SemiNFT: Learning to Transfer Presets from Imitation to Appreciation via Hybrid-Sample Reinforcement Learning
作者: Melany Yang, Yuhang Yu, Diwang Weng, Jinwei Chen, Wei Dong
分类: cs.CV
发布日期: 2026-02-09
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SemiNFT:通过混合样本强化学习,实现从模仿到欣赏的预设迁移
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 色彩修饰 预设迁移 扩散模型 强化学习 审美感知 图像风格迁移 DiT 混合奖励机制
📋 核心要点
- 现有基于参考图像的色彩修饰方法缺乏对语义和审美的理解,仅依赖像素级统计进行全局颜色映射。
- SemiNFT框架模仿人类艺术训练过程,先通过模仿学习结构和颜色映射,再通过强化学习提升审美感知。
- 实验表明SemiNFT在预设迁移、黑白照片着色和跨域迁移等任务上超越现有方法,展现出卓越的智能。
📝 摘要(中文)
逼真的色彩修饰在视觉内容创作中至关重要,但由于依赖专业知识,手动修饰对于非专业人士来说仍然难以企及。基于参考图像的方法通过将参考图像的预设颜色迁移到源图像提供了一种有前景的替代方案。然而,这些方法通常像新手学习者一样运作,执行从像素级统计数据导出的全局颜色映射,而没有真正理解语义上下文或人类审美。为了解决这个问题,我们提出了SemiNFT,一个基于扩散Transformer (DiT) 的修饰框架,它反映了人类艺术训练的轨迹:从严格的模仿开始,发展到直观的创作。具体来说,SemiNFT首先通过配对的三元组进行训练,以获得基本的结构保持和颜色映射技能,然后通过非配对数据的强化学习 (RL) 提升到细致的审美感知。至关重要的是,在RL阶段,为了防止旧技能的灾难性遗忘,我们设计了一种混合的在线-离线奖励机制,通过结构审查来锚定审美探索。大量的实验表明,SemiNFT不仅在标准预设迁移基准上优于最先进的方法,而且在零样本任务中也表现出卓越的智能,例如黑白照片着色和跨域(动漫到照片)预设迁移。这些结果证实,SemiNFT超越了简单的统计匹配,达到了复杂的审美理解水平。
🔬 方法详解
问题定义:论文旨在解决现有基于参考图像的色彩修饰方法缺乏对图像语义和人类审美的理解,导致修饰效果不佳的问题。现有方法通常只关注像素级别的统计信息,进行全局的颜色映射,而忽略了图像的内容和结构,以及人类对美的感知。
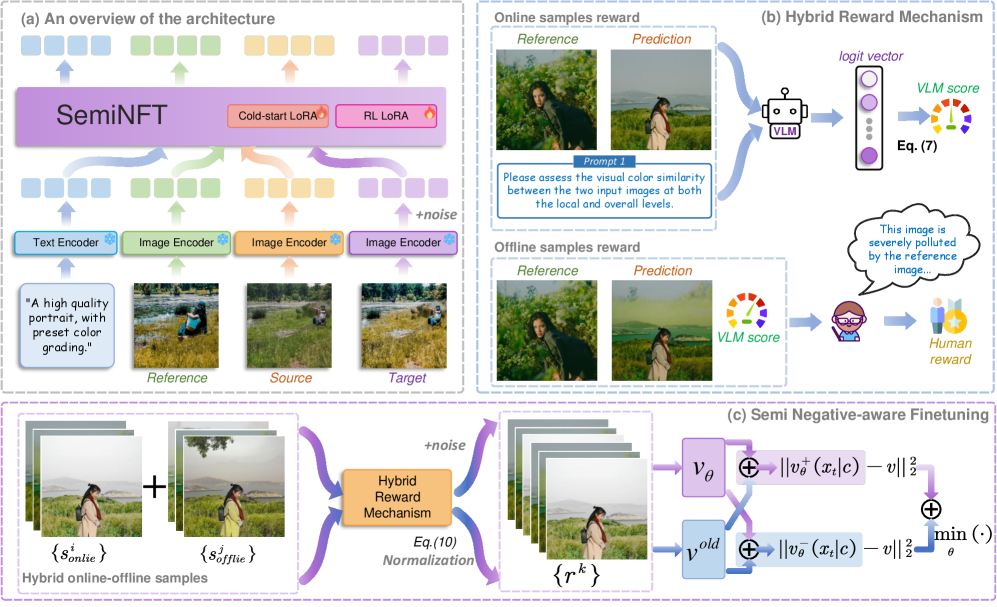
核心思路:论文的核心思路是模仿人类艺术家的学习过程,将色彩修饰任务分解为两个阶段:模仿学习和审美提升。首先通过模仿学习,使模型掌握基本的结构保持和颜色映射能力;然后通过强化学习,使模型学习人类的审美偏好,从而生成更符合人类审美的修饰结果。
技术框架:SemiNFT框架基于扩散Transformer (DiT) 架构,包含两个主要阶段:模仿学习阶段和强化学习阶段。在模仿学习阶段,模型使用配对的三元组数据进行训练,学习如何将参考图像的颜色风格迁移到源图像上,同时保持源图像的结构信息。在强化学习阶段,模型使用非配对的数据进行训练,通过与环境的交互,学习人类的审美偏好。
关键创新:论文的关键创新在于提出了混合在线-离线奖励机制,用于强化学习阶段。该机制结合了在线奖励和离线奖励,其中在线奖励用于鼓励模型探索新的审美风格,离线奖励用于防止模型忘记在模仿学习阶段学到的结构保持和颜色映射能力。这种混合奖励机制能够有效地平衡模型的探索和利用,从而提高模型的学习效率和性能。
关键设计:在强化学习阶段,论文使用了一种基于GAN的奖励函数,用于评估生成图像的审美质量。该奖励函数包括一个判别器网络,用于区分真实图像和生成图像,以及一个预训练的审美评分模型,用于评估生成图像的审美得分。此外,论文还设计了一种结构相似性损失函数,用于保持生成图像与源图像的结构相似性。
🖼️ 关键图片


📊 实验亮点
SemiNFT在标准预设迁移基准上超越了现有最先进的方法,并在零样本任务(如黑白照片着色和跨域预设迁移)中表现出卓越的性能。这些结果表明,SemiNFT不仅能够进行简单的统计匹配,而且能够理解图像的语义信息和人类的审美偏好,从而生成更符合人类审美的修饰结果。
🎯 应用场景
SemiNFT具有广泛的应用前景,可以应用于图像编辑、摄影后期处理、艺术创作等领域。它可以帮助非专业人士轻松地将照片修饰成具有专业水准的作品,也可以为专业人士提供更高效、更智能的修饰工具。此外,SemiNFT还可以应用于跨域图像风格迁移,例如将动漫风格的图像转换为照片风格的图像。
📄 摘要(原文)
Photorealistic color retouching plays a vital role in visual content creation, yet manual retouching remains inaccessible to non-experts due to its reliance on specialized expertise. Reference-based methods offer a promising alternative by transferring the preset color of a reference image to a source image. However, these approaches often operate as novice learners, performing global color mappings derived from pixel-level statistics, without a true understanding of semantic context or human aesthetics. To address this issue, we propose SemiNFT, a Diffusion Transformer (DiT)-based retouching framework that mirrors the trajectory of human artistic training: beginning with rigid imitation and evolving into intuitive creation. Specifically, SemiNFT is first taught with paired triplets to acquire basic structural preservation and color mapping skills, and then advanced to reinforcement learning (RL) on unpaired data to cultivate nuanced aesthetic perception. Crucially, during the RL stage, to prevent catastrophic forgetting of old skills, we design a hybrid online-offline reward mechanism that anchors aesthetic exploration with structural review. % experiments Extensive experiments show that SemiNFT not only outperforms state-of-the-art methods on standard preset transfer benchmarks but also demonstrates remarkable intelligence in zero-shot tasks, such as black-and-white photo colorization and cross-domain (anime-to-photo) preset transfer. These results confirm that SemiNFT transcends simple statistical matching and achieves a sophisticated level of aesthetic comprehension. Our project can be found at https://melanyyang.github.io/SemiNFT/.