Analysis of Converged 3D Gaussian Splatting Solutions: Density Effects and Prediction Limit
作者: Zhendong Wang, Cihan Ruan, Jingchuan Xiao, Chuqing Shi, Wei Jiang, Wei Wang, Wenjie Liu, Nam Ling
分类: cs.CV, cs.LG
发布日期: 2026-02-09
💡 一句话要点
分析3D高斯溅射收敛解:揭示密度效应与预测极限,优化训练鲁棒性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 新视角合成 密度分层 可学习性探针 渲染优化
📋 核心要点
- 现有3D高斯溅射方法缺乏对收敛解结构的深入理解,限制了其优化和泛化能力。
- 通过分析渲染最优参考(RORs)的统计特性,揭示了密度分层现象,并提出了密度感知的训练策略。
- 实验表明,该方法提高了训练的鲁棒性,为自适应平衡前馈预测和渲染细化的系统设计提供了指导。
📝 摘要(中文)
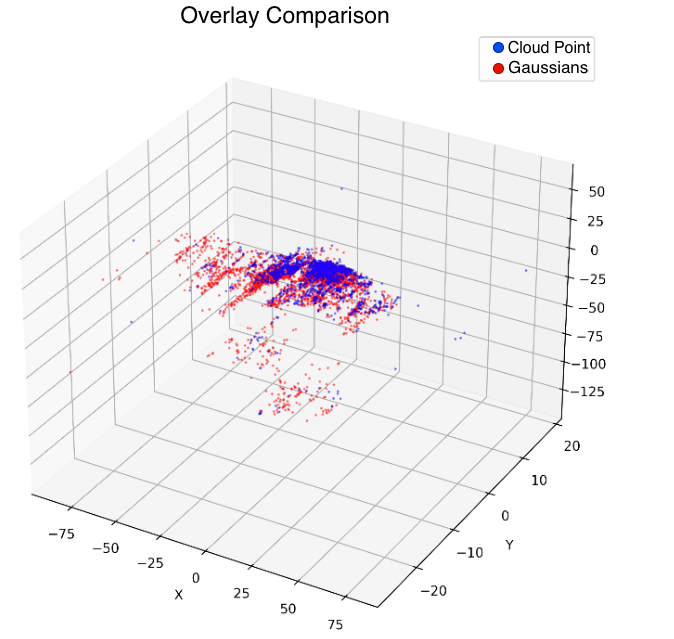
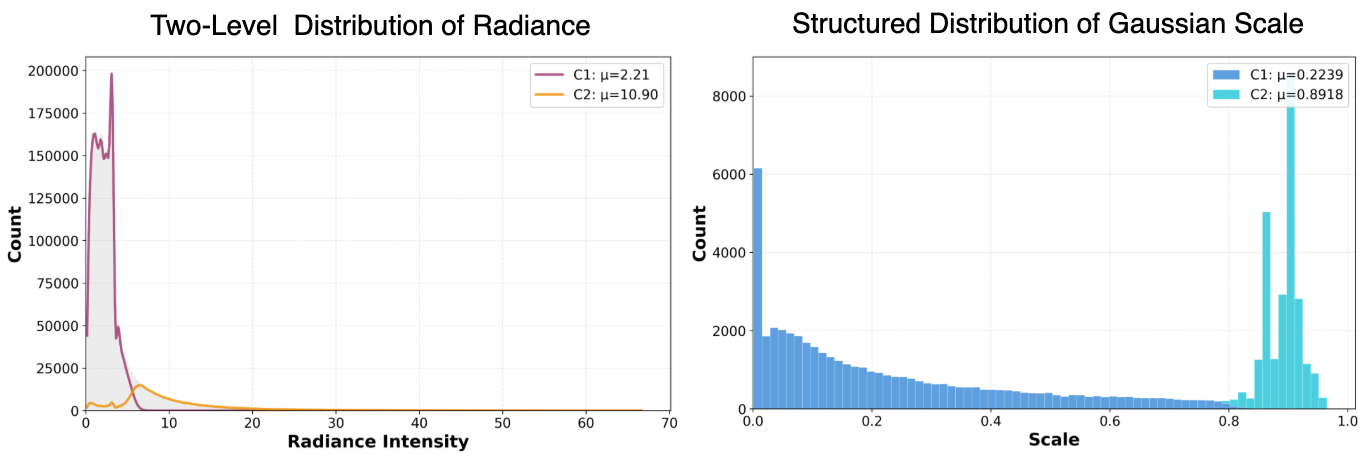
本文研究了标准多视角优化中3D高斯溅射(3DGS)解中涌现的结构。我们将这些结构称为渲染最优参考(RORs),并分析它们的统计特性,揭示了稳定的模式:混合结构尺度和跨不同场景的双峰辐射。为了理解决定这些参数的因素,我们应用可学习性探针,通过训练预测器从点云重建RORs,而无需渲染监督。我们的分析揭示了基本的密度分层现象。密集区域表现出与几何相关的参数,易于无渲染预测,而稀疏区域则表现出跨架构的系统性失败。我们通过方差分解将其形式化,证明了可见性异质性在稀疏区域中创建了几何和外观参数之间以协方差为主的耦合。这揭示了RORs的双重特性:点云足够的几何基元,以及多视角约束必不可少的视图合成基元。我们提供了密度感知的策略,提高了训练的鲁棒性,并讨论了自适应平衡前馈预测和基于渲染的细化的系统的架构影响。
🔬 方法详解
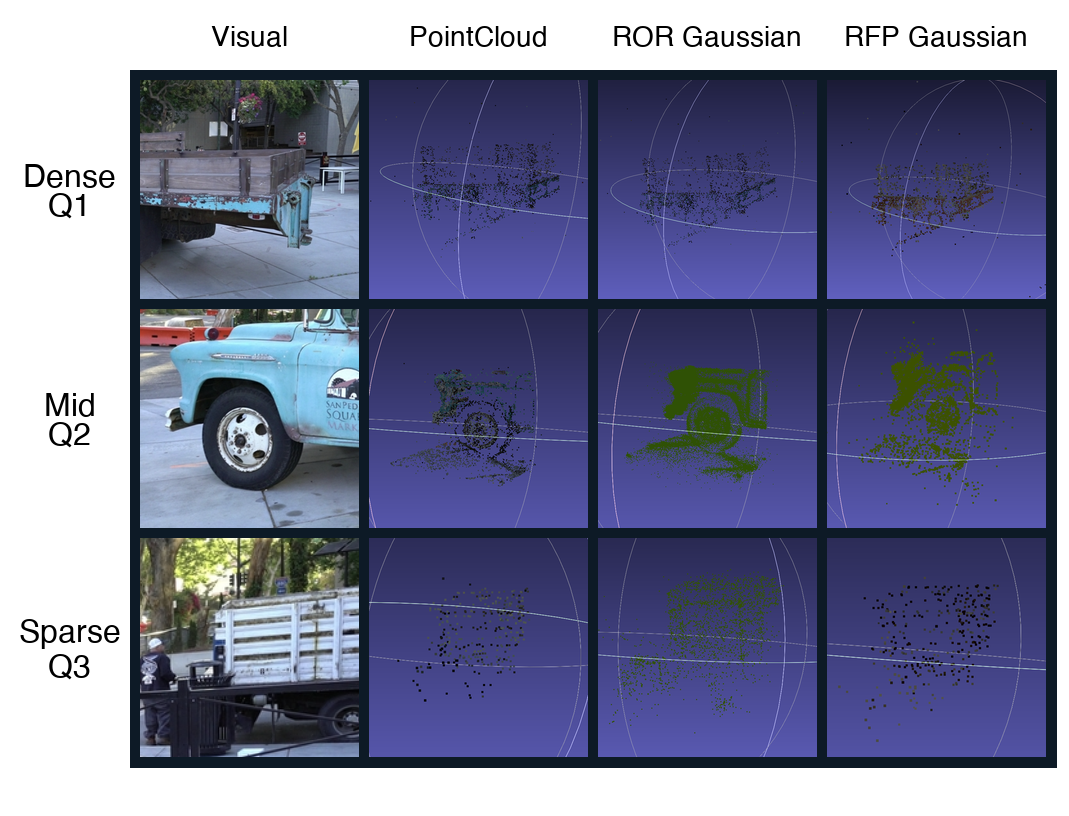
问题定义:现有的3D高斯溅射方法在多视角优化后,其收敛解的结构和性质缺乏深入的理解。特别是,不同密度区域的高斯参数是如何分布的,以及这些参数的可预测性如何,这些问题尚未得到充分研究。这导致了训练过程中的不稳定性和泛化能力的限制。
核心思路:本文的核心思路是通过分析渲染最优参考(RORs)的统计特性,揭示密度与高斯参数之间的关系。通过训练预测器从点云重建RORs,评估不同密度区域参数的可学习性。基于分析结果,提出密度感知的训练策略,以提高训练的鲁棒性。
技术框架:该研究主要包含以下几个阶段:1) 通过标准多视角优化获得3DGS的收敛解,即RORs。2) 分析RORs的统计特性,包括尺度和辐射的分布。3) 训练预测器从点云重建RORs,评估不同密度区域参数的可学习性。4) 通过方差分解,量化几何和外观参数之间的耦合程度。5) 提出密度感知的训练策略,并验证其有效性。
关键创新:该论文的关键创新在于:1) 首次对3DGS收敛解的结构进行了深入的统计分析,揭示了密度分层现象。2) 通过可学习性探针,量化了不同密度区域参数的可预测性。3) 提出了密度感知的训练策略,提高了训练的鲁棒性。
关键设计:论文中,密度感知的训练策略是关键设计之一。具体来说,该策略可能包括:1) 根据密度调整学习率或损失权重。2) 对稀疏区域的高斯参数进行正则化,以减少几何和外观参数之间的耦合。3) 使用密度信息来指导前馈预测和渲染细化的平衡。
🖼️ 关键图片
📊 实验亮点
研究发现,密集区域的高斯参数与几何相关性强,易于无渲染预测,而稀疏区域则表现出系统性预测失败。通过方差分解,证明了稀疏区域中几何和外观参数之间存在以协方差为主的耦合。提出的密度感知策略能够提高训练的鲁棒性,但具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于三维重建、新视角合成、虚拟现实/增强现实等领域。通过理解3DGS的收敛解结构,可以设计更高效、更鲁棒的训练方法,从而提高重建质量和渲染效率。此外,该研究为自适应平衡前馈预测和渲染细化的系统设计提供了理论指导。
📄 摘要(原文)
We investigate what structure emerges in 3D Gaussian Splatting (3DGS) solutions from standard multi-view optimization. We term these Rendering-Optimal References (RORs) and analyze their statistical properties, revealing stable patterns: mixture-structured scales and bimodal radiance across diverse scenes. To understand what determines these parameters, we apply learnability probes by training predictors to reconstruct RORs from point clouds without rendering supervision. Our analysis uncovers fundamental density-stratification. Dense regions exhibit geometry-correlated parameters amenable to render-free prediction, while sparse regions show systematic failure across architectures. We formalize this through variance decomposition, demonstrating that visibility heterogeneity creates covariance-dominated coupling between geometric and appearance parameters in sparse regions. This reveals the dual character of RORs: geometric primitives where point clouds suffice, and view synthesis primitives where multi-view constraints are essential. We provide density-aware strategies that improve training robustness and discuss architectural implications for systems that adaptively balance feed-forward prediction and rendering-based refinement.