Are Vision Foundation Models Foundational for Electron Microscopy Image Segmentation?
作者: Caterina Fuster-Barceló, Virginie Uhlmann
分类: cs.CV
发布日期: 2026-02-09
💡 一句话要点
研究视觉基础模型在电子显微镜图像分割中的适用性,揭示跨数据集泛化难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉基础模型 电子显微镜图像分割 迁移学习 域适应 参数高效微调
📋 核心要点
- 现有视觉基础模型在生物医学图像分析中应用受限,缺乏对异构显微镜图像数据集泛化能力的深入研究。
- 通过冻结骨干网络和参数高效微调(LoRA)两种策略,评估视觉基础模型在电子显微镜图像分割中的迁移能力。
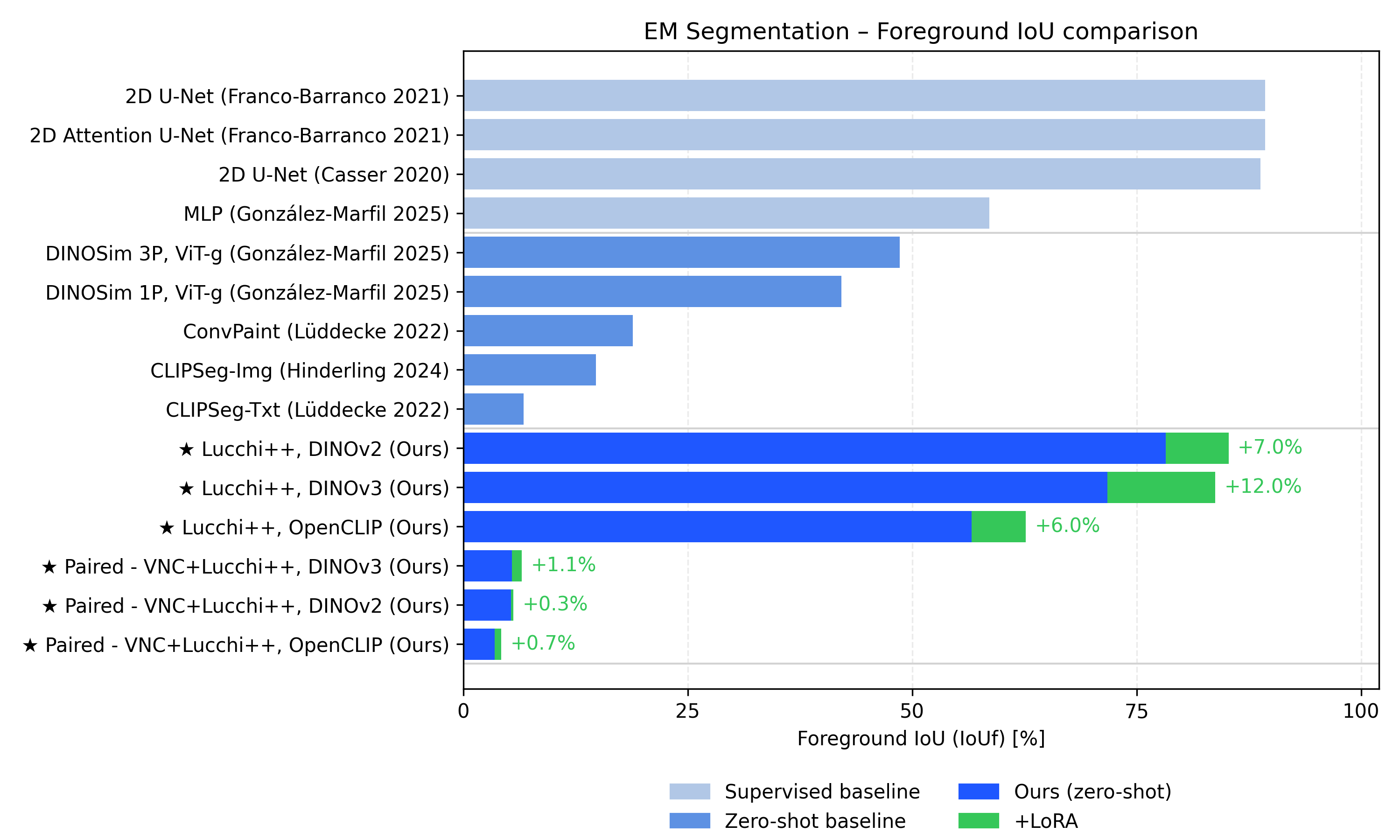
- 实验表明,视觉基础模型在单数据集上表现良好,但跨数据集泛化能力差,域差异是主要瓶颈。
📝 摘要(中文)
尽管视觉基础模型(VFMs)越来越多地被用于生物医学图像分析,但其潜在表示是否足够通用,以支持在异构显微镜图像数据集上的有效迁移和重用仍不清楚。本文针对电子显微镜(EM)图像中的线粒体分割问题,使用两个流行的公共EM数据集(Lucchi++和VNC)以及三个具有代表性的VFMs(DINOv2、DINOv3和OpenCLIP)来研究这个问题。我们评估了两种实用的模型适应方案:冻结骨干设置,其中仅在VFM之上训练轻量级分割头;以及通过低秩适应(LoRA)进行参数高效微调(PEFT),其中VFM以有针对性的方式微调到特定数据集。结果表明,在单个EM数据集上训练可以产生良好的分割性能(以前景IoU量化),并且LoRA始终提高域内性能。相反,在多个EM数据集上训练会导致所有模型的性能严重下降,PEFT仅带来边际收益。通过各种技术(PCA、Fréchet Dinov2距离和线性探针)对潜在表示空间的探索揭示了两个EM数据集之间明显且持久的域不匹配,这与观察到的配对训练失败一致。这些结果表明,虽然VFMs可以在轻量级适应下为单个域内的EM分割提供有竞争力的结果,但当前的PEFT策略不足以在没有额外域对齐机制的情况下获得跨异构EM数据集的单个鲁棒模型。
🔬 方法详解
问题定义:论文旨在解决视觉基础模型(VFMs)在电子显微镜(EM)图像分割任务中,跨不同数据集泛化能力不足的问题。现有方法在特定数据集上表现良好,但在应用于新的、略有不同的EM数据集时,性能会显著下降。这种域差异限制了VFMs在实际生物医学研究中的应用。
核心思路:论文的核心思路是评估VFMs在EM图像分割任务中的迁移学习能力,并探究导致跨数据集泛化失败的原因。通过分析VFMs的潜在表示空间,揭示不同EM数据集之间的域差异,从而为改进VFMs的跨域泛化能力提供指导。
技术框架:论文采用迁移学习框架,使用预训练的VFMs(DINOv2、DINOv3和OpenCLIP)作为骨干网络,并在此基础上添加分割头。研究了两种模型适应策略: 1. 冻结骨干网络:只训练分割头,保持VFM的参数不变。 2. 参数高效微调(PEFT):使用LoRA技术,只微调VFM中的少量参数。
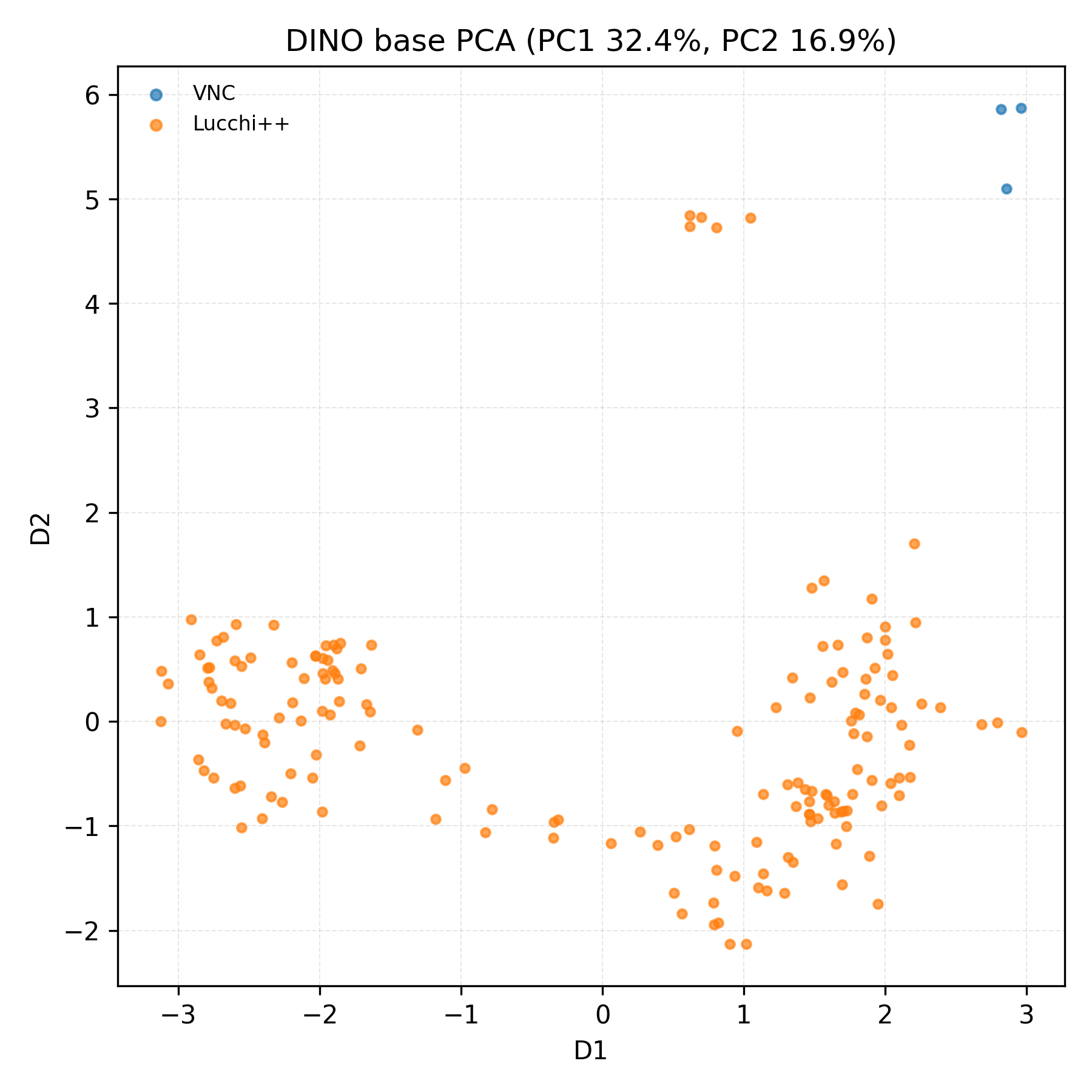
关键创新:论文的关键创新在于对VFMs在EM图像分割任务中的跨数据集泛化能力进行了系统性的评估和分析。通过PCA、Fréchet Dinov2距离和线性探针等技术,深入分析了VFMs的潜在表示空间,揭示了不同EM数据集之间的域差异是导致泛化失败的主要原因。此外,论文还评估了LoRA等PEFT技术在缓解域差异方面的效果。
关键设计: 1. 数据集:使用了两个公共EM数据集(Lucchi++和VNC),用于评估模型的泛化能力。 2. 评估指标:使用前景IoU(Intersection-over-Union)作为分割性能的评估指标。 3. LoRA配置:LoRA的秩(rank)设置为8,缩放因子设置为16,优化器使用AdamW,学习率设置为1e-4。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在单个EM数据集上训练的视觉基础模型可以获得良好的分割性能,LoRA微调可以进一步提高域内性能。然而,在多个EM数据集上进行联合训练会导致性能显著下降,即使使用LoRA也无法有效缓解。通过分析潜在表示空间,发现Lucchi++和VNC数据集之间存在明显的域差异,这解释了跨数据集泛化失败的原因。Fréchet Dinov2距离等指标量化了这种域差异。
🎯 应用场景
该研究成果可应用于生物医学图像分析领域,特别是电子显微镜图像的自动分割。通过理解视觉基础模型在不同数据集上的泛化能力,可以开发更鲁棒的分割算法,加速生物医学研究进程,例如细胞器定位、神经元追踪等。未来的研究可以集中在如何利用域适应技术来提高视觉基础模型在异构数据集上的性能。
📄 摘要(原文)
Although vision foundation models (VFMs) are increasingly reused for biomedical image analysis, it remains unclear whether the latent representations they provide are general enough to support effective transfer and reuse across heterogeneous microscopy image datasets. Here, we study this question for the problem of mitochondria segmentation in electron microscopy (EM) images, using two popular public EM datasets (Lucchi++ and VNC) and three recent representative VFMs (DINOv2, DINOv3, and OpenCLIP). We evaluate two practical model adaptation regimes: a frozen-backbone setting in which only a lightweight segmentation head is trained on top of the VFM, and parameter-efficient fine-tuning (PEFT) via Low-Rank Adaptation (LoRA) in which the VFM is fine-tuned in a targeted manner to a specific dataset. Across all backbones, we observe that training on a single EM dataset yields good segmentation performance (quantified as foreground Intersection-over-Union), and that LoRA consistently improves in-domain performance. In contrast, training on multiple EM datasets leads to severe performance degradation for all models considered, with only marginal gains from PEFT. Exploration of the latent representation space through various techniques (PCA, Fréchet Dinov2 distance, and linear probes) reveals a pronounced and persistent domain mismatch between the two considered EM datasets in spite of their visual similarity, which is consistent with the observed failure of paired training. These results suggest that, while VFMs can deliver competitive results for EM segmentation within a single domain under lightweight adaptation, current PEFT strategies are insufficient to obtain a single robust model across heterogeneous EM datasets without additional domain-alignment mechanisms.