新在于其针对自回归视频生成范式的强化学习后训练方法。与传统的端到端训练方法不同,WorldCompass 利用预训练的世界模型作为基础,通过强化学习微调其交互策略,从而更有效地利用交互信号。片段级 rollout 策略和互补奖励函数的设计,进一步提高了训练效率和模型性能。
关键设计:片段级 rollout 策略中,生成片段的数量是一个关键参数,需要在效率和准确性之间进行权衡。互补奖励函数的设计需要仔细考虑各个奖励项的权重,以避免模型过度优化某个指标而忽略其他指标。负感知微调策略通过引入负样本,提高模型的鲁棒性和泛化能力。具体实现细节(如网络结构、优化器选择等)未知。
🖼️ 关键图片

📊 实验亮点
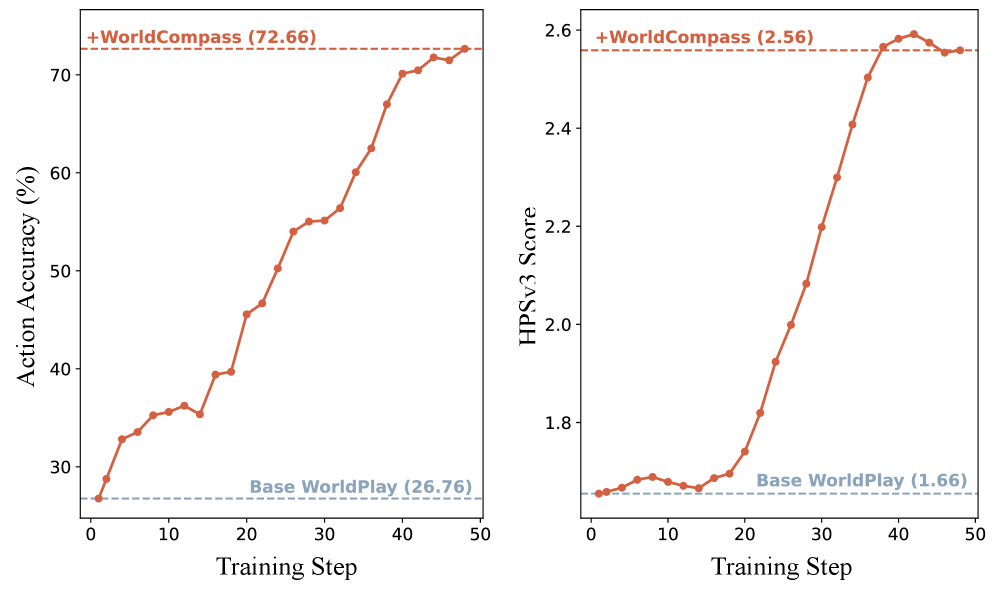
WorldCompass 在 WorldPlay 世界模型上进行了评估,实验结果表明,该方法显著提高了交互准确性和视觉保真度。具体性能数据未知,但论文强调了在各种场景下的一致性提升,表明 WorldCompass 具有良好的泛化能力。与未经过强化学习后训练的模型相比,WorldCompass 在交互任务上的表现有显著提升。
🎯 应用场景
WorldCompass 有潜力应用于机器人控制、游戏 AI、虚拟现实等领域。通过提升世界模型的交互能力,可以使智能体在复杂环境中更好地进行规划和决策,从而实现更智能、更自主的行为。例如,可以用于训练机器人完成复杂的装配任务,或者用于开发更逼真的游戏 AI。
📄 摘要(原文)
This work presents WorldCompass, a novel Reinforcement Learning (RL) post-training framework for the long-horizon, interactive video-based world models, enabling them to explore the world more accurately and consistently based on interaction signals. To effectively "steer" the world model's exploration, we introduce three core innovations tailored to the autoregressive video generation paradigm: 1) Clip-level rollout Strategy: We generate and evaluate multiple samples at a single target clip, which significantly boosts rollout efficiency and provides fine-grained reward signals. 2) Complementary Reward Functions: We design reward functions for both interaction-following accuracy and visual quality, which provide direct supervision and effectively suppress reward-hacking behaviors. 3) Efficient RL Algorithm: We employ the negative-aware fine-tuning strategy coupled with various efficiency optimizations to efficiently and effectively enhance model capacity. Evaluations on the SoTA open-source world model, WorldPlay, demonstrate that WorldCompass significantly improves interaction accuracy and visual fidelity across various scenarios.