OneVision-Encoder: Codec-Aligned Sparsity as a Foundational Principle for Multimodal Intelligence
作者: Feilong Tang, Xiang An, Yunyao Yan, Yin Xie, Bin Qin, Kaicheng Yang, Yifei Shen, Yuanhan Zhang, Chunyuan Li, Shikun Feng, Changrui Chen, Huajie Tan, Ming Hu, Manyuan Zhang, Bo Li, Ziyong Feng, Ziwei Liu, Zongyuan Ge, Jiankang Deng
分类: cs.CV
发布日期: 2026-02-09
💡 一句话要点
OneVision-Encoder:编解码器对齐的稀疏性作为多模态智能的基础原则
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 视觉编码器 稀疏性 多模态学习 编解码器对齐 3D RoPE 大规模训练
📋 核心要点
- 现有视觉架构对密集像素网格进行均匀处理,浪费大量计算资源在静态背景上,而忽略了定义运动和意义的预测残差。
- OneVision-Encoder通过编解码器分块,专注于信号熵丰富的区域,并采用共享的3D RoPE统一空间和时间推理。
- 实验表明,OV-Encoder在多个视觉理解任务中优于现有模型,证明了编解码器对齐的稀疏性是视觉通用模型的基础。
📝 摘要(中文)
本文提出了一种新的视觉编码器OneVision-Encoder (OV-Encoder),其核心假设是:通用人工智能本质上是一个压缩问题。有效的压缩需要共振,深度学习的最佳扩展方式是使其架构与数据的基本结构对齐。OV-Encoder通过将预测性视觉结构压缩为语义意义来编码视频。通过采用编解码器分块,OV-Encoder放弃了均匀计算,专注于信号熵丰富的3.1%-25%的区域。为了在不规则的token布局下统一空间和时间推理,OV-Encoder采用共享的3D RoPE,并使用超过一百万个语义概念的大规模聚类判别目标进行训练,共同捕获对象持久性和运动动态。实验结果表明,效率和准确性不是权衡,而是正相关的。当集成到LLM中时,OV-Encoder在16个图像、视频和文档理解基准测试中始终优于Qwen3-ViT和SigLIP2等强大的视觉骨干网络,尽管使用的视觉token和预训练数据明显更少。在视频理解任务中,OV-Encoder比Qwen3-ViT平均提高了4.1%。编解码器对齐的patch级别稀疏性是一个基本原则,使OV-Encoder成为下一代视觉通用模型的引擎。
🔬 方法详解
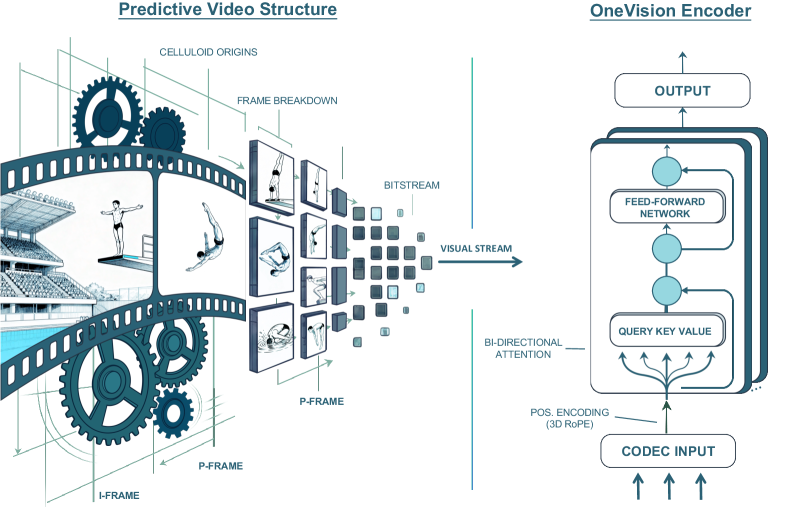
问题定义:现有视觉模型通常对所有像素进行同等处理,忽略了视频数据中信息分布的不均匀性。大量计算资源被浪费在静态背景上,而真正重要的、包含运动和语义信息的区域却没有得到足够的关注。这导致了计算效率低下,并且限制了模型在复杂视觉任务中的表现。
核心思路:本文的核心思路是利用视频编解码器的原理,将视觉信息压缩到最关键的区域。通过识别并专注于信息熵高的区域(例如,运动发生的区域,或者包含重要对象的区域),模型可以更有效地利用计算资源,并更好地理解视频内容。这种编解码器对齐的稀疏性是提高视觉模型效率和准确性的关键。
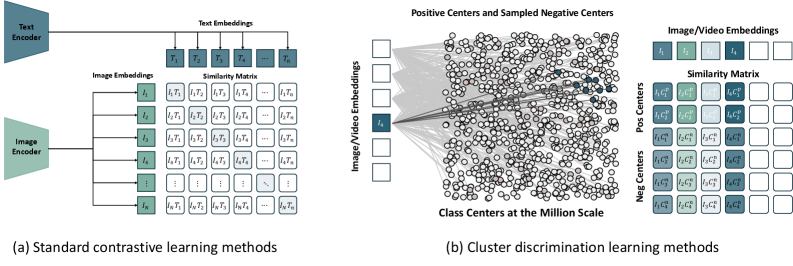
技术框架:OneVision-Encoder (OV-Encoder) 的整体框架包括以下几个主要步骤:1) Codec Patchification: 使用编解码器原理对输入视频帧进行分块,只保留信息熵高的区域。2) 特征提取: 对保留的区域提取特征。3) 时空推理: 使用共享的3D RoPE (Rotary Positional Embedding) 来统一处理空间和时间信息,从而理解对象持久性和运动动态。4) 大规模聚类判别训练: 使用超过一百万个语义概念进行训练,提高模型的语义理解能力。
关键创新:最重要的技术创新点在于编解码器对齐的稀疏性。与传统的密集计算方法不同,OV-Encoder只关注视频中信息量最大的区域,从而大大提高了计算效率。此外,使用共享的3D RoPE可以有效地统一空间和时间推理,使得模型能够更好地理解视频中的运动和对象关系。
关键设计:OV-Encoder的关键设计包括:1) Codec Patchification: 具体实现方式未知,但目标是选择性地保留信息熵高的patch。2) 共享3D RoPE: 使用旋转位置编码来表示空间和时间位置信息,具体参数设置未知。3) 大规模聚类判别目标: 使用超过一百万个语义概念进行训练,损失函数和具体训练策略未知。
🖼️ 关键图片

📊 实验亮点
OneVision-Encoder在16个图像、视频和文档理解基准测试中始终优于Qwen3-ViT和SigLIP2等强大的视觉骨干网络,尽管使用的视觉token和预训练数据明显更少。在视频理解任务中,OV-Encoder比Qwen3-ViT平均提高了4.1%。这些结果表明,编解码器对齐的稀疏性是提高视觉模型效率和准确性的有效方法。
🎯 应用场景
OneVision-Encoder具有广泛的应用前景,包括视频理解、智能监控、自动驾驶、机器人导航等领域。通过提高视觉模型的效率和准确性,OV-Encoder可以帮助这些应用更好地理解和处理视觉信息,从而实现更智能、更可靠的功能。此外,OV-Encoder还可以作为视觉骨干网络集成到大型语言模型中,从而提高多模态理解能力。
📄 摘要(原文)
Hypothesis. Artificial general intelligence is, at its core, a compression problem. Effective compression demands resonance: deep learning scales best when its architecture aligns with the fundamental structure of the data. These are the fundamental principles. Yet, modern vision architectures have strayed from these truths: visual signals are highly redundant, while discriminative information, the surprise, is sparse. Current models process dense pixel grids uniformly, wasting vast compute on static background rather than focusing on the predictive residuals that define motion and meaning. We argue that to solve visual understanding, we must align our architectures with the information-theoretic principles of video, i.e., Codecs. Method. OneVision-Encoder encodes video by compressing predictive visual structure into semantic meaning. By adopting Codec Patchification, OV-Encoder abandons uniform computation to focus exclusively on the 3.1%-25% of regions rich in signal entropy. To unify spatial and temporal reasoning under irregular token layouts, OneVision-Encoder employs a shared 3D RoPE and is trained with a large-scale cluster discrimination objective over more than one million semantic concepts, jointly capturing object permanence and motion dynamics. Evidence. The results validate our core hypothesis: efficiency and accuracy are not a trade-off; they are positively correlated. When integrated into LLM, it consistently outperforms strong vision backbones such as Qwen3-ViT and SigLIP2 across 16 image, video, and document understanding benchmarks, despite using substantially fewer visual tokens and pretraining data. Notably, on video understanding tasks, OV-Encoder achieves an average improvement of 4.1% over Qwen3-ViT. Codec-aligned, patch-level sparsity is a foundational principle, enabling OV-Encoder as a scalable engine for next-generation visual generalists.