Improving Reconstruction of Representation Autoencoder
作者: Siyu Liu, Chujie Qin, Hubery Yin, Qixin Yan, Zheng-Peng Duan, Chen Li, Jing Lyu, Chun-Le Guo, Chongyi Li
分类: cs.CV
发布日期: 2026-02-09
🔗 代码/项目: GITHUB
💡 一句话要点
提出LV-RAE,通过增强低层信息和优化解码器,提升表征自编码器的图像重建和生成质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表征自编码器 图像重建 潜在扩散模型 低层信息 解码器鲁棒性
📋 核心要点
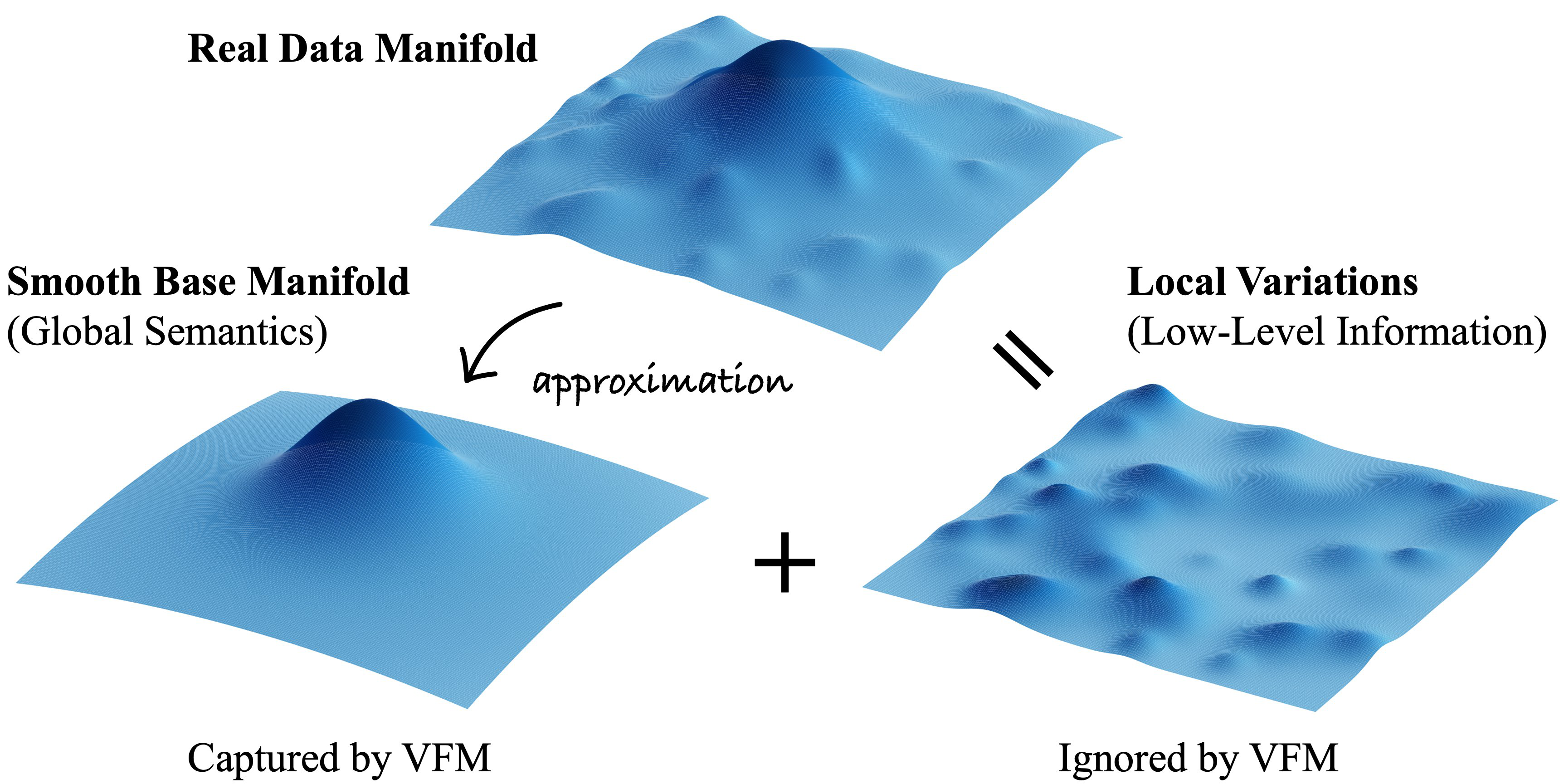
- 现有基于视觉基础模型的潜在扩散模型在图像重建时,由于语义特征缺乏低层信息,导致重建质量下降。
- LV-RAE通过增强语义特征的低层信息,并微调解码器鲁棒性,从而提升重建保真度和生成质量。
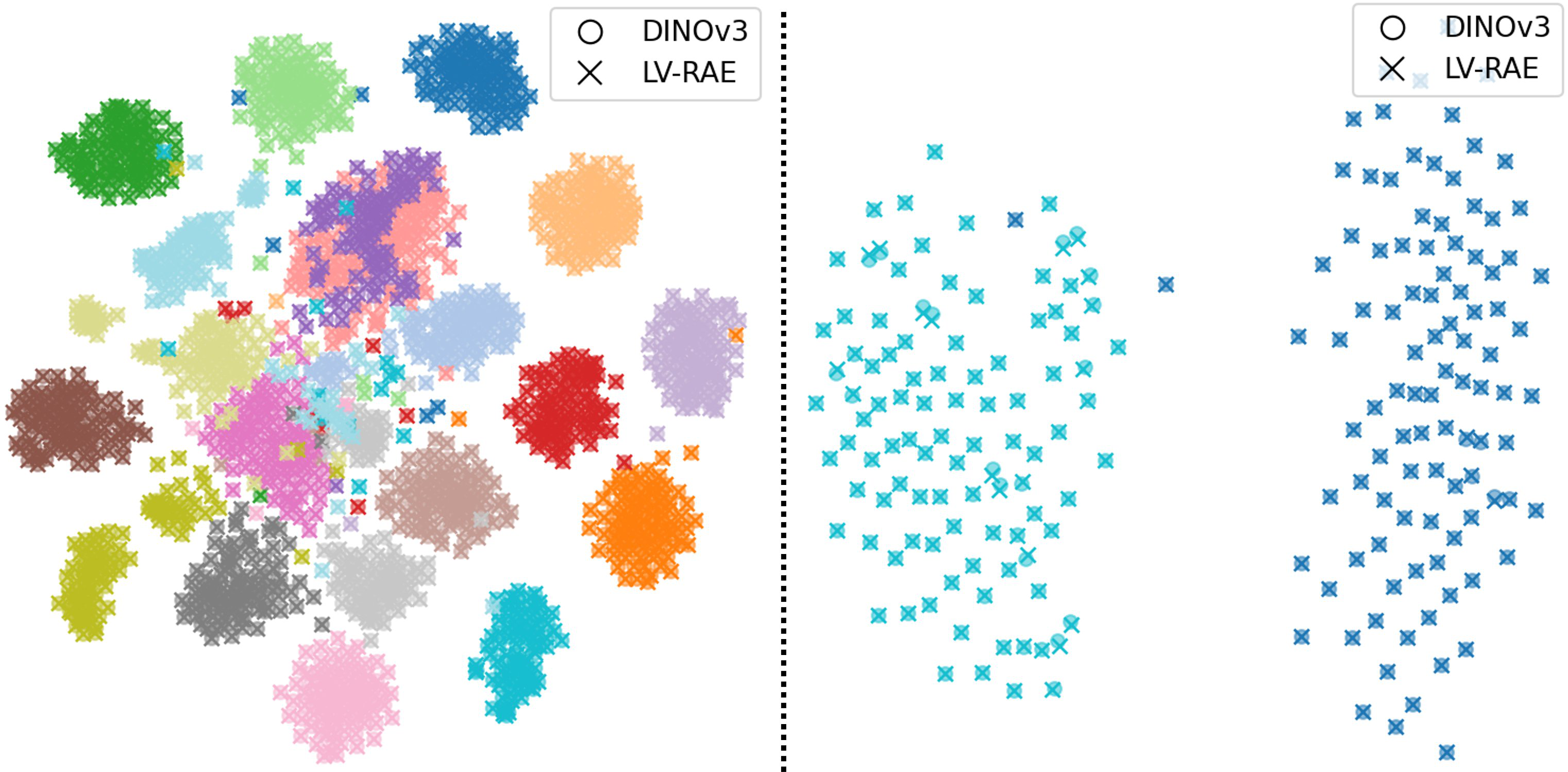
- 实验结果表明,LV-RAE在保持语义抽象能力的同时,显著提高了重建保真度,并实现了强大的生成质量。
📝 摘要(中文)
本文提出了一种表征自编码器LV-RAE,旨在提升潜在扩散模型(LDM)的图像重建保真度。现有方法利用视觉基础模型作为图像编码器,虽然提升了生成性能,但语义特征缺乏颜色和纹理等低层信息,导致重建质量下降。LV-RAE通过增强语义特征的低层信息,实现高保真重建,同时保持与语义分布的高度一致性。此外,论文还观察到高维潜在空间使得解码器对扰动敏感,导致生成伪影。为此,论文提出微调解码器以增强其鲁棒性,并通过受控噪声注入平滑生成的潜在变量,从而提高生成质量。实验表明,LV-RAE显著提高了重建保真度,同时保持了语义抽象能力,并实现了强大的生成质量。
🔬 方法详解
问题定义:现有方法利用视觉基础模型作为图像编码器来提升潜在扩散模型的生成性能,但这些语义特征通常缺乏颜色、纹理等低层信息,导致重建保真度降低。这成为进一步扩展潜在扩散模型的一个主要瓶颈。因此,论文旨在解决如何提升表征自编码器的图像重建保真度问题,同时保持其语义抽象能力。
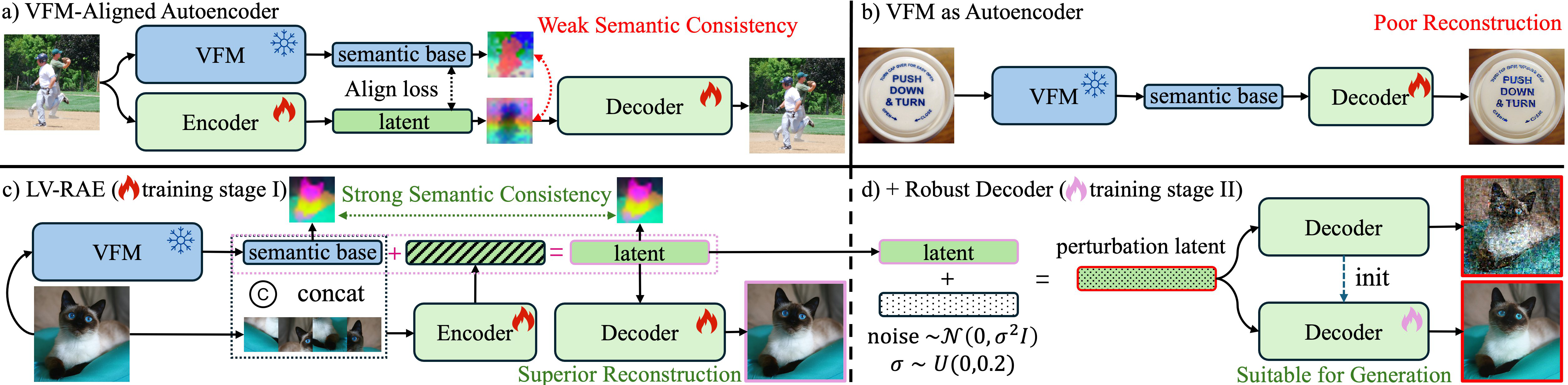
核心思路:论文的核心思路是,首先通过增强语义特征的低层信息来提升重建保真度,然后通过提高解码器的鲁棒性来提升生成质量。具体来说,就是设计一个能够同时编码语义信息和低层信息的表征自编码器,并针对解码器对潜在空间扰动敏感的问题进行优化。
技术框架:LV-RAE的整体框架包含一个编码器和一个解码器。编码器负责将输入图像编码成包含语义信息和低层信息的潜在表示。解码器负责将潜在表示解码成重建图像。为了提高解码器的鲁棒性,论文还引入了微调解码器和噪声注入两个模块。
关键创新:论文的关键创新点在于:1) 提出了一种能够同时编码语义信息和低层信息的表征自编码器LV-RAE;2) 针对解码器对潜在空间扰动敏感的问题,提出了微调解码器和噪声注入两种方法,从而提高了生成质量。与现有方法相比,LV-RAE能够更好地平衡重建保真度和生成质量。
关键设计:在编码器方面,论文可能采用了某种融合语义特征和低层特征的策略,具体实现细节未知。在解码器方面,论文通过微调解码器来提高其鲁棒性,具体微调方法未知。此外,论文还通过受控噪声注入来平滑生成的潜在变量,具体噪声注入策略未知。损失函数的设计也未知,但可能包含重建损失和对抗损失等。
🖼️ 关键图片
📊 实验亮点
论文实验结果表明,LV-RAE显著提高了重建保真度,同时保持了语义抽象能力,并实现了强大的生成质量。具体的性能数据和对比基线未知,但摘要中强调了“显著提高”,表明LV-RAE在重建和生成质量方面取得了实质性进展。
🎯 应用场景
该研究成果可应用于图像生成、图像编辑、图像修复等领域。通过提升图像重建和生成质量,可以改善用户体验,并为相关应用带来更高的实用价值。例如,在图像编辑中,可以更精确地修改图像细节;在图像修复中,可以更真实地还原图像内容。
📄 摘要(原文)
Recent work leverages Vision Foundation Models as image encoders to boost the generative performance of latent diffusion models (LDMs), as their semantic feature distributions are easy to learn. However, such semantic features often lack low-level information (\eg, color and texture), leading to degraded reconstruction fidelity, which has emerged as a primary bottleneck in further scaling LDMs. To address this limitation, we propose LV-RAE, a representation autoencoder that augments semantic features with missing low-level information, enabling high-fidelity reconstruction while remaining highly aligned with the semantic distribution. We further observe that the resulting high-dimensional, information-rich latent make decoders sensitive to latent perturbations, causing severe artifacts when decoding generated latent and consequently degrading generation quality. Our analysis suggests that this sensitivity primarily stems from excessive decoder responses along directions off the data manifold. Building on these insights, we propose fine-tuning the decoder to increase its robustness and smoothing the generated latent via controlled noise injection, thereby enhancing generation quality. Experiments demonstrate that LV-RAE significantly improves reconstruction fidelity while preserving the semantic abstraction and achieving strong generative quality. Our code is available at https://github.com/modyu-liu/LVRAE.