ALIVE: Animate Your World with Lifelike Audio-Video Generation
作者: Ying Guo, Qijun Gan, Yifu Zhang, Jinlai Liu, Yifei Hu, Pan Xie, Dongjun Qian, Yu Zhang, Ruiqi Li, Yuqi Zhang, Ruibiao Lu, Xiaofeng Mei, Bo Han, Xiang Yin, Bingyue Peng, Zehuan Yuan
分类: cs.CV
发布日期: 2026-02-09
🔗 代码/项目: GITHUB
💡 一句话要点
ALIVE:通过逼真的音视频生成技术,赋予世界生机
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频生成 跨模态融合 时间对齐 文本到视频 参考动画 MMDiT架构 深度学习
📋 核心要点
- 现有文本到视频模型缺乏对音频的有效整合,难以实现逼真的音视频同步生成和动画。
- ALIVE模型通过引入联合音视频分支和时序对齐的跨模态融合机制,实现了高质量的音视频生成。
- ALIVE在百万级高质量数据集上训练,并在新基准测试中超越开源模型,媲美商业解决方案。
📝 摘要(中文)
本文提出了ALIVE,一个将预训练的文本到视频(T2V)模型适配到Sora风格的音视频生成和动画的模型。与T2V基础模型相比,该模型解锁了文本到视频和音频(T2VA)以及参考到视频和音频(动画)的能力。为了支持音视频同步和参考动画,我们使用联合音视频分支增强了流行的MMDiT架构,该分支包括用于时间对齐的跨模态融合的TA-CrossAttn和用于精确音视频对齐的UniTemp-RoPE。同时,精心设计了一个包含音视频字幕、质量控制等的综合数据管道,以收集高质量的微调数据。此外,我们引入了一个新的基准来执行全面的模型测试和比较。经过百万级高质量数据的持续预训练和微调,ALIVE表现出卓越的性能,始终优于开源模型,并达到或超过了最先进的商业解决方案。我们希望通过详细的方案和基准,ALIVE能够帮助社区更有效地开发音视频生成模型。
🔬 方法详解
问题定义:现有文本到视频(T2V)模型主要关注视觉内容的生成,缺乏对音频信息的有效利用,导致生成的视频缺乏逼真的声音效果,难以实现音视频的同步和协调。此外,如何根据参考视频生成具有相似动作和风格的音视频动画也是一个挑战。
核心思路:ALIVE的核心思路是将预训练的T2V模型扩展到音视频领域,通过引入音频分支和跨模态融合机制,使模型能够同时理解和生成视觉和听觉信息。通过高质量的数据集和精细的训练策略,提升音视频同步的准确性和生成内容的逼真度。
技术框架:ALIVE模型基于MMDiT架构,并在此基础上增加了一个联合音视频分支。该分支包含两个关键模块:TA-CrossAttn(Temporally-Aligned Cross-Attention)用于在时间维度上对齐音频和视频特征,实现跨模态融合;UniTemp-RoPE(Unified Temporal Rotary Positional Embedding)用于精确地对齐音视频的时间位置信息。整个流程包括数据收集与预处理、模型预训练、模型微调和评估四个阶段。
关键创新:ALIVE的关键创新在于其联合音视频分支的设计,特别是TA-CrossAttn和UniTemp-RoPE模块。TA-CrossAttn能够有效地融合音频和视频特征,而UniTemp-RoPE则能够精确地对齐音视频的时间信息,从而保证了生成内容的音视频同步和协调。与现有方法相比,ALIVE更注重音视频之间的关联性,并采用了专门的模块来处理时间对齐问题。
关键设计:在数据方面,ALIVE构建了一个包含音视频字幕和质量控制的综合数据管道,以确保训练数据的高质量。在模型训练方面,ALIVE采用了持续预训练和微调的策略,首先在大量数据上进行预训练,然后在特定任务上进行微调。损失函数方面,可能采用了多种损失函数的组合,例如重建损失、对抗损失和跨模态对齐损失等。具体的网络结构细节和参数设置在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
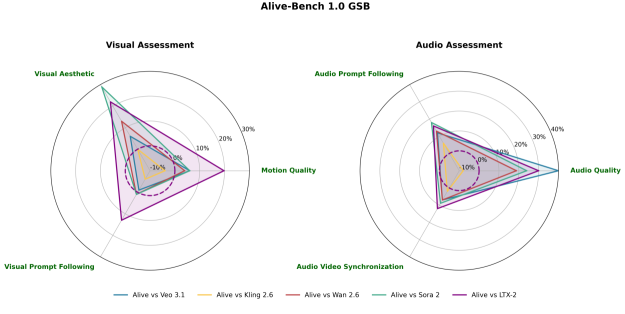


📊 实验亮点
ALIVE在音视频生成任务上表现出色,显著优于现有的开源模型,并在某些指标上达到甚至超过了最先进的商业解决方案。具体性能数据和对比基线需要在论文中查找(未知),但摘要中明确指出ALIVE在一致性上优于开源模型,并能媲美商业模型。
🎯 应用场景
ALIVE技术可广泛应用于内容创作、虚拟现实、游戏开发、教育娱乐等领域。例如,可以根据文本描述自动生成带有逼真音效的动画短片,或者根据参考视频生成具有相似风格的音视频内容。该技术有望降低音视频内容创作的门槛,并为用户提供更加沉浸式的体验。
📄 摘要(原文)
Video generation is rapidly evolving towards unified audio-video generation. In this paper, we present ALIVE, a generation model that adapts a pretrained Text-to-Video (T2V) model to Sora-style audio-video generation and animation. In particular, the model unlocks the Text-to-Video&Audio (T2VA) and Reference-to-Video&Audio (animation) capabilities compared to the T2V foundation models. To support the audio-visual synchronization and reference animation, we augment the popular MMDiT architecture with a joint audio-video branch which includes TA-CrossAttn for temporally-aligned cross-modal fusion and UniTemp-RoPE for precise audio-visual alignment. Meanwhile, a comprehensive data pipeline consisting of audio-video captioning, quality control, etc., is carefully designed to collect high-quality finetuning data. Additionally, we introduce a new benchmark to perform a comprehensive model test and comparison. After continue pretraining and finetuning on million-level high-quality data, ALIVE demonstrates outstanding performance, consistently outperforming open-source models and matching or surpassing state-of-the-art commercial solutions. With detailed recipes and benchmarks, we hope ALIVE helps the community develop audio-video generation models more efficiently. Official page: https://github.com/FoundationVision/Alive.