TriC-Motion: Tri-Domain Causal Modeling Grounded Text-to-Motion Generation
作者: Yiyang Cao, Yunze Deng, Ziyu Lin, Bin Feng, Xinggang Wang, Wenyu Liu, Dandan Zheng, Jingdong Chen
分类: cs.CV
发布日期: 2026-02-09
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出TriC-Motion,融合时空频域信息并进行因果干预的文本到动作生成框架
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 文本到动作生成 扩散模型 因果干预 时空频域建模 运动解耦 三域融合 HumanML3D
📋 核心要点
- 现有文本到动作生成方法缺乏对空间、时间和频率域的联合优化,限制了模型对多域信息的利用。
- TriC-Motion通过融合时空频域信息,并引入因果干预,解耦运动相关和无关特征,提升生成质量。
- 实验表明,TriC-Motion在HumanML3D数据集上取得了显著的性能提升,R@1指标达到0.612。
📝 摘要(中文)
本文提出了一种名为TriC-Motion的三域因果文本到动作生成框架,旨在解决当前文本到动作生成方法中缺乏对空间、时间和频率域进行联合优化的问题。现有方法主要集中在时空建模或独立的频域分析,无法充分利用所有域的信息,导致生成质量欠佳。此外,运动生成框架中,噪声引起的与运动无关的线索常常与对生成有积极贡献的特征纠缠在一起,导致运动失真。TriC-Motion基于扩散模型,集成了空间-时间-频率域建模与因果干预。该框架包含三个核心建模模块:时间运动编码、空间拓扑建模和混合频率分析。通过分数引导的三域融合模块整合来自三个域的宝贵信息,确保时间一致性、空间拓扑、运动趋势和动态。此外,基于因果关系的逆事实运动解耦器用于暴露与运动无关的线索,消除噪声,从而解耦每个域的真实建模贡献,实现卓越的生成效果。实验结果表明,TriC-Motion优于现有技术,在HumanML3D数据集上实现了0.612的R@1。
🔬 方法详解
问题定义:文本到动作生成旨在根据给定的文本描述生成逼真的动作序列。现有方法主要集中在时空域建模或独立的频域分析,缺乏一个统一的框架来联合优化这三个域的信息。此外,噪声等因素导致的与运动无关的线索会与有效特征纠缠,导致生成的动作失真。
核心思路:TriC-Motion的核心思路是同时在空间、时间和频率三个域对运动进行建模,并利用因果干预来解耦运动相关和无关的特征。通过在多个域中提取信息,模型可以更全面地理解运动的本质,而因果干预则有助于消除噪声的影响,从而生成更准确、更逼真的动作。
技术框架:TriC-Motion是一个基于扩散模型的框架,主要包含以下几个模块: 1. Temporal Motion Encoding (TME):用于捕捉运动的时间动态信息。 2. Spatial Topology Modeling (STM):用于建模运动的空间拓扑结构。 3. Hybrid Frequency Analysis (HFA):用于分析运动的频率特征。 4. Score-guided Tri-domain Fusion (STF):用于融合来自三个域的信息,并利用分数函数引导生成过程。 5. Causality-based Counterfactual Motion Disentangler (CCMD):用于解耦运动相关和无关的特征,消除噪声的影响。
关键创新:TriC-Motion的关键创新在于: 1. 三域联合建模:首次将空间、时间和频率域的信息融合到一个统一的框架中。 2. 因果干预:利用因果推理来解耦运动相关和无关的特征,提高生成质量。 与现有方法相比,TriC-Motion能够更全面地理解运动的本质,并消除噪声的影响,从而生成更准确、更逼真的动作。
关键设计: 1. 扩散模型:使用扩散模型作为生成框架,能够生成高质量的动作序列。 2. 分数函数引导:利用分数函数引导生成过程,确保生成的动作与文本描述一致。 3. 逆事实推理:通过逆事实推理来识别和消除与运动无关的特征。
🖼️ 关键图片
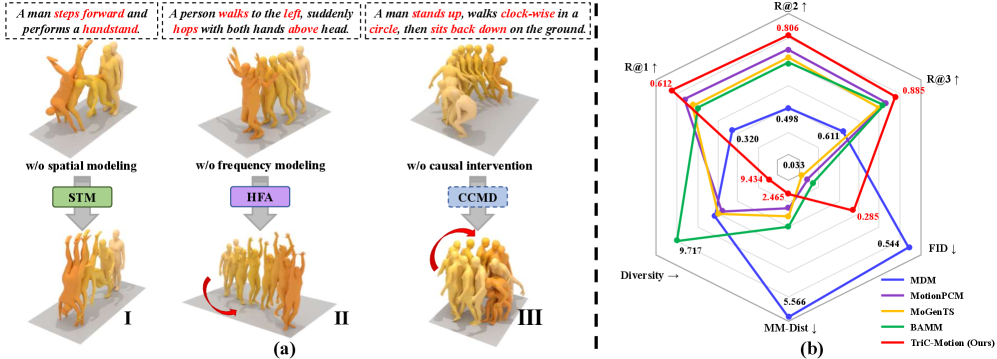

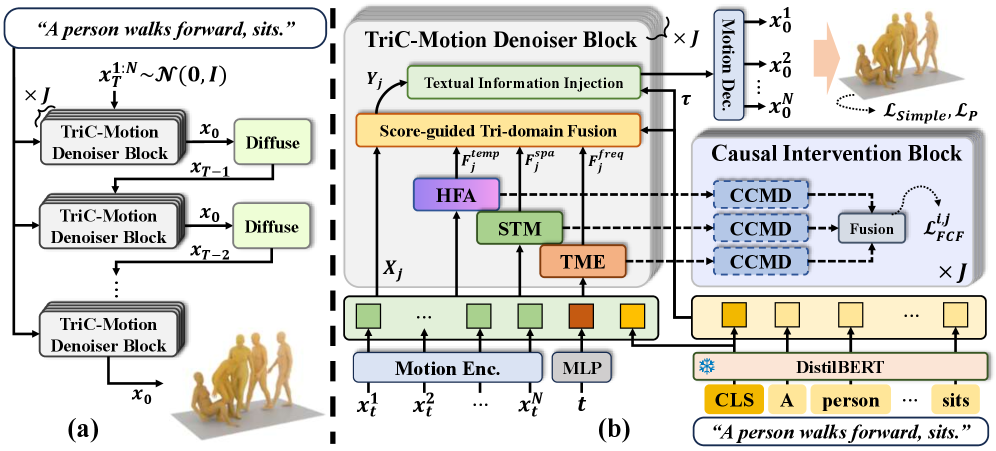
📊 实验亮点
TriC-Motion在HumanML3D数据集上取得了显著的性能提升,R@1指标达到了0.612,超过了现有最先进的方法。这表明TriC-Motion能够生成更高质量、更逼真、更符合文本描述的动作序列。实验结果验证了三域联合建模和因果干预的有效性。
🎯 应用场景
TriC-Motion在人机交互、虚拟现实、游戏开发、动画制作等领域具有广泛的应用前景。它可以用于生成逼真的人体动作,例如舞蹈、运动等,从而提升用户体验。此外,该技术还可以用于训练机器人,使其能够更好地理解和执行人类的指令。
📄 摘要(原文)
Text-to-motion generation, a rapidly evolving field in computer vision, aims to produce realistic and text-aligned motion sequences. Current methods primarily focus on spatial-temporal modeling or independent frequency domain analysis, lacking a unified framework for joint optimization across spatial, temporal, and frequency domains. This limitation hinders the model's ability to leverage information from all domains simultaneously, leading to suboptimal generation quality. Additionally, in motion generation frameworks, motion-irrelevant cues caused by noise are often entangled with features that contribute positively to generation, thereby leading to motion distortion. To address these issues, we propose Tri-Domain Causal Text-to-Motion Generation (TriC-Motion), a novel diffusion-based framework integrating spatial-temporal-frequency-domain modeling with causal intervention. TriC-Motion includes three core modeling modules for domain-specific modeling, namely Temporal Motion Encoding, Spatial Topology Modeling, and Hybrid Frequency Analysis. After comprehensive modeling, a Score-guided Tri-domain Fusion module integrates valuable information from the triple domains, simultaneously ensuring temporal consistency, spatial topology, motion trends, and dynamics. Moreover, the Causality-based Counterfactual Motion Disentangler is meticulously designed to expose motion-irrelevant cues to eliminate noise, disentangling the real modeling contributions of each domain for superior generation. Extensive experimental results validate that TriC-Motion achieves superior performance compared to state-of-the-art methods, attaining an outstanding R@1 of 0.612 on the HumanML3D dataset. These results demonstrate its capability to generate high-fidelity, coherent, diverse, and text-aligned motion sequences. Code is available at: https://caoyiyang1105.github.io/TriC-Motion/.