WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models
作者: Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Xin Zhang, Yinzhou Tang, Chen Gao, Wei Wu, Xihui Liu, Dhruv Shah, Zhaoxiang Zhang, Zhibo Chen, Jun Zhu, Yonghong Tian, Tat-Seng Chua, Wenwu Zhu, Yong Li
分类: cs.CV, cs.RO
发布日期: 2026-02-09
💡 一句话要点
WorldArena:用于评估具身世界模型感知和功能效用的一体化基准
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身世界模型 基准测试 感知质量 功能效用 具身智能 视频生成 任务规划
📋 核心要点
- 现有具身世界模型评估侧重感知质量,忽略了其在下游任务中的功能效用,导致评估不全面。
- 提出 WorldArena 基准,从视频感知质量和具身任务功能性两个维度系统评估世界模型。
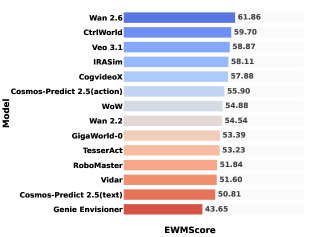
- 实验表明感知质量与功能效用存在差距,并提出了 EWMScore 指标来综合评估模型性能。
📝 摘要(中文)
具身世界模型通过动作条件预测来推理环境动态,已成为具身智能的基石,但其评估仍然分散。目前对具身世界模型的评估主要集中在感知保真度(例如,视频生成质量),而忽略了这些模型在下游决策任务中的功能效用。本文提出了 WorldArena,这是一个统一的基准,旨在系统地评估具身世界模型的感知和功能维度。WorldArena 通过三个维度评估模型:视频感知质量(通过六个子维度的 16 个指标衡量);具身任务功能性(评估世界模型作为数据引擎、策略评估器和动作规划器,并结合主观人工评估)。此外,我们提出了 EWMScore,这是一个将多维性能整合到单个可解释指标中的整体指标。通过对 14 个代表性模型进行的大量实验,我们揭示了显着的感知-功能差距,表明高视觉质量并不一定转化为强大的具身任务能力。WorldArena 基准及其公共排行榜已在 https://worldarena.ai 上发布,为跟踪具身 AI 中真正功能性世界模型的进展提供了一个框架。
🔬 方法详解
问题定义:现有具身世界模型的评估体系存在不足,主要体现在过度关注感知质量(如视频生成质量),而忽略了模型在实际具身任务中的功能效用。这种片面的评估方式无法全面反映世界模型的真实能力,阻碍了具身智能的进一步发展。现有方法缺乏一个统一的、综合性的评估基准,难以有效比较不同世界模型的优劣。
核心思路:WorldArena 的核心思路是构建一个统一的基准,同时评估世界模型的感知能力和功能效用。通过多维度的评估指标,全面衡量世界模型在不同任务中的表现。该基准旨在弥合感知质量与功能效用之间的差距,推动开发真正具有实用价值的具身世界模型。
技术框架:WorldArena 包含以下主要模块:1) 视频感知质量评估模块:使用 16 个指标,从六个子维度评估视频生成质量。2) 具身任务功能性评估模块:将世界模型作为数据引擎、策略评估器和动作规划器进行评估,并结合主观人工评估。3) EWMScore 计算模块:将多维性能整合为单个可解释的指标。整体流程是,给定一个世界模型,首先通过视频感知质量评估模块和具身任务功能性评估模块进行评估,然后使用 EWMScore 计算模块计算综合得分。
关键创新:WorldArena 的关键创新在于其统一的评估框架,能够同时评估世界模型的感知能力和功能效用。此外,EWMScore 指标的提出,为综合评估世界模型的性能提供了一种新的方法。与现有方法相比,WorldArena 更加全面、客观,能够更准确地反映世界模型的真实能力。
关键设计:在视频感知质量评估方面,采用了多种常用的视频质量评估指标,如 PSNR、SSIM 等。在具身任务功能性评估方面,设计了多种不同的具身任务,如导航、操作等,以评估世界模型在不同任务中的表现。EWMScore 指标的计算方式是加权平均,权重根据不同维度的重要性进行调整。具体的参数设置和网络结构取决于被评估的世界模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,高视觉质量的世界模型并不一定具有强大的具身任务能力,揭示了感知-功能差距。通过对 14 个代表性模型的评估,发现部分模型在视频生成质量方面表现出色,但在具身任务中的表现却不尽如人意。WorldArena 基准的发布,为后续研究提供了一个统一的评估平台。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、虚拟现实等领域。通过 WorldArena 基准,可以更有效地评估和选择适合特定任务的世界模型,从而提高机器人的自主性和智能化水平。此外,该基准还可以促进世界模型相关算法的研发,推动具身智能的进步。
📄 摘要(原文)
While world models have emerged as a cornerstone of embodied intelligence by enabling agents to reason about environmental dynamics through action-conditioned prediction, their evaluation remains fragmented. Current evaluation of embodied world models has largely focused on perceptual fidelity (e.g., video generation quality), overlooking the functional utility of these models in downstream decision-making tasks. In this work, we introduce WorldArena, a unified benchmark designed to systematically evaluate embodied world models across both perceptual and functional dimensions. WorldArena assesses models through three dimensions: video perception quality, measured with 16 metrics across six sub-dimensions; embodied task functionality, which evaluates world models as data engines, policy evaluators, and action planners integrating with subjective human evaluation. Furthermore, we propose EWMScore, a holistic metric integrating multi-dimensional performance into a single interpretable index. Through extensive experiments on 14 representative models, we reveal a significant perception-functionality gap, showing that high visual quality does not necessarily translate into strong embodied task capability. WorldArena benchmark with the public leaderboard is released at https://worldarena.ai, providing a framework for tracking progress toward truly functional world models in embodied AI.