Omni-Video 2: Scaling MLLM-Conditioned Diffusion for Unified Video Generation and Editing
作者: Hao Yang, Zhiyu Tan, Jia Gong, Luozheng Qin, Hesen Chen, Xiaomeng Yang, Yuqing Sun, Yuetan Lin, Mengping Yang, Hao Li
分类: cs.CV
发布日期: 2026-02-09
备注: Technical Report, Project: https://howellyoung-s.github.io/Omni-Video2-project/
💡 一句话要点
Omni-Video 2:扩展MLLM条件扩散模型,实现统一的视频生成与编辑
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 视频编辑 多模态学习 大型语言模型 扩散模型 条件生成 参数高效 视频理解
📋 核心要点
- 现有视频生成和编辑方法难以处理复杂和组合的用户指令,限制了编辑的灵活性和准确性。
- 利用多模态大型语言模型(MLLM)理解用户指令,生成明确的目标字幕,指导视频扩散模型的生成过程。
- 通过轻量级适配器将多模态条件tokens注入预训练的文本到视频扩散模型,高效利用预训练模型的生成能力。
📝 摘要(中文)
Omni-Video 2是一个可扩展且计算高效的模型,它将预训练的多模态大型语言模型(MLLM)与视频扩散模型连接起来,用于统一的视频生成和编辑。其核心思想是利用MLLM的理解和推理能力来生成明确的目标字幕,从而解释用户指令。通过这种方式,来自理解模型的丰富上下文表示被直接用于指导生成过程,从而提高复杂和组合编辑的性能。此外,开发了一个轻量级适配器,将多模态条件tokens注入到预训练的文本到视频扩散模型中,从而以参数高效的方式最大限度地重用其强大的生成先验。受益于这些设计,我们将Omni-Video 2扩展到具有高质量的14B视频扩散模型,支持高质量的文本到视频生成和各种视频编辑任务,例如对象移除、添加、背景更改、复杂运动编辑等。我们在FiVE基准上评估了Omni-Video 2在细粒度视频编辑方面的性能,并在VBench基准上评估了文本到视频生成的性能。结果表明,它在视频编辑中具有遵循复杂组合指令的卓越能力,同时在视频生成任务中也实现了有竞争力或卓越的质量。
🔬 方法详解
问题定义:现有的视频生成和编辑方法在处理复杂和组合的用户指令时存在困难,难以准确理解用户意图并生成符合要求的视频内容。此外,直接使用文本指令控制视频生成和编辑,缺乏对视频内容的细粒度控制能力,导致编辑效果不佳。
核心思路:论文的核心思路是利用多模态大型语言模型(MLLM)的强大理解和推理能力,将用户指令转化为明确的目标字幕。这些目标字幕能够更准确地表达用户意图,并作为视频扩散模型的条件输入,从而指导生成过程。通过这种方式,可以有效地将MLLM的知识迁移到视频生成和编辑任务中。
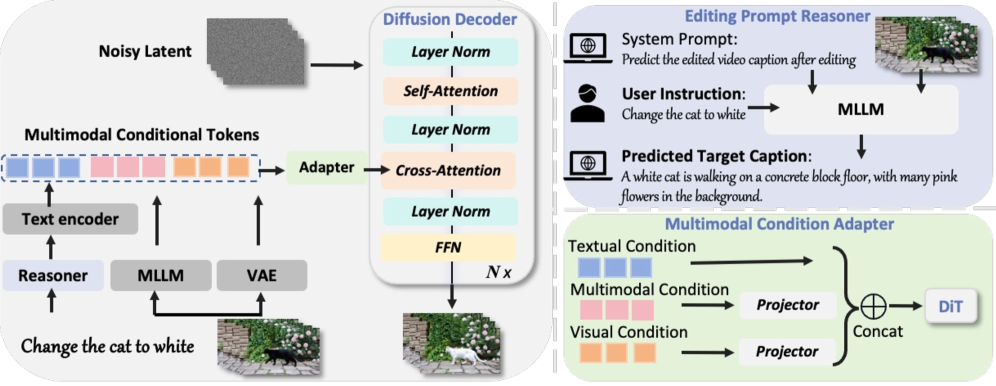
技术框架:Omni-Video 2的整体框架包含以下几个主要模块:1) 多模态大型语言模型(MLLM):负责理解用户指令,并生成目标字幕。2) 轻量级适配器:将MLLM生成的多模态条件tokens注入到预训练的文本到视频扩散模型中。3) 视频扩散模型:基于目标字幕生成或编辑视频。整个流程是:用户输入指令 -> MLLM生成目标字幕 -> 适配器注入条件 -> 扩散模型生成/编辑视频。
关键创新:该论文的关键创新在于将MLLM与视频扩散模型相结合,利用MLLM的理解能力来指导视频生成和编辑过程。此外,轻量级适配器的设计使得可以高效地利用预训练的文本到视频扩散模型的生成先验,避免了从头开始训练模型的巨大开销。
关键设计:轻量级适配器的具体结构未知,但其目标是以参数高效的方式将MLLM的输出(多模态条件tokens)融入到预训练的视频扩散模型中。论文强调了训练数据的质量,并精心策划了训练数据,以提升模型的生成质量和编辑能力。损失函数和网络结构的具体细节未知。
🖼️ 关键图片

📊 实验亮点
Omni-Video 2在FiVE和VBench基准测试中表现出色。在细粒度视频编辑任务中,它能够更好地遵循复杂组合指令,生成更符合用户意图的视频内容。在文本到视频生成任务中,Omni-Video 2也达到了具有竞争力的甚至更优越的生成质量。具体性能数据未知,但论文强调了其在复杂指令理解和生成质量方面的优势。
🎯 应用场景
Omni-Video 2具有广泛的应用前景,包括视频内容创作、电影特效制作、游戏开发、在线教育等领域。它可以帮助用户轻松地生成和编辑高质量的视频内容,降低视频制作的门槛,并为创意表达提供更多可能性。例如,用户可以通过简单的文本指令,快速生成所需的场景、角色和故事情节,或者对现有视频进行精细的编辑和修改。
📄 摘要(原文)
We present Omni-Video 2, a scalable and computationally efficient model that connects pretrained multimodal large-language models (MLLMs) with video diffusion models for unified video generation and editing. Our key idea is to exploit the understanding and reasoning capabilities of MLLMs to produce explicit target captions to interpret user instructions. In this way, the rich contextual representations from the understanding model are directly used to guide the generative process, thereby improving performance on complex and compositional editing. Moreover, a lightweight adapter is developed to inject multimodal conditional tokens into pretrained text-to-video diffusion models, allowing maximum reuse of their powerful generative priors in a parameter-efficient manner. Benefiting from these designs, we scale up Omni-Video 2 to a 14B video diffusion model on meticulously curated training data with quality, supporting high quality text-to-video generation and various video editing tasks such as object removal, addition, background change, complex motion editing, \emph{etc.} We evaluate the performance of Omni-Video 2 on the FiVE benchmark for fine-grained video editing and the VBench benchmark for text-to-video generation. The results demonstrate its superior ability to follow complex compositional instructions in video editing, while also achieving competitive or superior quality in video generation tasks.