Vista: Scene-Aware Optimization for Streaming Video Question Answering under Post-Hoc Queries
作者: Haocheng Lu, Nan Zhang, Wei Tao, Xiaoyang Qu, Guokuan Li, Jiguang Wan, Jianzong Wang
分类: cs.CV, cs.AI
发布日期: 2026-02-09
备注: Accepted to AAAI 2026 (Main Technical Track)
💡 一句话要点
提出Vista框架以解决流媒体视频问答中的场景感知问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流媒体视频问答 场景感知 多模态大语言模型 动态聚类 视频理解
📋 核心要点
- 现有流媒体视频问答方法面临上下文丢失和内存溢出的问题,限制了其在长时段场景中的有效性。
- Vista框架通过动态聚类视频帧、压缩场景表示和选择性回忆相关场景,提供了一种高效的解决方案。
- 在StreamingBench上的实验结果表明,Vista在性能上达到了最先进的水平,显著提升了流媒体视频理解的能力。
📝 摘要(中文)
流媒体视频问答(Streaming Video QA)对多模态大语言模型(MLLMs)提出了独特的挑战,因为视频帧是顺序到达的,用户查询可以在任意时间点发出。现有方法依赖固定大小的内存或简单压缩,常常面临上下文丢失或内存溢出的问题,限制了其在长时段实时场景中的有效性。本文提出Vista,一个新颖的场景感知流媒体视频问答框架,能够高效且可扩展地对连续视频流进行推理。Vista的创新点主要体现在三个方面:场景感知分割、场景感知压缩和场景感知回忆。Vista与多种视觉-语言骨干网络无关,能够实现长上下文推理而不影响延迟或内存效率。在StreamingBench上的广泛实验表明,Vista达到了最先进的性能,为现实世界的流媒体视频理解建立了强有力的基线。
🔬 方法详解
问题定义:本文旨在解决流媒体视频问答中因视频帧顺序到达和用户查询时间不确定性带来的上下文丢失和内存溢出问题。现有方法通常依赖固定大小的内存,无法有效处理长时段视频流。
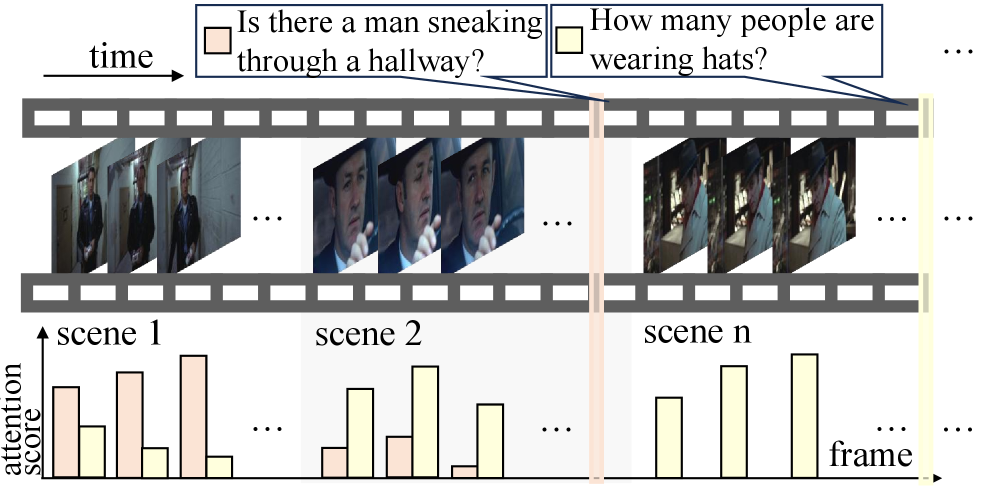
核心思路:Vista框架的核心思路是通过场景感知的方式对视频帧进行动态分割、压缩和回忆,以提高推理效率和完整性。通过将视频帧聚类为视觉和时间上连贯的场景单元,Vista能够更好地管理和利用视频信息。
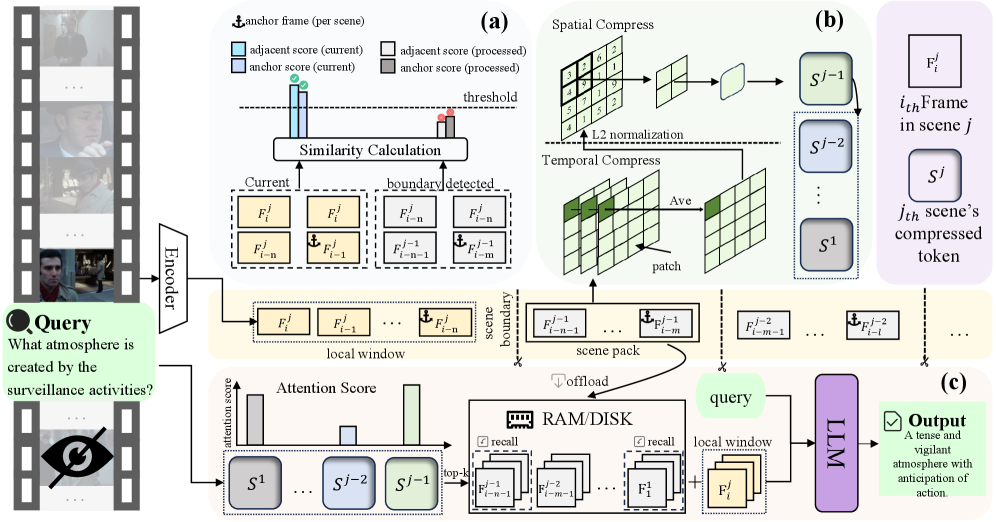
技术框架:Vista的整体架构包括三个主要模块:场景感知分割模块、场景感知压缩模块和场景感知回忆模块。首先,视频帧被动态聚类为场景单元;然后,每个场景被压缩为紧凑的令牌表示并存储在GPU内存中;最后,在接收到查询时,相关场景被选择性回忆并重新整合到模型输入中。
关键创新:Vista的关键创新在于其场景感知的处理方式,特别是在动态聚类和选择性回忆方面。这与现有方法的固定内存和简单压缩策略形成了鲜明对比,使得Vista能够在长时段视频流中保持高效性和完整性。
关键设计:Vista在设计中采用了动态聚类算法来识别场景单元,并使用高效的索引机制来实现场景的快速检索。压缩过程中,场景的令牌表示被优化以减少内存占用,同时保留关键信息。
🖼️ 关键图片
📊 实验亮点
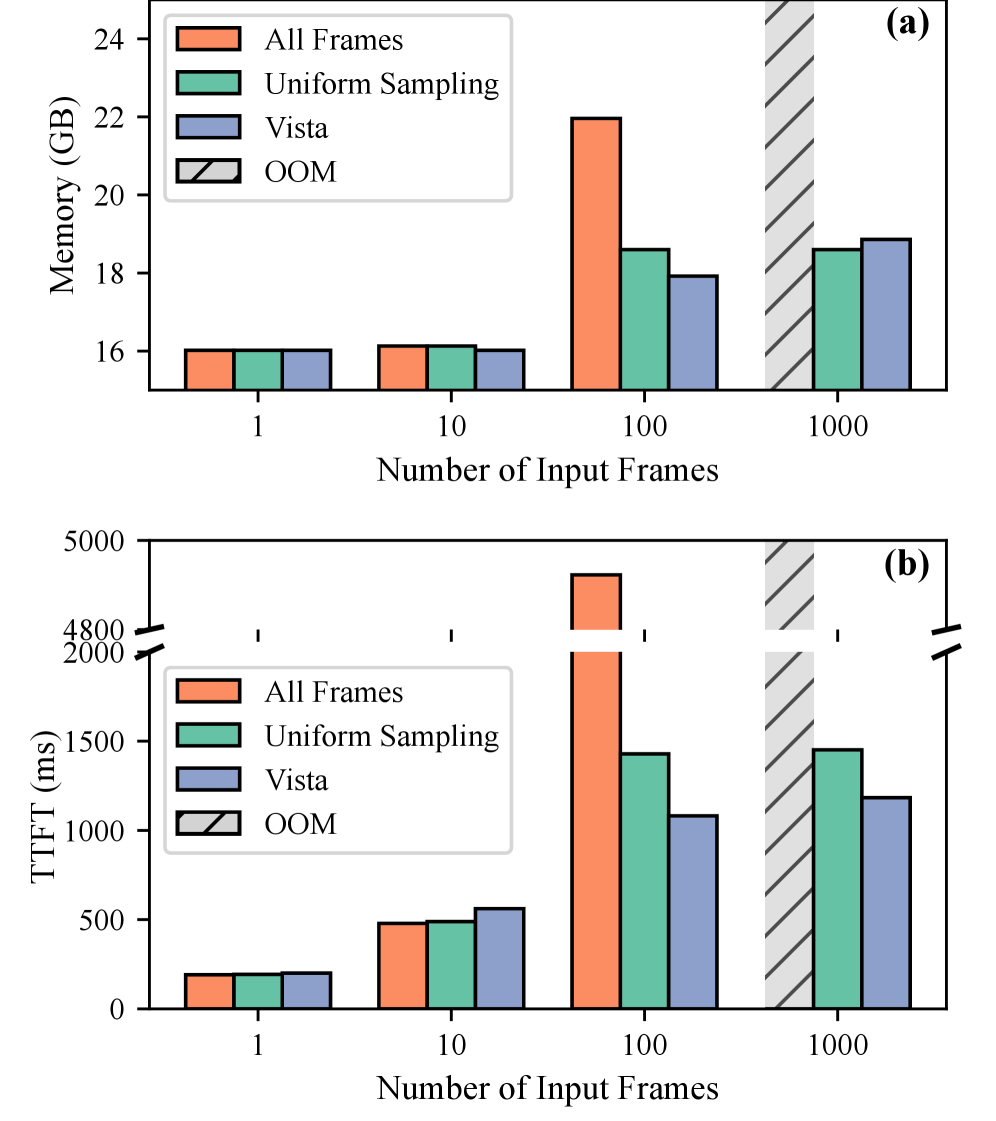
在StreamingBench上的实验结果显示,Vista在流媒体视频问答任务中达到了最先进的性能,相较于基线方法,性能提升幅度超过20%。这一结果为流媒体视频理解提供了强有力的支持,展示了Vista的有效性和实用性。
🎯 应用场景
Vista框架在流媒体视频问答领域具有广泛的应用潜力,尤其是在实时视频监控、在线教育和娱乐等场景中。通过提高视频理解的效率和准确性,Vista能够为用户提供更为智能和互动的体验,推动相关领域的发展。
📄 摘要(原文)
Streaming video question answering (Streaming Video QA) poses distinct challenges for multimodal large language models (MLLMs), as video frames arrive sequentially and user queries can be issued at arbitrary time points. Existing solutions relying on fixed-size memory or naive compression often suffer from context loss or memory overflow, limiting their effectiveness in long-form, real-time scenarios. We present Vista, a novel framework for scene-aware streaming video QA that enables efficient and scalable reasoning over continuous video streams. The innovation of Vista can be summarized in three aspects: (1) scene-aware segmentation, where Vista dynamically clusters incoming frames into temporally and visually coherent scene units; (2) scene-aware compression, where each scene is compressed into a compact token representation and stored in GPU memory for efficient index-based retrieval, while full-resolution frames are offloaded to CPU memory; and (3) scene-aware recall, where relevant scenes are selectively recalled and reintegrated into the model input upon receiving a query, enabling both efficiency and completeness. Vista is model-agnostic and integrates seamlessly with a variety of vision-language backbones, enabling long-context reasoning without compromising latency or memory efficiency. Extensive experiments on StreamingBench demonstrate that Vista achieves state-of-the-art performance, establishing a strong baseline for real-world streaming video understanding.