TiFRe: Text-guided Video Frame Reduction for Efficient Video Multi-modal Large Language Models
作者: Xiangtian Zheng, Zishuo Wang, Yuxin Peng
分类: cs.CV
发布日期: 2026-02-09
💡 一句话要点
提出TiFRe框架,通过文本引导的视频帧减少提升Video MLLM效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Video MLLM 视频帧减少 文本引导 关键帧提取 多模态学习
📋 核心要点
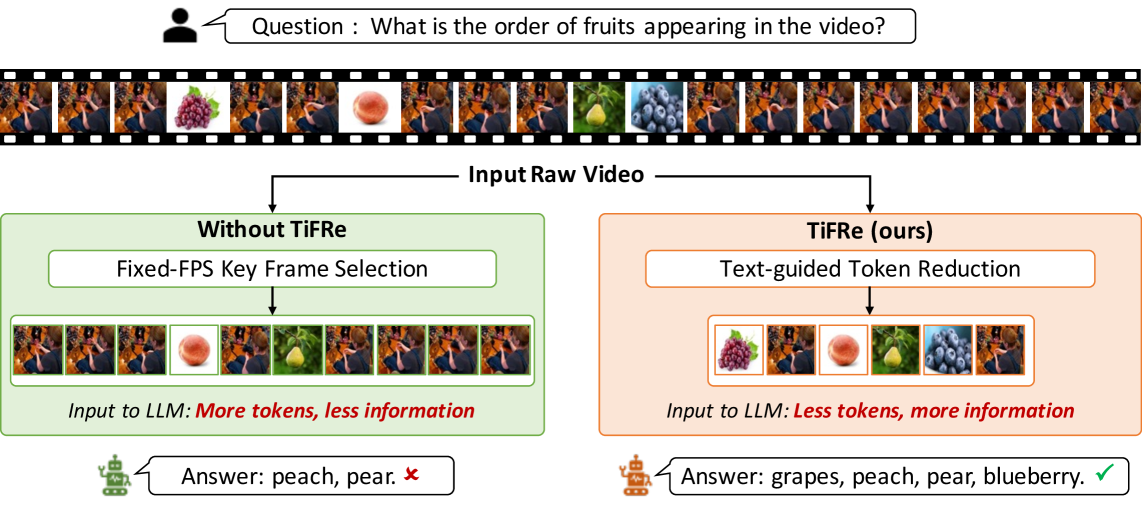
- Video MLLM处理大量视频帧导致计算开销巨大,简单降低帧率会损失关键信息。
- TiFRe通过文本引导帧采样(TFS)和帧匹配合并(FMM)策略,在减少帧数的同时保留关键信息。
- 实验表明,TiFRe能有效降低计算成本,并在视频语言任务上提升性能。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,视频多模态大型语言模型(Video MLLMs)在视频理解和问答等视频语言任务中取得了显著的性能。然而,Video MLLMs面临着高计算成本,特别是在处理大量视频帧作为输入时,这导致了显著的注意力计算开销。减少计算成本的一个直接方法是减少输入视频帧的数量。然而,简单地以固定帧率(FPS)选择关键帧通常会忽略非关键帧中的有价值信息,从而导致显著的性能下降。为了解决这个问题,我们提出了文本引导的视频帧减少(TiFRe)框架,该框架在减少输入帧的同时保留必要的视频信息。TiFRe使用文本引导的帧采样(TFS)策略,根据用户输入选择关键帧,用户输入由LLM处理以生成CLIP风格的提示。预训练的CLIP编码器计算提示和每个帧之间的语义相似性,选择最相关的帧作为关键帧。为了保留视频语义,TiFRe采用帧匹配和合并(FMM)机制,将非关键帧信息集成到所选的关键帧中,从而最大限度地减少信息丢失。实验表明,TiFRe有效地降低了计算成本,同时提高了视频语言任务的性能。
🔬 方法详解
问题定义:Video MLLM在处理视频时,需要处理大量的视频帧,这导致了巨大的计算开销,特别是注意力机制的计算。简单地降低视频帧率虽然可以减少计算量,但会丢失视频中的关键信息,导致性能下降。因此,如何在减少计算量的同时,尽可能保留视频中的关键信息,是本文要解决的问题。
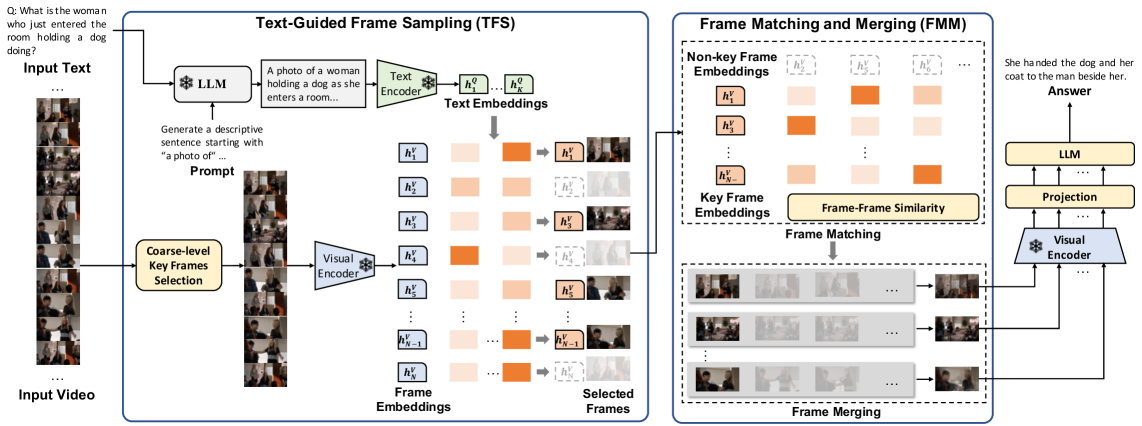
核心思路:本文的核心思路是,利用文本信息来引导视频帧的选择,并采用帧匹配和合并机制来保留视频语义。具体来说,首先利用用户输入的文本信息,生成CLIP风格的prompt,然后利用prompt和视频帧之间的语义相似性来选择关键帧。对于非关键帧,则通过帧匹配和合并机制,将其中的信息融合到关键帧中,从而减少信息损失。
技术框架:TiFRe框架主要包含两个模块:文本引导的帧采样(TFS)和帧匹配和合并(FMM)。首先,TFS模块接收用户输入的文本信息,并利用LLM生成CLIP风格的prompt。然后,利用预训练的CLIP编码器计算prompt和每个视频帧之间的语义相似性,选择相似度最高的帧作为关键帧。接下来,FMM模块将非关键帧的信息融合到关键帧中,从而减少信息损失。最后,将选择的关键帧输入到Video MLLM中进行处理。
关键创新:本文最重要的技术创新点在于,利用文本信息来引导视频帧的选择。与传统的关键帧提取方法不同,本文的方法可以根据用户输入的文本信息,选择与文本信息最相关的视频帧,从而更好地保留视频中的关键信息。此外,本文提出的帧匹配和合并机制,也可以有效地减少信息损失。
关键设计:在TFS模块中,LLM的选择和prompt的生成方式会影响关键帧的选择结果。在FMM模块中,如何有效地将非关键帧的信息融合到关键帧中,是一个关键的设计问题。论文中可能使用了某种加权平均或者注意力机制来实现帧的融合。具体的损失函数和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
TiFRe框架在减少计算成本的同时,提高了视频语言任务的性能。具体实验数据未知,但摘要中提到TiFRe有效地降低了计算成本,同时提高了视频语言任务的性能。与直接降低帧率的方法相比,TiFRe能够更好地保留视频中的关键信息,从而获得更好的性能。
🎯 应用场景
TiFRe框架可应用于各种需要处理视频数据的场景,例如视频问答、视频摘要、视频检索等。通过减少输入视频帧的数量,可以显著降低计算成本,提高处理效率。该研究对于推动Video MLLM在资源受限设备上的应用具有重要意义,并可能促进更高效的视频内容理解和生成。
📄 摘要(原文)
With the rapid development of Large Language Models (LLMs), Video Multi-Modal Large Language Models (Video MLLMs) have achieved remarkable performance in video-language tasks such as video understanding and question answering. However, Video MLLMs face high computational costs, particularly in processing numerous video frames as input, which leads to significant attention computation overhead. A straightforward approach to reduce computational costs is to decrease the number of input video frames. However, simply selecting key frames at a fixed frame rate (FPS) often overlooks valuable information in non-key frames, resulting in notable performance degradation. To address this, we propose Text-guided Video Frame Reduction (TiFRe), a framework that reduces input frames while preserving essential video information. TiFRe uses a Text-guided Frame Sampling (TFS) strategy to select key frames based on user input, which is processed by an LLM to generate a CLIP-style prompt. Pre-trained CLIP encoders calculate the semantic similarity between the prompt and each frame, selecting the most relevant frames as key frames. To preserve video semantics, TiFRe employs a Frame Matching and Merging (FMM) mechanism, which integrates non-key frame information into the selected key frames, minimizing information loss. Experiments show that TiFRe effectively reduces computational costs while improving performance on video-language tasks.