VideoVeritas: AI-Generated Video Detection via Perception Pretext Reinforcement Learning
作者: Hao Tan, Jun Lan, Senyuan Shi, Zichang Tan, Zijian Yu, Huijia Zhu, Weiqiang Wang, Jun Wan, Zhen Lei
分类: cs.CV
发布日期: 2026-02-09
备注: Project: https://github.com/EricTan7/VideoVeritas
💡 一句话要点
VideoVeritas:通过感知预训练强化学习检测AI生成视频
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成视频检测 多模态大语言模型 感知预训练 强化学习 时空定位 自监督学习 内容安全 视频取证
📋 核心要点
- 现有AI生成视频检测方法在细粒度感知能力上存在不足,限制了其检测性能。
- VideoVeritas框架通过联合偏好对齐和感知预训练强化学习(PPRL)来提升模型的感知能力。
- 实验表明,VideoVeritas在多个数据集上取得了更平衡的性能,优于现有方法。
📝 摘要(中文)
视频生成能力的日益增强带来了不断升级的安全风险,使得可靠的检测变得至关重要。本文介绍了一种名为VideoVeritas的框架,该框架集成了细粒度的感知和基于事实的推理。我们观察到,当前的多模态大型语言模型(MLLM)表现出强大的推理能力,但其细粒度感知能力仍然有限。为了缓解这个问题,我们引入了联合偏好对齐和感知预训练强化学习(PPRL)。具体而言,我们没有直接针对检测任务进行优化,而是在强化学习阶段采用了通用的时空定位和自监督对象计数,通过简单的感知预训练任务来提高检测性能。为了方便鲁棒的评估,我们进一步引入了MintVid,这是一个轻量级但高质量的数据集,包含来自9个最先进生成器的3K视频,以及一个包含内容事实错误的真实世界收集子集。实验结果表明,现有方法倾向于偏向于肤浅的推理或机械分析,而VideoVeritas在不同的基准测试中实现了更平衡的性能。
🔬 方法详解
问题定义:当前AI生成视频检测方法,特别是基于多模态大语言模型的方法,虽然具备一定的推理能力,但在细粒度的感知能力上存在不足。这导致模型容易受到生成视频中细微的伪造痕迹的欺骗,从而影响检测的准确性。现有方法要么过于依赖表面推理,要么进行机械分析,缺乏对视频内容深层次的理解。
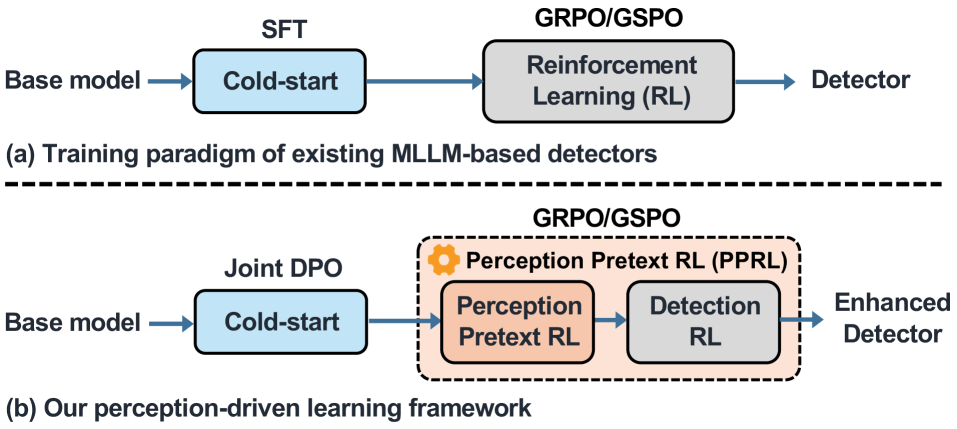
核心思路:VideoVeritas的核心思路是通过感知预训练强化学习(PPRL)来增强模型的感知能力。具体来说,不是直接优化检测任务,而是利用强化学习,通过时空定位和自监督对象计数等感知预训练任务,让模型学习更细粒度的视频内容表示,从而提高检测性能。这种方法旨在弥补多模态大语言模型在感知方面的不足。
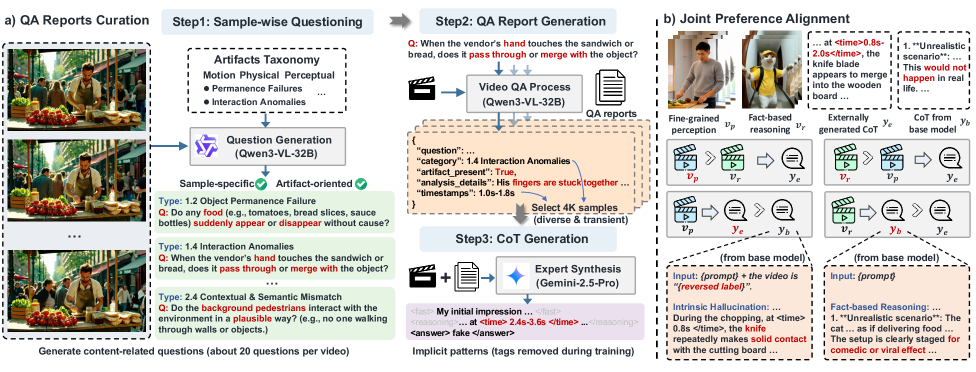
技术框架:VideoVeritas框架主要包含以下几个阶段:首先,利用多模态大语言模型提取视频特征。然后,通过联合偏好对齐,将模型的偏好与人类的偏好对齐,从而提高模型的推理能力。接着,利用感知预训练强化学习(PPRL),通过时空定位和自监督对象计数等任务,增强模型的感知能力。最后,利用增强后的感知能力进行AI生成视频检测。
关键创新:VideoVeritas的关键创新在于提出了感知预训练强化学习(PPRL)方法。与传统的直接优化检测任务的方法不同,PPRL通过引入感知预训练任务,让模型学习更细粒度的视频内容表示,从而提高检测性能。这种方法能够有效弥补多模态大语言模型在感知方面的不足,从而提高AI生成视频检测的准确性。
关键设计:在PPRL中,使用了时空定位和自监督对象计数作为感知预训练任务。时空定位任务旨在让模型学习视频中物体的空间位置和时间变化信息。自监督对象计数任务旨在让模型学习视频中物体的数量信息。此外,论文还提出了联合偏好对齐方法,用于将模型的偏好与人类的偏好对齐。具体的损失函数和网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
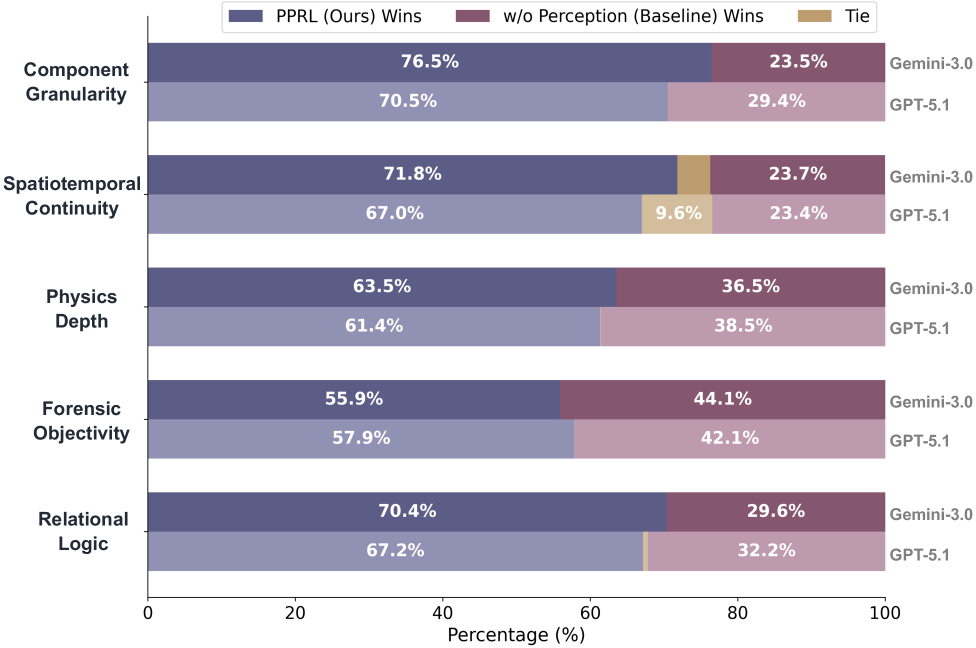
实验结果表明,VideoVeritas在多个AI生成视频检测基准测试中取得了显著的性能提升。与现有方法相比,VideoVeritas在检测准确率和泛化能力方面均有明显优势,尤其是在MintVid数据集上表现出色,证明了其在处理复杂和真实的AI生成视频方面的有效性。
🎯 应用场景
VideoVeritas可应用于网络安全、媒体内容审核、取证分析等领域。通过准确检测AI生成的虚假视频,可以有效防止恶意信息的传播,维护社会稳定和信息安全。该研究的成果有助于提升AI内容安全技术水平,为构建可信赖的AI生态系统做出贡献。
📄 摘要(原文)
The growing capability of video generation poses escalating security risks, making reliable detection increasingly essential. In this paper, we introduce VideoVeritas, a framework that integrates fine-grained perception and fact-based reasoning. We observe that while current multi-modal large language models (MLLMs) exhibit strong reasoning capacity, their granular perception ability remains limited. To mitigate this, we introduce Joint Preference Alignment and Perception Pretext Reinforcement Learning (PPRL). Specifically, rather than directly optimizing for detection task, we adopt general spatiotemporal grounding and self-supervised object counting in the RL stage, enhancing detection performance with simple perception pretext tasks. To facilitate robust evaluation, we further introduce MintVid, a light yet high-quality dataset containing 3K videos from 9 state-of-the-art generators, along with a real-world collected subset that has factual errors in content. Experimental results demonstrate that existing methods tend to bias towards either superficial reasoning or mechanical analysis, while VideoVeritas achieves more balanced performance across diverse benchmarks.