GeoFocus: Blending Efficient Global-to-Local Perception for Multimodal Geometry Problem-Solving
作者: Linger Deng, Yuliang Liu, Wenwen Yu, Zujia Zhang, Jianzhong Ju, Zhenbo Luo, Xiang Bai
分类: cs.CV
发布日期: 2026-02-09
🔗 代码/项目: GITHUB
💡 一句话要点
GeoFocus:融合全局到局部高效感知的多模态几何问题求解框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 几何问题求解 多模态学习 局部特征感知 全局拓扑编码 大型多模态模型
📋 核心要点
- 现有LMMs在几何问题求解中缺乏对关键局部几何关系的有效感知,限制了解题精度。
- GeoFocus通过关键局部感知器自动提取关键局部特征,并使用VertexLang进行高效的全局拓扑编码。
- 实验结果表明,GeoFocus在多个几何数据集上显著提升了问题求解的准确性和鲁棒性。
📝 摘要(中文)
大型多模态模型(LMMs)在几何问题求解方面仍然面临重大挑战,这不仅需要全局形状识别,还需要关注与几何理论相关的复杂局部关系。为了解决这个问题,我们提出了GeoFocus,这是一个新颖的框架,包含两个核心模块。1) 关键局部感知器(Critical Local Perceptor),它通过13个基于理论的感知模板自动识别和强调关键的局部结构(例如,角度、平行线、比较距离),与之前的方法相比,关键局部特征覆盖率提高了61%。2) VertexLang,一种紧凑的拓扑形式语言,通过顶点坐标和连通性关系编码全局图形。通过替换笨重的基于代码的编码,VertexLang将全局感知训练时间减少了20%,同时提高了拓扑识别精度。在Geo3K、GeoQA和FormalGeo7K中的评估表明,GeoFocus比领先的专用模型提高了4.7%的准确率,并在MATHVERSE中表现出更强的鲁棒性。
🔬 方法详解
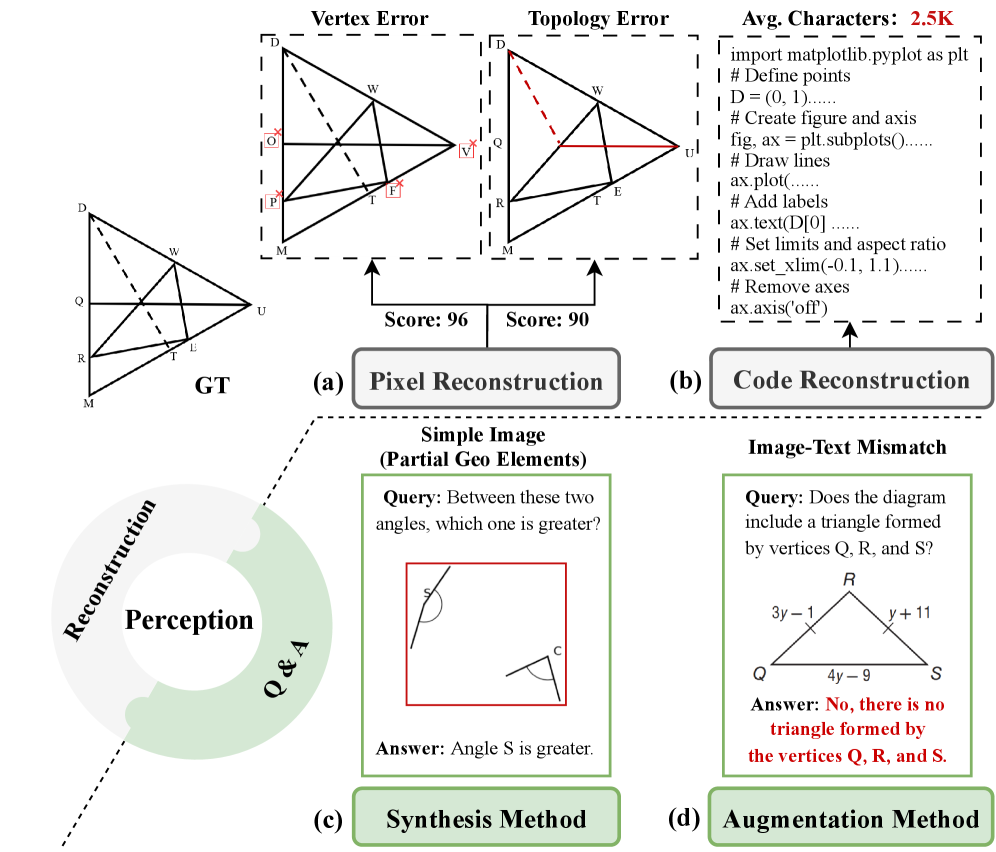
问题定义:几何问题求解需要模型具备全局形状理解和局部关系推理能力。现有方法在局部特征提取方面存在不足,难以有效捕捉关键的几何关系,例如角度、平行线等。此外,传统的全局编码方式通常较为冗余,效率较低。
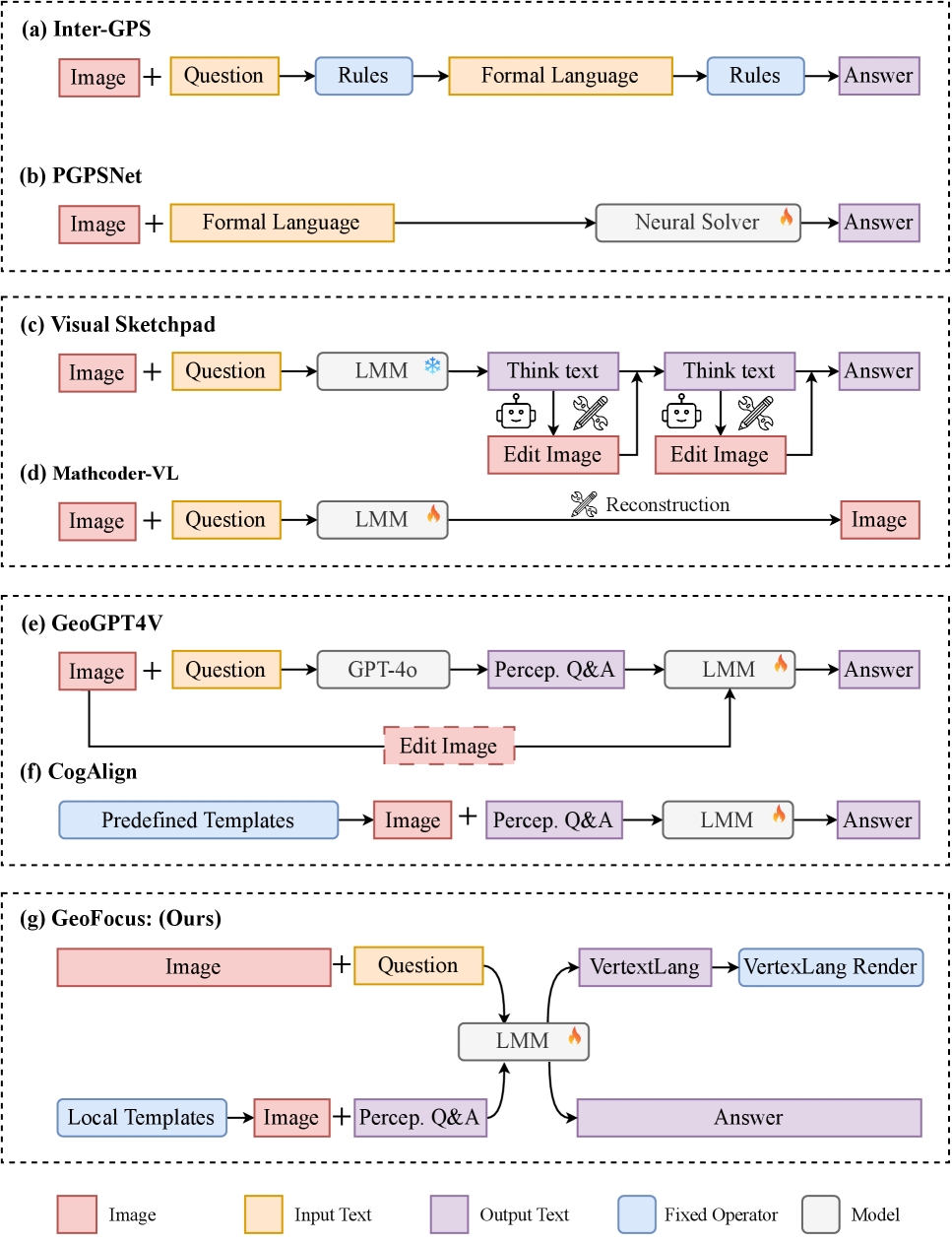
核心思路:GeoFocus的核心思路是融合全局到局部的感知,通过关键局部感知器增强对局部几何关系的理解,并使用紧凑的拓扑形式语言VertexLang进行全局编码,从而提高几何问题求解的准确性和效率。
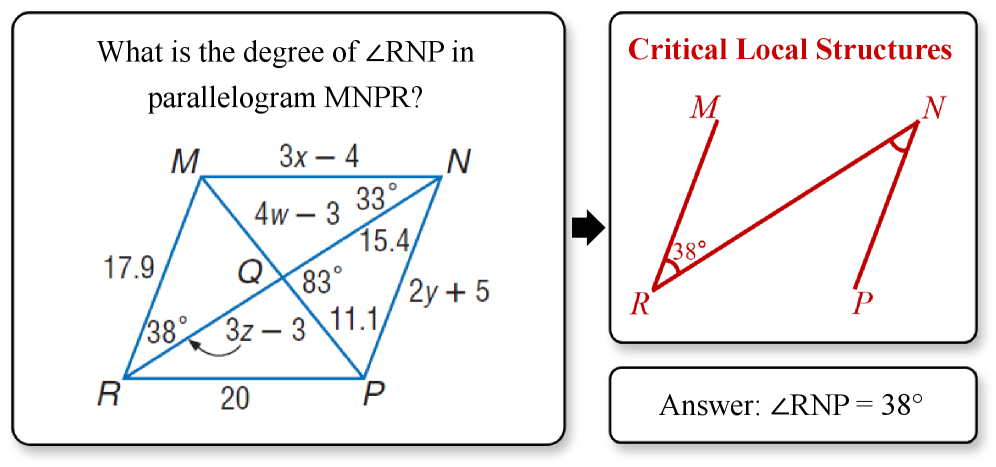
技术框架:GeoFocus框架包含两个主要模块:关键局部感知器(Critical Local Perceptor)和VertexLang。关键局部感知器利用13个基于几何理论的感知模板,自动识别和强调图像中的关键局部结构。VertexLang则通过顶点坐标和连通性关系对全局图形进行编码。整个流程包括图像输入、局部特征提取、全局拓扑编码和问题求解。
关键创新:GeoFocus的关键创新在于:1) 提出了关键局部感知器,能够自动识别和强调关键的局部几何关系,显著提升了局部特征的覆盖率。2) 提出了紧凑的拓扑形式语言VertexLang,替代了传统的冗余编码方式,提高了全局编码的效率和准确性。
关键设计:关键局部感知器使用13个基于几何理论的感知模板,这些模板针对不同的局部几何关系进行设计,例如角度、平行线、距离比较等。VertexLang使用顶点坐标和连通性关系对全局图形进行编码,避免了使用复杂的代码表示。训练过程中,可能使用了交叉熵损失函数等。
🖼️ 关键图片
📊 实验亮点
GeoFocus在Geo3K、GeoQA和FormalGeo7K数据集上取得了显著的性能提升,相比领先的专用模型提高了4.7%的准确率。此外,在MATHVERSE数据集上的实验表明,GeoFocus具有更强的鲁棒性,能够在不同的视觉条件下保持较高的准确率。关键局部特征覆盖率相比之前的方法提高了61%,全局感知训练时间减少了20%。
🎯 应用场景
GeoFocus在教育领域具有广泛的应用前景,可以用于辅助学生学习几何知识,自动解答几何问题,并提供个性化的学习指导。此外,该技术还可以应用于计算机辅助设计、机器人导航等领域,提高系统的智能化水平和问题解决能力。
📄 摘要(原文)
Geometry problem-solving remains a significant challenge for Large Multimodal Models (LMMs), requiring not only global shape recognition but also attention to intricate local relationships related to geometric theory. To address this, we propose GeoFocus, a novel framework comprising two core modules. 1) Critical Local Perceptor, which automatically identifies and emphasizes critical local structure (e.g., angles, parallel lines, comparative distances) through thirteen theory-based perception templates, boosting critical local feature coverage by 61% compared to previous methods. 2) VertexLang, a compact topology formal language, encodes global figures through vertex coordinates and connectivity relations. By replacing bulky code-based encodings, VertexLang reduces global perception training time by 20% while improving topology recognition accuracy. When evaluated in Geo3K, GeoQA, and FormalGeo7K, GeoFocus achieves a 4.7% accuracy improvement over leading specialized models and demonstrates superior robustness in MATHVERSE under diverse visual conditions. Project Page -- https://github.com/dle666/GeoFocus