Zero-shot System for Automatic Body Region Detection for Volumetric CT and MR Images
作者: Farnaz Khun Jush, Grit Werner, Mark Klemens, Matthias Lenga
分类: cs.CV, cs.AI
发布日期: 2026-02-09
备注: 8 pages, 5 figures, 5 tables
💡 一句话要点
提出零样本方法,利用预训练模型自动检测CT/MR图像中的身体区域
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 身体区域检测 医学影像 CT图像 MR图像
📋 核心要点
- 现有身体区域检测方法依赖不可靠的DICOM元数据和有监督学习,泛化能力受限。
- 提出基于预训练模型和规则的零样本方法,无需训练即可实现CT/MR图像的身体区域检测。
- 实验表明,分割驱动的规则方法在CT和MR图像上均表现出色,加权F1分数分别达到0.947和0.914。
📝 摘要(中文)
可靠地识别解剖身体区域是许多自动化医学成像工作流程的先决条件,但现有解决方案严重依赖于不可靠的DICOM元数据。目前的解决方案主要使用监督学习,这限制了它们在许多实际场景中的适用性。本文研究了是否可以通过使用嵌入在大型预训练基础模型中的知识,以完全零样本的方式实现体积CT和MR图像中的身体区域检测。我们提出并系统地评估了三种无需训练的流程:(1)利用预训练的多器官分割模型的分割驱动的基于规则的系统,(2)由放射科医生定义的规则指导的多模态大型语言模型(MLLM),以及(3)结合视觉输入和显式解剖学证据的分割感知MLLM。所有方法都在887个具有手动验证的解剖区域标签的异构CT和MR扫描上进行评估。分割驱动的基于规则的方法实现了最强和最一致的性能,CT的加权F1分数为0.947,MR的加权F1分数为0.914,证明了跨模态和非典型扫描覆盖的鲁棒性。MLLM在视觉上独特的区域表现出竞争性,而分割感知MLLM揭示了根本的局限性。
🔬 方法详解
问题定义:论文旨在解决医学图像分析中自动身体区域检测的问题。现有方法依赖于DICOM元数据,这些数据通常不准确或缺失,导致检测结果不可靠。此外,现有方法主要采用监督学习,需要大量标注数据,限制了其在实际应用中的泛化能力。因此,需要一种无需训练数据、能够自动且准确地识别身体区域的方法。
核心思路:论文的核心思路是利用预训练的深度学习模型中蕴含的先验知识,构建零样本的身体区域检测系统。通过结合预训练的分割模型和大型语言模型,并辅以人工定义的规则,实现对CT和MR图像中身体区域的自动识别,而无需任何训练数据。这样可以提高系统的鲁棒性和泛化能力,使其能够适应各种不同的扫描协议和图像质量。
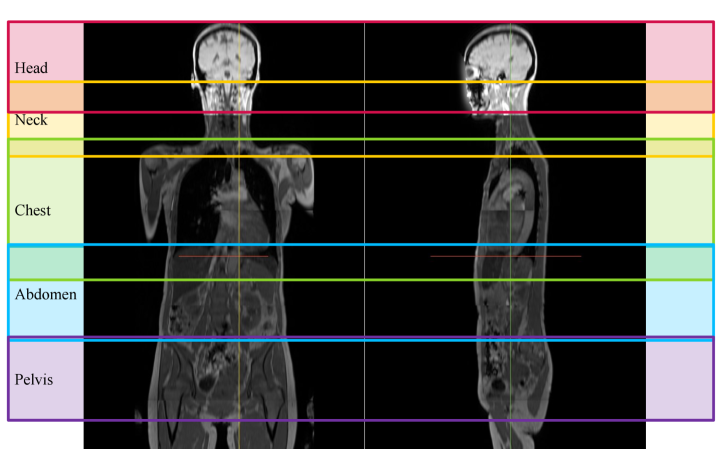
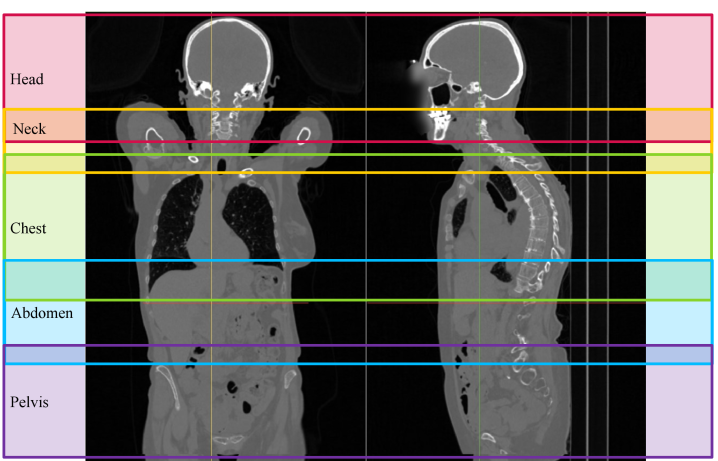
技术框架:论文提出了三种不同的零样本检测流程: 1. 分割驱动的规则系统:首先使用预训练的多器官分割模型对图像进行分割,然后根据分割结果和预定义的规则来确定身体区域。 2. MLLM引导的规则系统:利用多模态大型语言模型(MLLM),结合图像和放射科医生定义的规则,进行身体区域的识别。 3. 分割感知的MLLM系统:将分割结果作为MLLM的输入,结合视觉信息和解剖学证据,进行身体区域的识别。
关键创新:该论文的关键创新在于提出了完全零样本的身体区域检测方法,无需任何训练数据。通过巧妙地利用预训练模型和规则,实现了对CT和MR图像中身体区域的自动识别。这种方法不仅提高了系统的鲁棒性和泛化能力,还降低了对标注数据的依赖,使其更易于部署到实际应用中。
关键设计: * 预训练分割模型:使用了预训练的多器官分割模型,用于提取图像中的解剖结构信息。 * 放射科医生定义的规则:根据放射科医生的经验,定义了一系列规则,用于指导身体区域的识别。 * MLLM的使用:利用MLLM的强大语言理解能力,结合图像和规则,进行身体区域的推理。 * 分割结果的融合:在分割感知的MLLM系统中,将分割结果作为MLLM的输入,以提高识别的准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,分割驱动的规则方法在CT和MR图像上均表现出色,CT的加权F1分数为0.947,MR的加权F1分数为0.914。该方法在跨模态和非典型扫描覆盖方面表现出良好的鲁棒性。MLLM在视觉上独特的区域表现出竞争性,但分割感知MLLM存在局限性。
🎯 应用场景
该研究成果可应用于多种医学影像工作流程,例如自动图像配准、图像检索、辅助诊断和治疗计划。通过自动识别身体区域,可以减少人工干预,提高工作效率,并为临床医生提供更准确的诊断信息。未来,该技术有望应用于更广泛的医学影像领域,例如超声、PET等。
📄 摘要(原文)
Reliable identification of anatomical body regions is a prerequisite for many automated medical imaging workflows, yet existing solutions remain heavily dependent on unreliable DICOM metadata. Current solutions mainly use supervised learning, which limits their applicability in many real-world scenarios. In this work, we investigate whether body region detection in volumetric CT and MR images can be achieved in a fully zero-shot manner by using knowledge embedded in large pre-trained foundation models. We propose and systematically evaluate three training-free pipelines: (1) a segmentation-driven rule-based system leveraging pre-trained multi-organ segmentation models, (2) a Multimodal Large Language Model (MLLM) guided by radiologist-defined rules, and (3) a segmentation-aware MLLM that combines visual input with explicit anatomical evidence. All methods are evaluated on 887 heterogeneous CT and MR scans with manually verified anatomical region labels. The segmentation-driven rule-based approach achieves the strongest and most consistent performance, with weighted F1-scores of 0.947 (CT) and 0.914 (MR), demonstrating robustness across modalities and atypical scan coverage. The MLLM performs competitively in visually distinctive regions, while the segmentation-aware MLLM reveals fundamental limitations.