FLAG-4D: Flow-Guided Local-Global Dual-Deformation Model for 4D Reconstruction
作者: Guan Yuan Tan, Ngoc Tuan Vu, Arghya Pal, Sailaja Rajanala, Raphael Phan C. -W., Mettu Srinivas, Chee-Ming Ting
分类: cs.CV, cs.GT
发布日期: 2026-02-09
💡 一句话要点
FLAG-4D:提出一种流动引导的局部-全局双重形变模型用于动态场景的4D重建。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 4D重建 动态场景 神经渲染 3D高斯 光流引导 双重形变网络 局部-全局建模
📋 核心要点
- 现有方法使用单一MLP建模时间形变,难以捕捉复杂运动和精细动态细节,尤其是在稀疏视角下。
- FLAG-4D提出双重形变网络,包含局部形变网络IDN和全局运动网络GMN,通过相互学习优化形变。
- FLAG-4D融合光流运动特征,并使用形变引导的注意力机制对齐流动信息,实验表明重建效果优于SOTA。
📝 摘要(中文)
FLAG-4D 是一种新颖的框架,通过重建 3D 高斯基元在空间和时间上的演变来生成动态场景的新视角。现有方法通常依赖于单个多层感知器 (MLP) 来建模时间形变,并且通常难以捕捉复杂的点运动和精细的动态细节,尤其是在稀疏输入视角下。FLAG-4D 采用双重形变网络来克服这一问题,该网络随时间动态地扭曲一组规范的 3D 高斯分布,使其变形为新的位置和各向异性形状。该双重形变网络由用于建模精细局部形变的瞬时形变网络 (IDN) 和用于捕捉长程动态的全局运动网络 (GMN) 组成,并通过相互学习进行优化。为了确保这些形变既准确又在时间上平滑,FLAG-4D 融合了来自预训练光流骨干网络的密集运动特征。我们融合来自相邻时间帧的这些运动线索,并使用形变引导的注意力机制将此流动信息与每个演变的 3D 高斯分布的当前状态对齐。大量实验表明,FLAG-4D 比最先进的方法实现了更高保真度、时间上更连贯的重建,并保留了更精细的细节。
🔬 方法详解
问题定义:论文旨在解决动态场景的4D重建问题,即从稀疏的视角和时间序列图像中,重建出高质量、时间一致的动态3D模型。现有方法,特别是基于MLP的方法,难以捕捉复杂和精细的动态细节,尤其是在视角稀疏的情况下,导致重建质量下降和时间不一致性。
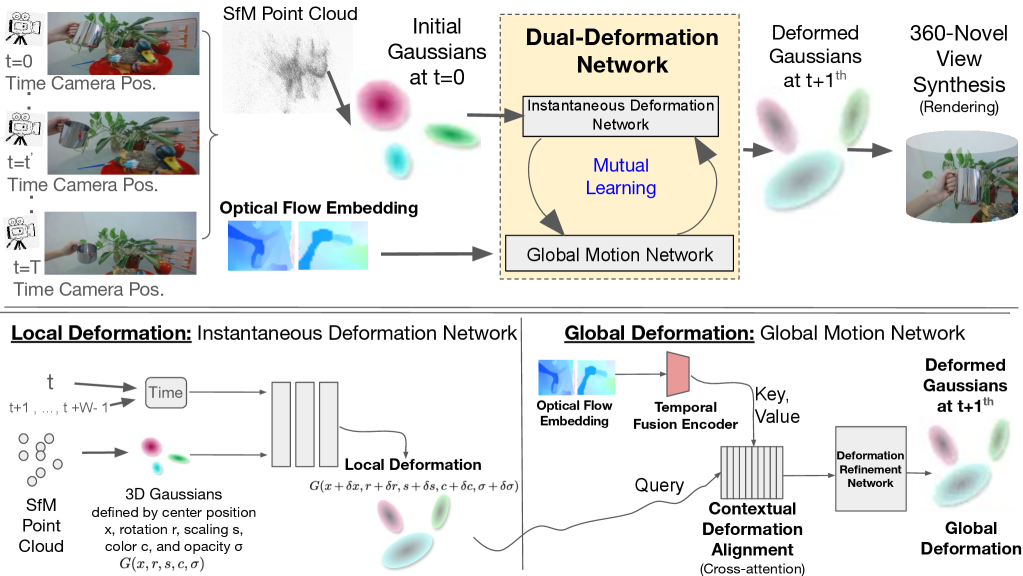
核心思路:论文的核心思路是采用双重形变网络,将形变分解为局部形变和全局运动两部分。局部形变网络(IDN)负责捕捉精细的、局部的形变细节,而全局运动网络(GMN)负责捕捉长程的、整体的运动趋势。通过相互学习,这两个网络可以协同工作,从而更准确地建模复杂的动态场景。此外,论文还利用光流信息作为运动先验,引导形变网络的学习。
技术框架:FLAG-4D的整体框架包含以下几个主要模块:1) 3D高斯基元表示:使用3D高斯分布作为场景的初始表示。2) 双重形变网络:包含IDN和GMN,分别建模局部形变和全局运动。3) 光流引导:利用预训练的光流网络提取运动特征,并将其融入形变网络的学习过程中。4) 形变引导的注意力机制:用于将光流信息与3D高斯分布的当前状态对齐。5) 渲染模块:将形变后的3D高斯分布渲染成图像。
关键创新:FLAG-4D的关键创新在于其双重形变网络的设计,以及光流引导的形变学习方法。双重形变网络能够更有效地捕捉复杂和精细的动态细节,而光流引导则可以提供运动先验,从而提高形变网络的学习效率和准确性。与现有方法相比,FLAG-4D能够生成更高质量、时间一致的动态3D模型。
关键设计:论文的关键设计包括:1) IDN和GMN的网络结构:具体采用何种网络结构(例如MLP、CNN等)以及如何进行参数化。2) 相互学习的损失函数:如何设计损失函数来促进IDN和GMN之间的协同学习。3) 光流特征的融合方式:如何将光流特征有效地融入形变网络的学习过程中,例如使用注意力机制。4) 形变引导的注意力机制的具体实现:如何设计注意力机制来将光流信息与3D高斯分布的当前状态对齐。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FLAG-4D 在动态场景重建任务上取得了显著的性能提升。与现有方法相比,FLAG-4D 能够生成更高质量、时间一致的动态3D模型,并保留了更精细的细节。具体性能数据(例如 PSNR、SSIM 等指标)和对比基线(例如 NeRF、D-NeRF 等)的具体数值未知,但摘要中提到 FLAG-4D 优于 state-of-the-art 方法。
🎯 应用场景
FLAG-4D 在动态场景建模、虚拟现实、增强现实、自动驾驶等领域具有广泛的应用前景。例如,可以用于创建逼真的虚拟人物、重建运动捕捉数据、生成动态场景的导航地图等。该研究的实际价值在于能够提高动态场景重建的质量和效率,为相关应用提供更可靠的数据基础。未来,该技术有望应用于更复杂的动态场景,例如人群场景、流体场景等。
📄 摘要(原文)
We introduce FLAG-4D, a novel framework for generating novel views of dynamic scenes by reconstructing how 3D Gaussian primitives evolve through space and time. Existing methods typically rely on a single Multilayer Perceptron (MLP) to model temporal deformations, and they often struggle to capture complex point motions and fine-grained dynamic details consistently over time, especially from sparse input views. Our approach, FLAG-4D, overcomes this by employing a dual-deformation network that dynamically warps a canonical set of 3D Gaussians over time into new positions and anisotropic shapes. This dual-deformation network consists of an Instantaneous Deformation Network (IDN) for modeling fine-grained, local deformations and a Global Motion Network (GMN) for capturing long-range dynamics, refined through mutual learning. To ensure these deformations are both accurate and temporally smooth, FLAG-4D incorporates dense motion features from a pretrained optical flow backbone. We fuse these motion cues from adjacent timeframes and use a deformation-guided attention mechanism to align this flow information with the current state of each evolving 3D Gaussian. Extensive experiments demonstrate that FLAG-4D achieves higher-fidelity and more temporally coherent reconstructions with finer detail preservation than state-of-the-art methods.