TimeChat-Captioner: Scripting Multi-Scene Videos with Time-Aware and Structural Audio-Visual Captions
作者: Linli Yao, Yuancheng Wei, Yaojie Zhang, Lei Li, Xinlong Chen, Feifan Song, Ziyue Wang, Kun Ouyang, Yuanxin Liu, Lingpeng Kong, Qi Liu, Pengfei Wan, Kun Gai, Yuanxing Zhang, Xu Sun
分类: cs.CV
发布日期: 2026-02-09
🔗 代码/项目: GITHUB
💡 一句话要点
提出Omni Dense Captioning以生成时间感知的多场景视频描述
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多模态融合 时间感知 结构化描述 音视频推理
📋 核心要点
- 现有方法在生成多场景视频描述时,往往缺乏时间感知和结构化,导致语义覆盖不全。
- 本文提出Omni Dense Captioning任务,通过六维结构框架生成剧本式字幕,增强视频内容的可想象性。
- TimeChat-Captioner-7B模型在多个基准测试中表现优异,超越Gemini-2.5-Pro,显著提升了音视频推理能力。
📝 摘要(中文)
本文提出了一种新任务Omni Dense Captioning,旨在生成连续、细致且结构化的音视频叙述,并附有明确的时间戳。为确保语义的密集覆盖,我们引入了六维结构框架,创建“剧本式”字幕,使读者能够逐场景生动想象视频内容。为促进研究,我们构建了高质量的人类标注基准OmniDCBench,并提出了SodaM这一统一评估指标,以评估时间感知的详细描述,同时减少场景边界模糊性。此外,我们构建了训练数据集TimeChatCap-42K,并提出了基线模型TimeChat-Captioner-7B,通过SFT和GRPO进行训练,结合任务特定奖励。实验结果表明,TimeChat-Captioner-7B在性能上超越了Gemini-2.5-Pro,其生成的密集描述显著提升了音视频推理和时间定位的下游能力。
🔬 方法详解
问题定义:本文旨在解决现有视频描述方法在时间感知和结构化方面的不足,导致生成的描述缺乏连贯性和语义覆盖。
核心思路:通过引入六维结构框架,创建“剧本式”字幕,使得描述不仅具备时间信息,还能清晰展现视频的多场景内容,增强观众的理解和想象。
技术框架:整体架构包括数据集构建、模型训练和评估三个主要阶段。首先构建高质量的训练数据集TimeChatCap-42K,然后训练TimeChat-Captioner-7B模型,最后使用SodaM指标进行评估。
关键创新:最重要的创新在于引入六维结构框架和SodaM评估指标,前者使得生成的描述更具结构性和时间感知,后者有效减少了场景边界模糊性。
关键设计:模型采用SFT和GRPO训练策略,结合任务特定奖励进行优化,确保生成描述的质量和准确性。
🖼️ 关键图片
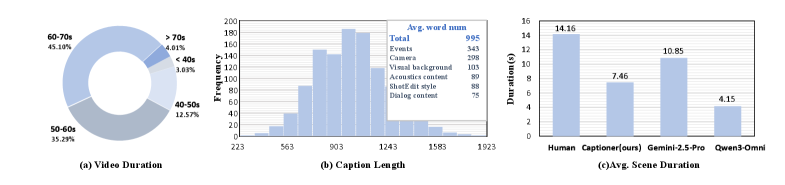
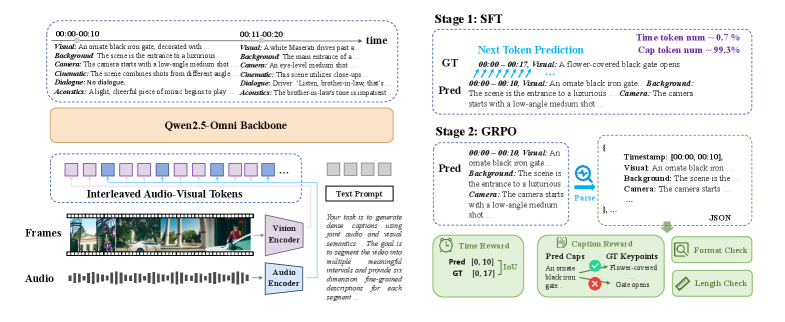

📊 实验亮点
实验结果显示,TimeChat-Captioner-7B在多个基准测试中表现出色,超越了Gemini-2.5-Pro,尤其在音视频推理(DailyOmni和WorldSense)和时间定位(Charades-STA)任务中,生成的密集描述显著提升了模型的性能。
🎯 应用场景
该研究在多媒体内容生成、视频理解和人机交互等领域具有广泛的应用潜力。通过生成结构化的音视频描述,可以提升视频检索、推荐系统和教育培训等场景的用户体验,未来可能推动智能视频分析和内容创作的进一步发展。
📄 摘要(原文)
This paper proposes Omni Dense Captioning, a novel task designed to generate continuous, fine-grained, and structured audio-visual narratives with explicit timestamps. To ensure dense semantic coverage, we introduce a six-dimensional structural schema to create "script-like" captions, enabling readers to vividly imagine the video content scene by scene, akin to a cinematographic screenplay. To facilitate research, we construct OmniDCBench, a high-quality, human-annotated benchmark, and propose SodaM, a unified metric that evaluates time-aware detailed descriptions while mitigating scene boundary ambiguity. Furthermore, we construct a training dataset, TimeChatCap-42K, and present TimeChat-Captioner-7B, a strong baseline trained via SFT and GRPO with task-specific rewards. Extensive experiments demonstrate that TimeChat-Captioner-7B achieves state-of-the-art performance, surpassing Gemini-2.5-Pro, while its generated dense descriptions significantly boost downstream capabilities in audio-visual reasoning (DailyOmni and WorldSense) and temporal grounding (Charades-STA). All datasets, models, and code will be made publicly available at https://github.com/yaolinli/TimeChat-Captioner.