Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
作者: Yuhao Dong, Shulin Tian, Shuai Liu, Shuangrui Ding, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Jiaqi Wang, Ziwei Liu
分类: cs.CV
发布日期: 2026-02-09
💡 一句话要点
提出Demo-ICL,用于程序性视频知识获取的上下文学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 视频理解 多模态学习 程序性知识 大型语言模型
📋 核心要点
- 现有视频理解基准侧重于模型内部知识,缺乏对模型从少量示例中学习新知识能力的评估。
- 提出Demo-ICL任务和基准,利用文本和视频演示,评估模型在上下文中学习程序性知识的能力。
- 开发Demo-ICL模型,通过视频监督微调和信息辅助直接偏好优化,提升模型上下文学习能力。
📝 摘要(中文)
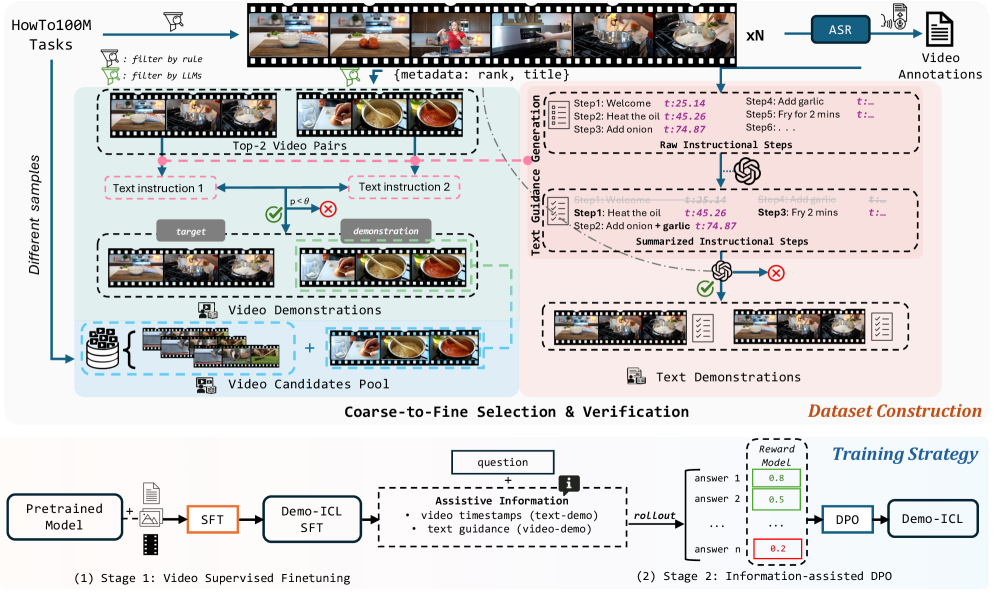
本文提出了一种新的任务:演示驱动的视频上下文学习(Demo-driven Video In-Context Learning),旨在评估模型从少量示例中学习和适应动态、新颖上下文的能力,以弥补现有视频基准主要评估模型静态内部知识的不足。为此,构建了一个具有挑战性的基准测试Demo-ICL-Bench,该基准测试由1200个带有相关问题的YouTube教学视频构成,并从中提取两种类型的演示:(i)总结视频字幕作为文本演示;(ii)相应的教学视频作为视频演示。为了有效应对这一新挑战,开发了一个名为Demo-ICL的多模态大型语言模型(MLLM),它采用两阶段训练策略:视频监督微调和信息辅助直接偏好优化,共同增强模型从上下文示例中学习的能力。大量实验表明,Demo-ICL-Bench具有挑战性,Demo-ICL有效,并揭示了未来的研究方向。
🔬 方法详解
问题定义:现有视频理解模型主要依赖于静态的内部知识,缺乏从少量演示视频中快速学习新程序性知识的能力。现有的视频基准测试也未能充分评估模型在动态上下文中的学习能力。因此,需要一种新的方法来评估和提升模型在上下文中学习程序性视频知识的能力。
核心思路:本文的核心思路是利用上下文学习(In-Context Learning, ICL)的思想,让模型通过观看少量的演示视频(demonstration)来学习新的程序性知识,并回答关于目标视频的问题。通过提供文本摘要和视频片段作为演示,模型可以更好地理解目标视频的内容和步骤。
技术框架:Demo-ICL的整体框架包含以下几个主要部分:1) Demo-ICL-Bench基准数据集,包含教学视频和相关问题;2) 文本演示和视频演示的构建方法,用于提供上下文信息;3) Demo-ICL模型,一个经过特殊训练的多模态大型语言模型。Demo-ICL模型的训练分为两个阶段:首先进行视频监督微调,然后进行信息辅助直接偏好优化。
关键创新:该论文的关键创新在于提出了Demo-driven Video In-Context Learning任务和Demo-ICL-Bench基准,并设计了Demo-ICL模型来解决该任务。与传统的视频理解方法不同,Demo-ICL侧重于评估模型从少量演示中学习新知识的能力,而不是依赖于预先存在的内部知识。信息辅助直接偏好优化是另一个创新点,它能够更好地利用上下文信息来提升模型的性能。
关键设计:Demo-ICL模型基于多模态大型语言模型,具体架构未知。视频监督微调阶段使用视频数据来训练模型,使其能够更好地理解视频内容。信息辅助直接偏好优化阶段使用上下文信息来指导模型的学习,例如,可以使用强化学习来优化模型的回答质量。具体的损失函数和网络结构等技术细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了Demo-ICL-Bench的挑战性,并证明了Demo-ICL模型的有效性。实验结果表明,Demo-ICL模型在Demo-ICL-Bench上取得了显著的性能提升,表明其具有较强的上下文学习能力。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于智能助手、在线教育、机器人操作等领域。例如,智能助手可以根据用户提供的少量演示视频,学习新的操作步骤,并指导用户完成任务。在线教育平台可以利用该技术,为学生提供个性化的学习体验。机器人可以根据演示视频,学习新的操作技能,从而更好地完成各种任务。
📄 摘要(原文)
Despite the growing video understanding capabilities of recent Multimodal Large Language Models (MLLMs), existing video benchmarks primarily assess understanding based on models' static, internal knowledge, rather than their ability to learn and adapt from dynamic, novel contexts from few examples. To bridge this gap, we present Demo-driven Video In-Context Learning, a novel task focused on learning from in-context demonstrations to answer questions about the target videos. Alongside this, we propose Demo-ICL-Bench, a challenging benchmark designed to evaluate demo-driven video in-context learning capabilities. Demo-ICL-Bench is constructed from 1200 instructional YouTube videos with associated questions, from which two types of demonstrations are derived: (i) summarizing video subtitles for text demonstration; and (ii) corresponding instructional videos as video demonstrations. To effectively tackle this new challenge, we develop Demo-ICL, an MLLM with a two-stage training strategy: video-supervised fine-tuning and information-assisted direct preference optimization, jointly enhancing the model's ability to learn from in-context examples. Extensive experiments with state-of-the-art MLLMs confirm the difficulty of Demo-ICL-Bench, demonstrate the effectiveness of Demo-ICL, and thereby unveil future research directions.